OpenAI, l'entreprise derrière ChatGPT, a signé un contrat significatif de 11,9 milliards de dollars avec CoreWeave, fournisseur américain d'infrastructures cloud spécialis&...
OpenAI conclut un accord stratégique de 11,9 milliards de dollars avec CoreWeave
Aujourd’hui, alors que près de 90 % des données organisationnelles sont stockées sous forme de documents numériques, leur exploitation efficace est un enjeu strat&eac...
Mistral AI lance Mistral OCR : une nouvelle référence en compréhension documentaire
L'ESN française Sopra Steria, acteur majeur de la tech en Europe, et la licorne Mistral AI ont annoncé hier un partenariat stratégique visant à offrir des solutions...
Sopra Steria et Mistral AI : une alliance stratégique pour une IA souveraine en Europe
Donald Trump, président des États-Unis, a récemment dévoilé un projet titanesque baptisé « Stargate ». Ce programme, qui mobilise les plus grands noms de la technologie mondiale, promet de transformer le paysage de l’intelligence artificielle (IA) avec un investissement colossal de 500 milliards de dollars sur quatre ans. Voici les détails d’une initiative qui réunit innovation, ambition et géopolitique.
Une coalition inédite pour dominer l’IA
Stargate repose sur une alliance stratégique entre trois acteurs majeurs : OpenAI, Oracle et SoftBank. Ces entreprises unissent leurs forces pour construire la plus grande infrastructure d’IA au monde. Masayoshi Son, PDG de SoftBank, sera à la tête de cette coentreprise. Le projet démarre avec un investissement initial de 100 milliards de dollars, et prévoit d’étendre cette somme à 500 milliards dans les prochaines années. Nvidia, le géant des semi-conducteurs, joue également un rôle clé dans la fourniture des technologies nécessaires.
Une infrastructure massive au service de l’innovation
Le projet a déjà commencé avec la construction de data centers près d’Abilene, au Texas. Selon Larry Ellison, cofondateur d’Oracle, 10 bâtiments s’élèvent actuellement, et ce nombre pourrait doubler dans les prochaines phases. Chaque centre, équipé des dernières technologies Nvidia, couvrira environ 50 000 mètres carrés. Ces infrastructures fourniront des capacités de calcul sans précédent pour l’IA générative et d’autres applications avancées.
Cette initiative devrait créer plus de 100 000 emplois aux États-Unis et renforcer la compétitivité du pays face à la Chine. Donald Trump a souligné l’importance de cet investissement pour éviter que les technologies stratégiques ne soient dominées par des pays concurrents.
Un impact géopolitique et économique majeur
Outre son ampleur économique, Stargate s’inscrit dans une stratégie plus large de réindustrialisation et de souveraineté technologique américaine. « Cet argent aurait pu aller à la Chine. Maintenant, il renforce notre leadership », a déclaré le président américain.
Cette annonce intervient dans un contexte de compétition accrue pour la domination technologique mondiale. Avec Stargate, les États-Unis affichent leur volonté de rester en tête dans la course à l’IA, grâce à une collaboration public-privé sans précédent.
Une ambition à la hauteur des défis
Le projet Stargate ne se limite pas à la construction d’infrastructures physiques. Il s’agit également de soutenir la recherche et d’accélérer l’émergence d’applications révolutionnaires, comme les diagnostics médicaux précoces et les vaccins personnalisés. Pour OpenAI, ce partenariat représente une opportunité unique d’atteindre son objectif ultime : développer une intelligence artificielle générale.
L’AFP et Mistral AI annoncent la signature d’un partenariat pluriannuel qui permettra à l’assistant conversationnel de ce dernier, “le Chat”, d’exploiter l’ensemble des dépêches de l’Agence afin de renforcerla qualité et la fiabilité de ses réponses tout en valorisant le travail de ses 1 700 journalistes.
Ce partenariat entre Mistral AI, licorne française et acteur européen majeur de la GenAI, et l’AFP, agence de presse mondiale qui vient de fêter ses 80 ans, permettra au Chat de s’appuyer sur les 2 300 dépêches qui enrichissent chaque jour les fils de l’AFP en six langues (français, anglais, espagnol, portugais, allemand et arabe).
Les utilisateurs bénéficieront ainsi de réponses plus détaillées, précises et sourcées, conformes aux plus hauts standards journalistiques.
Arthur Mensch, PDG et cofondateur de Mistral AI, souligne :
“S’appuyer sur une agence de presse reconnue mondialement comme l’AFP permettra au Chat d’apporter des réponses fiables et factuelles, à jour, et vérifiées par des professionnels de l’information. Nous sommes convaincus qu’augmenter la factualité des réponses est une étape clef dans le déploiement de notre technologie, notamment dans les entreprises. Grâce à ce partenariat, nous offrons à nos clients une alternative multiculturelle et multilingue inédite.”
Une opportunité pour l’AFP
De son côté, en intégrant ses contenus à une application conversationnelle innovante, l’AFP élargit son audience tout en affirmant sa pertinence dans un univers médiatique en mutation, et ce, sans compromettre son éthique ou sa rigueur éditoriale.
Fabrice Fries, PDG de l’AFP, commente :
“Par ce partenariat, l’AFP poursuit la diversification de ses revenus auprès d’une clientèle hors médias et s’ouvre à de nouveaux usages de ses contenus dans le quotidien des entreprises. L’AFP se réjouit de cette première avec un acteur de l’intelligence artificielle à l’identité européenne assumée, qui reconnaît ainsi, ce qui est bienvenu par les temps qui courent, la valeur d’une information vérifiée, contextualisée, hiérarchisée.”
L’intégration de l’AFP sera étendue à tous les utilisateurs du Chat dans les semaines à venir.
Le CES (Consumer Electronics Show) 2025 ouvre ses portes aujourd’hui, rassemblant des participants et des exposants du monde entier. Santé connectée, équipements de maison intelligents, voitures autonomes, puces dédiées, l’IA y sera omniprésente. Comme chaque année, différentes entreprises n’ont pas attendu son lancement officiel pour annoncer les innovations technologiques qu’ils y présenteront. C’est d’ailleurs le cas de Samsung qui lors de son événement “CES 2025 First Look”, a présenté hier Samsung Vision AI, une suite de fonctionnalités alimentées par l’IA pour ses téléviseurs.
Le CES 2025, organisé par la Consumer Technology Association (CTA), réunira plus de 4 500 exposants et attend environ 138 000 participants, dont 1 400 startups et 50 000 visiteurs internationaux. C’est à Jensen Huang, PDG de NVIDIA, nommé meilleur PDG du monde par Fortune et The Economist, figurant parmi 100 personnes les plus influentes du monde selon le magazine TIME. Qu’a été confié le rôle de prononcer le discours d’ouverture, hier soir.
Samsung Vision AI
Samsung Vision AI symbolise la prochaine étape dans l’évolution des écrans intelligents. Selon SW Yong, président et responsable de l’activité d’affichage visuel chez Samsung Electronics :
“Samsung ne considère pas les téléviseurs comme des appareils unidirectionnels destinés à la consommation passive, mais comme des partenaires interactifs et intelligents qui s’adaptent à vos besoins.”
Samsung Vion AI, intégrée dans une large gamme de modèles, notamment les Neo QLED, OLED, QLED et The Frame, permet aux téléviseurs de s’adapter à leur environnement, de comprendre les préférences des utilisateurs et d’offrir des fonctionnalités intuitives de manière autonome. Parmi les fonctionnalités principales :
Click to Search permet d’obtenir des informations instantanées sur ce qui est affichées à l’écran, qu’il s’agisse d’identifier un acteur ou d’explorer le contenu affiché, sans interrompre le visionnage ;
Live Translate, une fonctionnalité que l’on retrouve dans les smartphones Galaxy S24, offre des traductions de sous-titres en temps réel, éliminant les barrières linguistiques ;
Generative Wallpaper permet de créer des images dynamiques personnalisées, adaptées aux goûts des utilisateurs ou à l’occasion.
Samsung Vision AI s’intègre également à l’écosystème SmartThings pour un mode de vie connecté :
Home Insights fournit des mises à jour en temps réel sur l’environnement domestique, notamment des alertes de sécurité ;
Pet and Family Care permet de détecter des comportements inhabituels chez les animaux ou les membres de la famille. Cette fonctionnalité peut également ajuster automatiquement les paramètres de la maison si nécessaire, comme éteindre la lumière d’une pièce lorsqu’un enfant s’endort.
Une qualité d’image et de son optimale
Samsung Vision AI améliore la qualité visuelle et sonore grâce à des technologies d’IA embarquées qui analysent et ajustent dynamiquement les paramètres selon le contenu et l’environnement.
Par exemple, le modèle Neo QLED 8K QN990F, le téléviseur le plus avancé de Samsung, utilise des fonctionnalités telles que la mise à l’échelle 8K AI Pro et la remasterisation HDR automatique Pro pour offrir des visuels réalistes et des couleurs éclatantes. Son adaptatif Pro sépare et optimise les composants sonores tels que la parole, la musique et les effets sonores pour une immersion totale.
L’innovation par des partenariats stratégiques
Samsung, qui prévoit de travailler en étroite collaboration avec des partenaires d’IA de premier plan tels que Google et d’autres pour étendre les fonctionnalités de Vision AI, a annoncé un partenariat avec Microsoft visant à intégrer l’assistant Copilot de ce dernier à ses téléviseurs et moniteurs intelligents.
Lors de CES 2025 First Look, il a également dévoilé le Premiere 5, le premier projecteur interactif à ultra-courte focale (UST) à trois lasers de l’industrie et le miroir à affichage innovant MICRO LED Beauty Mirror.
Le jeudi 28 novembre dernier, lors de l’événement Impact PME, Antoine Armand, ministre de l’Économie, des Finances et de l’Industrie, et Clara Chappaz, secrétaire d’État chargée de l’Intelligence artificielle et du Numérique, ont lancé l’appel à manifestation d’intérêt “IA au service de l’efficience”. Initialement prévue pour le 31 décembre 2024, la date de soumission a été repoussée au 15 janvier 2025.
L’IA représente une opportunité stratégique pour stimuler la croissance économique en augmentant la compétitivité, l’innovation et la productivité dans de nombreux secteurs mais son adoption est freinée par des préoccupations liées à son fonctionnement.
Piloté par la DGE, l’AMI vise à recueillir des exemples concrets d’intégrations réussies de l’IA afin de renforcer la confiance, offrir des perspectives pratiques et motiver d’autres organisations à adopter la transformation par l’IA.
Les projets lauréats seront mis en avant lors du Sommet pour l’action sur l’IA qui se déroulera les 10 et 11 février 2025, bénéficiant ainsi d’une visibilité internationale.
Qui peut candidater ?
L’AMI est ouvert à l’ensemble des entreprises (microentreprises, PME, ETI incluses), administrations publiques et organisations internationales qui ont mis en œuvre des projets d’IA visant à améliorer la compétitivité, les capacités d’innovation et la productivité de l’une des thématiques prioritaires : l’IA pour l’administration publique, l’IA pour les entreprises ou l’IA pour l’industrie.
Projets attendus
Les organisations intéressées sont invitées à soumettre leurs contributions pour examen dans ces trois domaines thématiques et sous-thèmes, y compris mais sans s’y limiter :
IA pour les entreprises
Cette thématique explore comment l’intelligence artificielle peut transformer les opérations commerciales dans les organisations :
Service client alimenté par l’IA ;
Automatisation et optimisation des processus ;
Gestion des connaissances ;
Analyse prédictive et prévisions.
IA pour l’industrie
Cette thématique explore comment l’intelligence artificielle peut augmenter la productivité et améliorer la durabilité dans diverses industries (par exemple, la fabrication, le transport, l’énergie, la santé) :
Robotique intelligente dans la fabrication ;
Améliorations du contrôle de la qualité ;
Maintenance prédictive ;
Réduction de la consommation d’énergie et optimisation des ressources ;
Réduction des émissions de CO₂ ;
Automatisation des tâches difficiles ou dangereuses.
IA pour l’administration publique
Cette thématique explore comment l’intelligence artificielle peut fondamentalement améliorer les opérations gouvernementales et les services publics :
Chatbots pour les services aux citoyens ;
Détection de la fraude ;
Planification urbaine;
Réponse et gestion des urgences et des catastrophes.
Les critères de l’AMI
Les projets déposés devront remplir plusieurs critères :
avoir dépassé la phase d’expérimentation ou la phase pilote ;
être en phase de déploiement, d’industrialisation ou de passage à l’échelle, avec des résultats concrets et mesurables ;
être facilement transférables et utiles pour d’autres organisations, avec des exemples concrets et des métriques.
Avec Phi-4, Microsoft démontre une nouvelle fois qu’il est possible de concilier performance et compacité. Ce SLM de 14 milliards de paramètres qui selon l’entreprise “excelle dans le raisonnement complexe dans des domaines tels que les mathématiques, en plus du traitement du langage conventionnel”, a réussi à surpasser sur certains benchmarks des modèles de pointe tels que Gemini Pro 1.5, GPT-4o ou Claude 3.5 Sonnet.
Alors qu’on a pu voir arriver des LLMs affichant un nombre de paramètres de plus en plus impressionnant, certains acteurs de l’IA comme Mistral AI ou Google proposent désormais des modèles beaucoup plus compacts. Microsoft, avec ses modèles Phi, s’est intéressé au potentiel des SLMs dès avril 2023. Alors qu’il a dévoilé les modèles Phi-3,5 : Phi-3.5-mini-instruct, Phi-3.5-MoE-instruct, et Phi-3.5-vision-instruct, optimisé chacun pour des tâches spécifiques, en août dernier, il introduit Phi-4.
Selon Microsoft, si Phi-4 surpasse des modèles comparables et plus grands sur le raisonnement lié aux mathématiques, c’est grâce aux progrès réalisés depuis le développement de Phi-3.5. Il explique cette avancée par :
L’usage de données synthétiques de haute qualité, qui enrichissent les capacités du modèle ;
Des processus de post-formation innovants, optimisant ses réponses pour des tâches spécifiques ;
Une conservation rigoureuse des données organiques pour maintenir la pertinence linguistique.
On peut voir dans l’image ci-dessous qu’il surpasse largement LLama-3.1-8B_Instruct et que ses performances sont légèrement en deçà de celles de LLama-3.3-70B-Instruct.
Microsoft a évalué ses performances sur des benchmarks de compétitions mathématiques organisées par la Mathematical Association of America (MAA), notamment les tests AMC 10/12, conçus pour évaluer les compétences en trigonométrie, algèbre, géométrie et probabilité des élèves du secondaire.
Phi-4 a obtenu des résultats impressionnants, surpassant des modèles plus grands comme Gemini Pro 1.5, Claude 3.5 Sonnet et GPT-4o, comme on peut le constater dans ce graphique.
Phi-4 est disponible sous un accord de licence de recherche via Azure AI Foundry. Présentée à Ignite 2024, le mois dernier, cette plateforme fournit des outils robustes pour évaluer, atténuer et gérer les risques liés à l’IA, ce qui garantit une utilisation sûre du modèle. Celui-ci sera également accessible sur Hugging Face dans les prochains jours.
Microsoft Ignite 2024 s’est déroulé la semaine dernière à Chicago. L’événement a été riche en annonces et innovations pour les entreprises, notamment dans les domaines de l’IA, de la sécurité et des outils de collaboration. Parmi les principales annonces, de nouveaux agents d’IA pour Microsoft 365, le nouveau service “Azure AI Foundry” ou un mini-PC basé sur le cloud.
Automatiser les tâches quotidiennes avec les “Copilot Actions”
Actuellement en beta privée, les “Copilot Actions” sont conçues pour automatiser les tâches répétitives au sein de Microsoft 365. Ces outils permettent, à partir d’un prompt, de recevoir un résumé quotidien des actions importantes, automatiser la collecte de feedback pour une newsletter hebdomadaire, ou préparer des réunions avec les résumés de dernières interactions avec les clients.
De nouveaux agents d’IA dans Microsoft 365
Microsoft introduit de nouveaux agents pour Copilot dans Microsoft 365 qui permettent de trouver rapidement des informations, de résumer des documents et de répondre aux questions courantes des employés.
Copilot dans Teams et PowerPoint : une collaboration enrichie
Copilot dans Teams peut désormais comprendre, récapituler et répondre aux questions basées sur le contenu visuel partagé à l’écran, en plus de la transcription et du chat. Dans PowerPoint, Copilot peut traduire des présentations entières dans 40 langues tout en conservant la conception des diapositives.
Copilot dans Outlook : planification et personnalisation
Copilot dans Outlook aide à planifier des entretiens individuels et à rédiger des ordres du jour de réunion. Les utilisateurs peuvent désormais personnaliser l’apparence de leur interface avec des thèmes uniques.
Agents en libre-service et interprétation en temps réel
Les nouveaux agents en libre-service pour les employés dans Business Chat répondent rapidement aux questions de politique courantes et facilitent l’exécution des tâches clés. L’agent d’interprétation dans Teams fournit une interprétation vocale en temps réel pendant les réunions. Pour une expérience plus personnelle, l’utilisateur peut choisir de lui demander d’imiter sa voix.
Azure AI foundry
Microsoft a également présenté Azure AI Foundry, une plateforme conçue pour rationaliser le développement, la personnalisation ainsi que la gestion d’applications et d’agents d’IA au sein des entreprises.
Elle se compose du portail Azure AI Foundry, anciennement Azure AI Studio, qui a évolué vers une console de gestion d’entreprise centralisée, et du SDK Azure AI Foundry, un kit de développement logiciel unifié qui facilite l’intégration des modèles avec des environnements de développement familiers tels que GitHub et Visual Studio.
Windows 365 Link
Microsoft a dévoilé le Windows 365 Link, un mini-PC basé sur le cloud destiné aux entreprises. Ce dispositif compact permet aux employés de se connecter à leur environnement de travail depuis n’importe où en intégrant pleinement le service Windows 365. Il supporte des moniteurs 4K doubles, dispose du Wi-Fi 6E et du Bluetooth 5.3, et sera disponible en avril 2025 au prix de 349 $.
Teradata, une plateforme d’analyse et de données cloud pour l’IA, a récemment annoncé la nomination de Louis Landry au poste de Chief Technology Officer (CTO). Fort de plus de 20 ans d’expérience en architecture logicielle et ingénierie, Louis Landry prend les rênes de la stratégie technologique de l’entreprise à un moment charnière pour le secteur de l’analytique et de l’IA.
Louis Landry est titulaire d’une licence en informatique acquise à l’université Louisiana Tech et s’est vu décerner un Rethink Strategy Certificate par la Harvard Business School.
Entré chez Teradata il y a plus de 10 ans, il a gravi les échelons pour devenir, en 2020, vice-président de la Technologie et de l’Innovation de l’entreprise. Dans ce rôle, il a piloté plusieurs initiatives stratégiques, notamment Teradata ask.ai et Teradata AI Unlimited, le premier moteur d’IA/ML à la demande de l’entreprise, qui ont positionné cette dernière comme un acteur clé dans l’intégration de l’IA générative et des plateformes de données connectées.
Auparavant, il a occupé des postes de direction clés au sein de la société, notamment celui d’Engineering Fellow et CTO of Unified Data Architecture Platform Technologies.
Une nomination stratégique pour Teradata
Dans un contexte où la demande en solutions d’IA et d’analytique s’accélère, la nomination de Louis Landry reflète l’engagement de Teradata envers l’innovation.
Steve McMillan, PDG de Teradata, souligne :
“Je ne peux imaginer meilleur choix que Louis pour veiller à ce que notre roadmap technologique réponde aux besoins actuels et futurs de nos clients et de nos prospects. Je suis ravi que Louis prenne la direction des opérations tandis que nous continuons de construire l’avenir de Teradata en tant que plateforme d’IA hybride. Sa compréhension approfondie du marché et des nouvelles technologies dans le domaine des données et de l’analytique nous permettra de tirer pleinement parti de l’innovation en tant que facteur clé pour une croissance accélérée”.
Avant de rejoindre les rangs de Teradata, Louis Landry a occupé plusieurs postes importants chez MicroStrategy, où il était chargé du développement de produits analytiques. Chez Sears Holdings Corporation, il a dirigé la conception d’une plateforme d’acquisition de données en temps réel à l’aide de technologies open source. Chez eBay Inc., il a supervisé le développement d’une plateforme analytique destinée aux principaux vendeurs du marché, ainsi qu’un projet interne d’analyse as-a-Service visant à rendre l’entreprise plus data-driven.
Louis Landry a également apporté d’importantes contributions à la communauté open source en tant que Project Leader and Development Coordinator dans le cadre du projet Joomla! de 2005 à 2011.
Pour lui, ce nouveau rôle est une opportunité de faire progresser la mission de Teradata. Il commente :
“À l’heure où l’IA transforme les entreprises, la fiabilité des données, les performances et l’efficacité à l’échelle de Teradata offrent exactement les bases dont les entreprises ont besoin. Je suis ravi de contribuer à la poursuite des avancées de notre plateforme ouverte et connectée, en apportant la prochaine génération de valeur axée sur l’IA à nos clients dans l’environnement de leur choix”.
une vision stratégique pour l’avenir de l’IA et de l’analytique
AMD prévoit de réduire ses effectifs de près de 1 000 employés. Cette restructuration intervient dans un contexte économique difficile pour sa division gaming, confrontée à une chute de 69 % de ses revenus sur un an, et la volonté de l’entreprise à s’imposer sur le marché des puces d’IA où NVIDIA est le leader incontesté.
Lisa Su, présidente et PDG d’AMD, déclarait le 29 octobre dernier aux investisseurs :
“Nous avons enregistré de solides résultats financiers au troisième trimestre avec un chiffre d’affaires record grâce à l’augmentation des ventes de produits de centres de données EPYC et Instinct et à une forte demande pour nos processeurs PC Ryzen. Pour l’avenir, nous voyons d’importantes opportunités de croissance dans nos centres de données, nos clients et nos activités intégrées, en raison de la demande insatiable de plus de calcul”.
Si AMD, qui employait 26 000 personnes fin 2023, n’a pas donné plus de précisions sur ces licenciements, une partie d’entre eux concernera sans doute la division gaming.
Un porte-parole de l’entreprise a déclaré :
“Dans le cadre de l’alignement de nos ressources sur nos plus grandes opportunités de croissance, nous prenons un certain nombre de mesures ciblées qui entraîneront malheureusement une réduction de notre effectif mondial d’environ 4% “.
La société s’attendait à ce que son chiffre d’affaires pour le quatrième trimestre 2024 s’élève à environ 7,5 milliards de dollars, soit une croissance de 22 % par rapport à l’année précédente, portée notamment par la vente de son GPU InstinctMI300X , qu’elle présente comme un sérieux concurrent au H100 de NVIDIA.
Malgré ces bons résultats, le cours de l’action AMD a chuté d’environ 16,5% depuis le 29 octobre 2024 alors que celui de NVIDIA, porté par une demande accrue pour ses GPU dédiés aux data centers, a augmenté de 200% depuis le début de l’année.
Pour autant, AMD compte bien lui reprendre des parts de marché avec l’Instinct MI325X, qui devrait être disponible début 2025, l’Instinct MI350 au semestre suivant et l’Instinct MI400 en 2026.
DeepL, l’un des leaders mondiaux de l’IA linguistique, a dévoilé hier lors de sa conférence DeepL Dialogues à Berlin, sa première solution de traduction vocale en temps réel : DeepL Voice. Disponible en deux déclinaisons, DeepL Voice pour réunions et DeepL Voice pour conversations, elle vise à rendre les échanges professionnels plus fluides, en réduisant les barrières linguistiques pour des entreprises évoluant dans un contexte globalisé.
Fondée en 2017 par Jaroslaw (Jarek) Kutylowski, son directeur général, la licorne allemande DeepL, s’est donnée la mission d’affranchir de la barrière de la langue les entreprises du monde entier. Plus de 100 000 entreprises et gouvernements et des millions de particuliers sur 228 marchés internationaux font déjà confiance aux traductions, aussi bien de contenus écrits que de conversations orales, de la plateforme d’IA linguistique de DeepL et à son assistant de rédaction, DeepL Write.
En mai dernier, DeepL a levé 300 millions de dollars, valorisant à 2 milliards l’entreprise qui a intégré la liste Cloud 100 de Forbes.
Conçues pour répondre aux besoins de sécurité des entreprises, les solutions basées sur cette IA permettent à celles-ci de changer leur façon de communiquer, de se lancer sur de nouveaux marchés et d’optimiser leur productivité.
Jarek Kutylowski explique :
“En tant qu’entreprise, la traduction vocale en temps réel avec la qualité et la sécurité éprouvées de DeepL était notre prochain défi. Nous sommes heureux de pouvoir enfin dévoiler aujourd’hui nos premiers produits. Pour y parvenir, nous nous sommes appuyés sur l’expertise et les modèles que nous avons développés depuis notre création en 2017, et avons travaillé en étroite collaboration avec des clients dans le cadre d’un programme bêta afin de proposer une solution adaptée aux défis quotidiens des entreprise”.
Soulignant :
“DeepL est déjà leader dans la traduction de contenus écrits, mais la traduction de la parole en temps réel pose de tout autres défis : informations incomplètes, problèmes de prononciation et latence sont quelques-uns des facteurs qui peuvent entraîner des traductions inexactes et une mauvaise expérience utilisateur. Ces mêmes éléments peuvent conduire à des malentendus dans les interactions personnelles. Nous avons donc conçu une solution qui en tient compte dès le départ et qui permet aux entreprises de dépasser la barrière de la langue en leur donnant la possibilité de communiquer dans plusieurs langues, selon leurs besoins”.
Une réponse aux défis de la communication multilingue en entreprise
Avec DeepL Voice, l’entreprise fait sa première incursion dans le secteur de la traduction vocale. La sécurité et la qualité de traduction de pointe qui ont fait sa réputation sont également au cœur de ses deux nouveaux produits.
DeepL Voice pour réunions
Cette solution permet à tous les participants de s’exprimer dans la langue de leur choix, tandis que leurs contributions sont traduites en temps réel et affichées sous forme de sous-titres aux autres. Les membres d’une même équipe peuvent ainsi échanger dans leur langue maternelle, pour une communication plus claire et dynamique que jamais.
Crédit DeepL
DeepL Voice pour conversations
Disponible sur appareils mobiles, la solution facilite les échanges multilingues avec les clients, entre employés, en face-à-face, grâce à des sous-titres. L’outil propose deux modes de visualisation pratiques pour que chaque personne puisse suivre les traductions facilement sur un seul appareil.
Crédit DeepL
DeepL Voice prend d’ores et déjà en charge les langues parlées suivantes (d’autres seront ajoutées par la suite) : anglais, allemand, japonais, coréen, suédois, néerlandais, français, turc, polonais, portugais, russe, espagnol et italien, avec des sous-titres traduits disponibles dans les 33 langues prises en charge par DeepL Translator.
L’Adobe Firefly Summit 2024, en avril dernier, a été l’occasion pour l’éditeur de logiciels graphiques dont InDesign, Acrobat, Photoshop et Illustrator, de présenter les innovations qui allaient permettre aux marques d’optimiser leur créations de contenu. Cette semaine, lors de sa conférence annuelle Adobe MAX, il a lancé la version bêta de l’extension de la famille à la génération vidéos à partir de texte ou d’image : Firefly Video.
Adobe avait dévoilé le modèle le mois dernier et donné un accès anticipé à certains créateurs, la version bêta publique est déployée dans l’application Web Firefly, mais pour y accéder, il faut au préalable s’inscrire sur la liste d’attente. Pour l’instant, la durée maximale des clips générés n’est que de cinq secondes.
Tout comme Sora, le modèle text-to-video d’OpenAI, Movie Gen, présenté récemment par Meta, Firefly Video peut générer des vidéos à partir d’une invite textuelle. Plus celle-ci sera détaillée, comprenant des descriptions précises de la prise de vue, des mouvements de caméra, de l’éclairage et de l’ambiance, plus elle répondra aux attentes de l’utilisateur, comme ci-dessous.
Prompt : Gros plan cinématographique et portrait détaillé d’un homme âgé au milieu d’une rue la nuit. L’éclairage est sombre et dramatique. L’homme a une texture de peau détaillée extrêmement réaliste et des pores visibles. Le mouvement est subtil et doux. La caméra ne bouge pas. Grain de pellicule. Objectif anamorphique vintage.
Le modèle peut générer des séquences vidéo B-roll pour compléter des plans manquants ou des effets visuels comme du feu ou de la fumée que l’on peut ensuite superposer sur une vidéo existante, à l’aide de modes de fusion ou d’incrustations dans des outils Adobe tels qu’Adobe Premiere Pro ou Adobe After Effects.
Prompt : Fuites de lumière sur fond noir, texture organique, réaliste.
Composite dans Premiere Pro avec le mode de fusion Écran
Firefly permet également de créer des vidéos à partir d’images fixes, donnant une nouvelle vie aux bibliothèques de photos existantes. Par exemple, un simple cliché de fleurs peut être transformé en une vidéo avec l’invite “les fleurs bougent dans le vent et un papillon se pose délicatement sur l’une d’entre elles”
Adobe s’engage à adopter une approche éthique de l’IA. Le modèle Firefly est exclusivement entraîné sur des contenus sous licence ou du domaine public. En outre, chaque création générée par Firefly intègrera des Content Credentials, qui offrent une transparence totale sur l’origine du contenu et le rôle de l’IA dans sa création.
Selon la dernière étude menée par l’Institut de recherche économique Hiring Lab d’Indeed, une entreprise américaine spécialisée dans la recherche d’emploi en ligne, bien que l’IA et d’autres technologies avancées soient appelées à transformer le marché du travail, de nombreux employeurs continuent de valoriser les compétences informatiques de base.
L’étude d’Indeed révèle que les compétences numériques élémentaires, telles que la maîtrise du pack Office et l’utilisation de logiciels courants, figurent dans 13 % des offres d’emploi en France. Ces compétences IT restent particulièrement recherchées dans des secteurs comme l’assistance administrative (22 % des offres), les médias et la communication (19 %), ainsi que le marketing (17 %). Cette récurrence montre que même dans un monde où l’automatisation prend de l’ampleur, la capacité à utiliser un ordinateur de façon fluide est encore un atout clé sur le marché du travail.
Par contre, ces compétences techniques de base ne sont que très peu requises dans les offres d’emploi concernant les professions en présentiel comme la puériculture, les soins personnels et médicaux à domicile ou le transport routier.
Une demande toujours forte pour les compétences humaines
En parallèle des compétences techniques, l’étude souligne également l’importance croissante des compétences humaines. L’anglais, par exemple, reste la compétence non technique la plus fréquemment mentionnée dans les offres d’emploi, suivi du sens du service client et des capacités organisationnelles. Ces qualités sont de plus en plus recherchées dans un contexte où les interactions humaines et la collaboration restent des piliers essentiels dans de nombreux secteurs.
Les compétences en IA : une montée progressive, mais encore marginale
Si l’intelligence artificielle promet de bouleverser de nombreux métiers, les compétences directement liées à l’IA ne représentent encore qu’une petite part des offres d’emploi en France. En 2024, seulement 1,5 à 2,5 % des annonces mentionnent des compétences en IA, une proportion encore modeste mais en augmentation depuis 2022, surtout dans les secteurs de la finance, des ressources humaines et du juridique.
Cependant, un segment spécifique lié à l’IA connaît une croissance explosive : celui de l’IA générative, avec une multiplication par 15 des offres d’emploi contenant ce type de compétence depuis 2022, avec l’arrivée de ChatGPT. Bien que ces offres soient encore rares (environ 0,15 % des annonces), leur rapide ascension pourrait annoncer une transformation du marché de l’emploi dans les années à venir.
Des outils spécialisés en forte croissance
En plus des compétences de base, certaines compétences techniques plus avancées sont également en forte demande. Par exemple, des logiciels spécialisés comme Power BI dans la finance, ADP dans les ressources humaines, ou Amadeus dans le secteur de l’hôtellerie-restauration gagnent en importance. Cela montre que les recruteurs, tout en insistant sur les compétences fondamentales, commencent à valoriser des connaissances plus spécifiques en fonction des métiers et des secteurs d’activité.
Les offres d’emploi pour les professions hautement techniques enregistrent un net recul
En France, les offres d’emploi dans les segments très techniques, comprenant des métiers tels que le développement informatique, l’ingénierie industrielle ou la recherche scientifique, ont diminué de 4 % par rapport à leur niveau d’avant la pandémie. Ce segment se distingue par des offres nécessitant plusieurs compétences techniques spécifiques.
En revanche, les métiers moins techniques connaissent une dynamique différente. Les segments faiblement techniques, où une seule compétence technique est généralement requise, ont vu une augmentation des offres de 59 % depuis la pandémie. Les professions moyennement techniques, quant à elles, ont enregistré une hausse de 20 %. Ces chiffres soulignent une tendance de fond où la demande pour des compétences plus généralistes, notamment les compétences IT de base, est en forte croissance.
Une évolution paradoxale
Ce ralentissement dans les métiers très techniques pourrait surprendre dans un contexte où les avancées technologiques se multiplient. Toutefois, il reflète une réalité où les entreprises, tout en s’adaptant aux nouvelles technologies, continuent de valoriser les compétences élémentaires.
L’IA, bien qu’en pleine expansion, n’a pas encore pleinement redéfini le marché du travail. Cependant, plus les compétences numériques de la main-d’œuvre progresseront, plus la diffusion des innovations numériques sera rapide, augmentant ainsi les gains de productivité.
La Chine ne cache pas son ambition de rattraper et dépasser les USA dans le domaine de l’IA pour en devenir le leader mondial. Considérant la GenAI comme un moteur de croissance et un atout concurrentiel clé, elle a annoncé en octobre 2023, un plan pour augmenter sa puissance de calcul globale de plus de 50 % d’ici 2025, visant 300 exaflops. Alors qu’elle s’en approche aujourd’hui, elle fait face à une surabondance d’infrastructures et une inadéquation croissante entre la capacité de calcul disponible et la demande réelle du marché.
La Chine a massivement investi dans les infrastructures de datacenters ces dernières années, pour répondre à la demande croissante liée à l’explosion de l’usage d’Internet, de l’IA, du cloud computing, et des services numériques. Elle a atteint une puissance de calcul totale de 246 exaflops, représentant 26 % du total mondial, juste derrière les États-Unis.
Ce chiffre impressionnant découle de la multiplication des centres de données à travers le pays, soutenue par des gouvernements locaux, des opérateurs télécoms et des investisseurs privés. Plus de 250 centres ont été construits ou sont en cours de construction.
Cependant, selon le Centre d’information d’État de Chine, les taux d’utilisation des CPU dans ces centres sont étonnamment bas, avoisinant seulement 5 %. La course à la construction a créé une surcapacité massive, avec de nombreux centres de données peu connectés aux besoins du marché réel : des régions comme la Mongolie Intérieure ou le Xinjiang, où les coûts énergétiques sont plus bas, ont attiré des projets de datacenters, mais n’ont pas vu de demande de services de calcul suffisante en raison de leur éloignement des grands centres économiques chinois comme Pékin, Shanghai ou Shenzhen.
Une inadéquation technologique exacerbée par les sanctions américaines
À cette surabondance s’ajoute un problème technique majeur : le retard de la Chine dans la fabrication des puces de pointe et l’inadéquation des GPU. Alors que l’IA et le traitement de grandes quantités de données nécessitent des unités de traitement graphique (GPU) de pointe, la Chine souffre d’un manque criant de ces équipements essentiels. Les restrictions imposées par les États-Unis, notamment l’interdiction à Nvidia et d’autres fournisseurs américains comme Micron et AMD, de lui vendre des puces avancées, ont compliqué l’accès à ces technologies essentielles pour les applications d’IA à grande échelle.
Dans un premier temps, Nvidia avait donc décidé de vendre à la Chine des produits alternatifs répondant aux exigences du gouvernement : les puces A800 et H800, moins performantes que les GPU A100 et H100, mais assez puissantes pour entraîner des modèles d’IA générative. De nouvelles restrictions ont été annoncées, notamment la vente des puces A800 qui a été interdite sans licence d’exportation spéciale des États-Unis, appliquée également aux sociétés fournissant des solutions informatiques basées sur le cloud utilisées par certaines entreprises chinoises pour contourner les contrôles à l’exportation.
En effet, la Chine est encore loin de la finesse de gravure de 3 nm du leader mondial, le groupe Taiwan Semiconductor Manufacturing Company (TSMC), quand bien même le 1er fondeur du pays SMIC (Semiconductor Manufacturing International Corp), a commencé à produire des puces gravées en 7 nm l’an passé.
En réponse aux restrictions, le gouvernement chinois a encouragé l’utilisation de matériel local, malgré les défis d’intégration. Par exemple, certains centres de données comme celui de China Mobile à Harbin fonctionnent avec des GPU fabriqués en Chine. Cependant, leur complexité d’utilisation en clusters de grande échelle empêche une exploitation optimale des infrastructures. Ces équipements restent moins performants, ce qui pourrait limiter la capacité des modèles d’IA générative chinois à rivaliser avec leurs concurrents étrangers.
Des acteurs de la GenAI chinois ont malgré tout présenté dernièrement des modèles text-to-video, avec l’objectif de rattraper, voire surpasser, leurs concurrents américains : Zhipu AI,Kuaishou, et plus récemment Minimax, une start-up par d’anciens employés de SenseTime, soutenue par Alibaba et Tencent.
Alors que dans le cadre de ses priorités politiques, la Chine entend continuer à encourager l’application de la GenAI dans des secteurs clés tels que l’industrie manufacturière, l’agriculture, l’éducation et la santé afin de renforcer l’économie, elle doit relever le défi de transformer ces installations sous-utilisées en moteurs réels de croissance économique et d’innovation technologique.
Les professionnels de l’automatisation jouent un rôle essentiel dans la modernisation et l’optimisation des processus au sein des entreprises. Chaque année, UiPath, l’un des leaders de l’automatisation des processus robotiques (RPA), enquête auprès d’eux pour appréhender leurs perceptions et l’évolution du secteur. Menée auprès de 1 909 professionnels et étudiants, l’édition 2024 révèle une transition notable dans les tâches des développeurs d’automatisation, ainsi qu’une forte adoption de l’IA pour améliorer la productivité des entreprises.
L’étude UiPath 2024 révèle une année charnière pour l’automatisation, marquée par l’intégration de l’IA, la croissance des équipes spécialisées et l’évolution des tâches des développeurs.
L’IA pilier central de l’automatisation
En 2024, l’IA est devenue une composante incontournable des projets d’automatisation : 81 % des répondants indiquent utiliser des produits d’IA dans leurs projets d’automatisation au moins plusieurs fois par semaine, voire quotidiennement.
Selon le rapport, 90 % des professionnels de l’automatisation utilisent ou prévoient d’intégrer l’IA dans leurs workflows d’ici la fin de l’année. La principale raison avancée pour cette intégration est l’augmentation de la productivité, citée par 66 % des répondants.
Les développeurs d’automatisation utilisent l’IA de diverses manières, notamment pour :
Coder des solutions automatisées (67 %) ;
Créer de la documentation (57 %) ;
Effectuer des tests (47 %).
Des équipes d’automatisation en pleine croissance
Le rapport met en avant une croissance significative des équipes d’automatisation, reflet d’un marché en pleine expansion : 61 % des répondants ont observé une augmentation du nombre d’employés travaillant dans ce domaine au cours des 12 derniers mois. De plus, 81 % s’attendent à des embauches supplémentaires dans l’année en cours.
52 % des entreprises comptent désormais au moins 25 professionnels de l’automatisation, un chiffre en constante augmentation. Cette expansion témoigne de l’adoption généralisée de l’automatisation, devenue un levier clé de transformation pour les entreprises.
L’évolution des tâches des développeurs
L’étude révèle, comme chaque année, un changement dans la typologie des tâches réalisées par les développeurs d’automatisation. Selon les résultats, en 2024, les tâches liées à la révision du code et à la documentation ont diminué par rapport à 2023, une optimisation des processus d’automatisation et l’amélioration des outils utilisés.
Parmi les activités exercées au moins une fois par semaine, les plus courantes sont :
Conception de solutions d’automatisation en fonction des besoins (78 %) ;
Maintenance, support et débogage des solutions en production (68 %) ;
Tests des solutions d’automatisation (48 %) ;
Création de documentation (47 %) ;
Révision de code (44 %).
La formation, clé de la montée en compétences
Pour accompagner cette évolution rapide, 98 % des professionnels de l’automatisation ont suivi une formation au cours de l’année écoulée. Parmi les méthodes les plus populaires :
Tutoriels vidéo (62 %) ;
Documentation (56 %) ;
Cours en ligne autonomes (50 %) ;
Forums en ligne (49 %) ;
Formation virtuelle (39 %).
L’utilisation des moteurs d’IA (33 %) et des vidéos sur les réseaux sociaux (20 %) est en augmentation, ces deux nouvelles méthodes ayant fait leur apparition en 2024.
L’avenir prometteur de l’automatisation
Le rapport souligne que 84 % des répondants croient fermement en la croissance du secteur de l’automatisation logicielle. D’ailleurs 80 % d’entre eux estiment qu’ils joueront un rôle de plus en plus important au sein de leur organisation au cours de l’année à venir. Aujourd’hui, 60 % des entreprises utilisent des solutions d’automatisation depuis plus de cinq ans, contre 47% l’année dernière, ce qui marque une maturité croissante dans l’intégration de ces technologies.
Les automatisations sont principalement développées pour les secteurs de la comptabilité et la finance (67 %), l’informatique (53 %) et les opérations (51 %).
Si des défis persistent, comme la documentation incomplète ou les variations dans les processus, l’avenir de l’automatisation s’annonce prometteur, porté par des innovations technologiques et des équipes de plus en plus compétentes et polyvalentes.
Agi Garaba, Chief People Officer chez UiPath, commente:
“Les résultats de notre enquête montrent des progrès notables en matière de découverte technologique et de préparation à l’IA et à l’automatisation. Les professionnels de l’automatisation ont tout à gagner à sauter le pas des intégrations spécialisées d’IA et de GenAI dans leurs projets d’automatisation.
La combinaison de l’automatisation et de l’IA offre un potentiel de transformation inouï pour les organisations, en augmentant la productivité tout en donnant à ces professionnels essentiels les moyens de faire passer leur carrière à la vitesse supérieure. En outre, des workflows d’IA agentique encore plus performants devraient arriver très prochainement sur le marché et devraient offrir de nouvelles perspectives aux entreprises”.
Depuis 2017, l’éditeur de logiciels Berger-Levrault, et Inria, l’Institut national de recherche en sciences et technologies du numérique, travaillent de concert pour accélérer le développement de solutions numériques basées sur l’IA destinées aux secteurs des collectivités, de la santé et de l’industrie auxquels Berger-Levrault s’adresse. Ils ont récemment présenté les résultats concrets de leur collaboration.
Berger-Levrault fournit des solutions logicielles de ressources humaines, de gestion financière et de gestion de maintenance. En 2021, le partenariat avec Inria a été renforcé, avec un objectif partagé : construire un numérique plus responsable.
Les résultats de cette collaboration illustrent parfaitement la valeur ajoutée d’une alliance entre la recherche académique et le secteur industriel. L’un des principaux aboutissements est la création d’un outil de génération de code qui accélère considérablement le développement des logiciels chez Berger-Levrault. Cet outil booste la productivité des équipes de production, permettant une mise sur le marché plus rapide des solutions.
Les équipes d’Inria et de Berger-Levrault ont par ailleurs intégré des solutions de réalité augmentée aux logiciels de maintenance. Celles-ci facilitent l’accès instantané à l’information et offrent des services de téléassistance aux techniciens sur le terrain, garantissant ainsi des interventions plus rapides et précises.
Elles ont également développé des algorithmes d’IA dédiés à l’Internet des objets (IoT) et au edge computing. Ces solutions optimisent la maintenance prédictive des équipements et infrastructures, permettant une gestion énergétique plus efficace et une réduction des coûts opérationnels.
Parmi les autres réalisations, on trouve des assistants intelligents, développés pour les clients de divers secteurs de Berger-Levrault, alimentés par des IA génératives sécurisées et spécifiques à la réglementation de chaque métier. Parmi eux, le premier assistant personnel conçu spécifiquement par et pour les secrétaires de mairie des collectivités de moins de 5 000 habitants.
Les travaux en cours
Il est clair pour les deux partenaires que les assistants numériques joueront un rôle central dans les solutions de gestion. Ils travaillent donc à relever plusieurs défis afin de pouvoir optimiser l’interaction homme-machine grâce à la GenAI.
Ils s’efforcent donc de renforcer les capacités de mémoire et de raisonnement des IA, et d’optimiser leur efficience énergétique afin de minimiser l’impact environnemental.
Mustapha Derras, directeur de la recherche et de l’innovation technologique chez Berger-Levrault, souligne :
“Les défis que nous relevons avec Inria témoignent de l’importance d’investir en amont dans la recherche. Notre collaboration de longue date délivre des résultats tangibles qui accélèrent l’innovation numérique au service des utilisateurs de nos solutions”.
Shahin Hodjati, directeur des opérations pour la direction générale déléguée à l’innovation chez Inria, conclut :
“Nous constatons avec grande satisfaction les résultats positifs de la collaboration avec Berger-Levrault dans le domaine du génie logiciel. Aujourd’hui, la mise en production de résultats scientifiques et technologiques apporte un impact significatif à Berger-Levrault. Nous nous réjouissons également de la confiance mutuelle établie entre nos directions respectives et de la volonté de Berger-Levrault d’étendre nos collaborations, notamment sur les sujets gravitant autour de l’intelligence artificielle”.
Berger-Levrault et Inria : un partenariat stratégique pour un numérique plus responsable
Ce 1er octobre, le projet DATAWISE (Data Annotation Technology Advancement With Innovative Solutions for Efficiency), lauréat de l’AAP R&D Booster de la région AURA (Auvergne-Rhône-Alpes), est officiellement lancé. Porté par Neovision, en collaboration avec le laboratoire LIRIS (Laboratoire d’Informatique en Images et Systèmes d’Information), ce projet a pour objectif automatiser l’annotation des données, étape cruciale pour l’entraînement des modèles d’IA en vision par ordinateur.
Datawise est l’un des projets labellisés par Minalogic, le pôle de compétitivité des technologies du numérique en Auvergne-Rhône-Alpes, retenus par le programme R&D Booster de la région AURA, dans la thématique “Intelligence Artificielle”. Ce dispositif vise à favoriser et soutenir des projets collaboratifs de R&D entre acteurs de la recherche académique et entreprises de la région pour concrétiser le développement de nouveaux produits, procédés ou services.
Ce projet d’automatisation d’annotation des données a été proposé par Neovision, une société grenobloise créée en 2014, experte en ML et computer vision, spécialisée dans le développement de solutions d’IA sur mesure et est mené en collaboration avec le LIRIS. Cette unité mixte de recherche (UMR 5205) du CNRS, de l’INSA de Lyon, de l’Université Claude Bernard Lyon 1, de l’Université Lumière Lyon 2 et de l’Ecole Centrale de Lyon, à laquelle nous avions consacré un article dans le n° 10 de notre magazine est largement reconnue pour ses travaux de pointe dans les domaines du traitement d’image, des systèmes d’information et des sciences des données.
Automatiser l’annotation des données : une réponse à un défi crucial
L’accès à de vastes volumes de données de qualité est essentiel pour le développement de modèles d’IA performants. Cependant, dans des domaines comme la vision par ordinateur, la préparation et l’annotation manuelles de ces données, fastidieuses et chronophages, représentent souvent un obstacle majeur.
Comme l’explique Stefan Duffner, chercheur au LIRIS,
“Cette préparation des données peut considérablement ralentir les cycles de développement des IAs et détourner les Data Scientists de leur cœur de métier : l’analyse et la valorisation des données”.
Ce partenariat allie l’innovation technologique du secteur privé aux dernières avancées académiques, créant une synergie propice à la création de solutions robustes et évolutives pour répondre aux besoins des secteurs industriels. Il permettra de développer des technologies capables d’automatiser non seulement l’annotation des données, mais également leur nettoyage, permettant ainsi d’accélérer le développement des modèles d’IA et d’en améliorer les performances tout en limitant les biais.
Lucas Nacsa, PDG et cofondateur de Neovision, explique :
“Les IA dédiées au traitement d’images sont souvent initialement entraînées sur des tâches simples, comme la reconnaissance de chiens ou de chats, avant de passer à des objets plus complexes. Cette méthode d’apprentissage limite parfois leurs performances. Notre ambition est de développer des modèles capables de s’entraîner directement sur des données industrielles complexes, sans nécessiter une préparation manuelle massive des données. Cela représente un bond en avant significatif en matière de performance et accélère considérablement le processus de création de solutions d’IA.”
Un partenariat stratégique
En automatisant l’annotation des données, DATAWISE ouvrira de nouvelles perspectives pour de nombreux secteurs industriels, en particulier ceux qui manipulent de grandes quantités de données visuelles. Les technologies développées dans le cadre de ce projet rendront les solutions d’IA plus accessibles et renforceront la compétitivité des entreprises, notamment en leur permettant d’exploiter des bases de données jusqu’ici sous-utilisées.
À terme, les partenaires envisagent l’intégration de grands modèles de langage (LLM) aux outils développés, afin d’améliorer l’ergonomie des solutions et ainsi encourager leur adoption par les entreprises.
Precisely, une entreprise spécialisée depuis plus de 50 ans dans le domaine des données, a publié une nouvelle étude menée en collaboration avec le LeBow College of Business de l’Université Drexel, une école de commerce de Philadelphie. Intitulée “2025 Outlook: Data Integrity Trends and Insights”, cette étude met en lumière les défis majeurs auxquels les entreprises sont confrontées en matière de préparation des données pour l’adoption de l’IA et d’autres initiatives liées à la gestion des données.
Cette étude a été menée au cours du premier semestre 2024, 565 professionnels des données et de l’analytique du monde entier y ont participé.
Une confiance limitée dans les données freine l’IA
Bien que 60 % des entreprises interrogées reconnaissent l’influence croissante de l’IA sur leurs programmes de gestion des données (soit une hausse de 46 % par rapport à 2023), seulement 12 % estiment que la qualité de leurs données est suffisante pour soutenir des initiatives efficaces en matière d’IA. L’étude souligne une méfiance persistante des entreprises envers leurs propres données, avec 67 % d’entre elles déclarant ne pas faire entièrement confiance aux données utilisées dans leurs processus décisionnels, un chiffre en hausse par rapport à 55 % en 2023.
Le manque de gouvernance des données est identifié comme le principal obstacle à l’adoption de l’IA par 62 % des répondants. Les entreprises peinent à suivre où sont stockées leurs données, qui y a accès et si elles contiennent des informations personnelles sensibles, ce qui complique les initiatives d’IA.
La pénurie de compétences en IA, un défi persistant
Outre les problèmes de qualité et de gouvernance des données, 42 % des entreprises signalent que la pénurie de compétences et de ressources nécessaires à la gestion des données, à l’analytique et à l’IA s’est également aggravée cette année.
Pour Murugan Anandarajan, directeur académique du Center for Applied AI and Business Analytics à Drexel LeBow, le manque de compétences et de formation en IA est un défi stratégique crucial pour les dirigeants. Il affirme :
“Alors que les organisations sont impatientes de bénéficier des capacités de l’IA, une pénurie de talents entrave l’intégration de l’IA.Les résultats de notre recherche mettent en évidence cette lacune, puisque 60 % des personnes interrogées citent le manque de compétences et de formation en matière d’IA comme un défi important pour le lancement d’initiatives en matière d’IA – un signal pour les dirigeants que l’amélioration des compétences doit être un impératif stratégique”.
La qualité des données : un défi prioritaire
L’étude montre une détérioration des perceptions de la qualité des données, avec 77 % des entreprises classant la qualité de leurs données comme « moyenne » ou « pire » en 2024, contre 66 % l’année précédente. Le manque d’outils d’automatisation pour 49 %, l’incohérence des formats de données (45 %) et le volume de données (43 %) figurent parmi les obstacles les plus fréquemment cités.
Par conséquent, 64 % des entreprises placent désormais la qualité des données en tête de leurs priorités en matière d’intégrité des données.
L’étude montre par ailleurs que la piètre qualité des données continue d’avoir un effet domino sur tous les aspects de l’intégrité des données, 50 % des personnes interrogées déclarant que la qualité est le principal problème pour les projets d’intégration des données de leur entreprise.
Adoption croissante de la gouvernance des données
Malgré ces défis, l’étude révèle une augmentation significative des efforts en matière de gouvernance des données. En 2024, 71 % des entreprises interrogées déclarent avoir mis en place des programmes de gouvernance des données, contre 60 % en 2023. Les entreprises ayant investi dans ces programmes constatent des améliorations :
de la qualité des données (58 %) ;
des perspectives et de l’analytique des données (58 %) ;
en matière de collaboration (+ 57 %) ;
d’une meilleure conformité aux réglementations en vigueur (50 %) ;
d’un accès plus rapide aux données pertinentes (36 %).
Enrichissement des données et analyse spatiale
L’étude met également en évidence l’importance croissante de l’enrichissement des données et de l’analyse spatiale, deux initiatives clés pour maximiser l’innovation et la compétitivité des entreprises, qui ont émergé l’an passé. En 2024, 28 % des entreprises considèrent l’enrichissement des données comme une priorité, contre 23 % en 2023.
Josh Rogers, CEO de Precisely, conclut :
“L’étude que nous avons menée conjointement avec Drexel LeBow révèle un déclin marqué de la confiance que les entreprises accordent à la préparation de leurs données malgré l’importance croissante de la prise de décision basée sur les données. Pour tirer pleinement parti des avantages métiers qu’apportent l’analytique et l’IA, les entreprises doivent investir dans l’intégrité des données. L’établissement d’un socle de données à la fois précises, cohérentes et contextualisées peut les aider à prendre des décisions avisées en toute confiance ainsi qu’à véritablement bénéficier de la valeur de leurs initiatives en faveur de l’IA”.
Le manque de qualité et de gouvernance des données, obstacle majeur à l'adoption de l’IA par les entreprises, selon Precisely
Meta a dévoilé hier, lors de sa conférence annuelle Meta Connect, la dernière itération de sa famille Llama 3, Llama 3.2. Celle-ci se compose de quatre modèles : les deux plus grands (11B et 90B), multimodaux, peuvent traiter les images, tandis que les deux plus légers (1B et 3B) sont uniquement textuels, comme leurs prédécesseurs. Destinés aux smartphones et aux périphériques, ces modèles de petite taille sont disponibles pour l’Europe, contrairement aux modèles de vision, du moins jusqu’à ce que Meta et l’UE trouvent un terrain d’entente.
Pour rappel, c’est en juillet dernier que Meta avait dévoilé la famille de modèles Llama 3.1 : Llama 3.1 8B et Llama 3.1 70B, deux versions améliorées de Llama 3 7B et Llama 3 70B présentés en avril dernier, mais également Llama 3.1 405B. Ce nombre impressionnant de paramètres fait de ce dernier le plus grand modèle open source à ce jour.
Comme les modèles Llama 3.1, les quatre versions Llama 3.2 sont multilingues et disposent d’une fenêtre contextuelle pouvant aller jusqu’à 128 000 jetons.
Les modèles de vision 11B et 90B
Pour la première fois, les modèles Llama intègrent des capacités de traitement d’images grâce à une nouvelle architecture intégrant un encodeur d’image au modèle de langage. Ils prennent en charge les entrées de texte et d’image ainsi que la sortie de texte, ce qui les rend adaptés à des tâches comme l’analyse de graphiques, la génération de légendes d’images, ou le “visual grounding” comme la localisation directionnelle d’objets dans des images à partir de descriptions en langage naturel.
Les modèles sont prêts à l’emploi pour de nombreux cas d’usage dès leur téléchargement, sans avoir besoin d’entraînements supplémentaires complexes. Sinon, ils peuvent être peaufinés facilement avec TorchTune, puis déployés localement avec TorchChat, ce qui offre une flexibilité maximale pour des applications spécifiques tout en assurant un contrôle local des données et des ressources.
Les SLM 1B et 3B
Ces modèles compacts sont conçus pour fonctionner de manière optimale sur des appareils légers, tels que les téléphones mobiles ou les dispositifs embarqués. Meta a utilisé des techniques d’élagage (pruning) et de distillation pour maintenir des performances élevées sur des tâches telles que la synthèse, le suivi d’instructions et la réécriture, tout en réduisant leur taille pour une meilleure efficacité sur ces appareils.
Disponibles en versions pré-entraînées ou adaptées pour le suivi d’instructions, ils permettent une personnalisation facile pour diverses applications. Optimisés pour les processeurs basés sur l’architecture Arm, ils sont d’ores et déjà disponibles pour les appareils équipés de puces Qualcomm et MediaTek.
Évaluation des modèles Llama 3.2
Les modèles de vision Llama 3.2 (11B et 90B) sont compétitifs avec des modèles leaders comme Claude 3 Haiku et GPT4o-mini sur des tâches de reconnaissance d’image et de compréhension visuelle.
Le modèle 3B surpasse des concurrents comme Gemma 2.6B et Phi 3.5-mini dans des tâches comme le suivi d’instructions, la synthèse et l’utilisation d’outils. Le modèle 1B, plus léger, reste compétitif avec Gemma.
Meta continue de promouvoir une approche ouverte pour encourager l’innovation. Les modèles Llama 3.2 sont disponibles au téléchargement via llama.com et Hugging Face, et peuvent être utilisés directement sur un large éventail de plateformes partenaires.
Llama Stack Distribution
Meta a également introduit les premières distributions de Llama Stack, une suite d’outils conçus pour simplifier le déploiement de ces modèles dans différents environnements y compris en mode nœud unique, sur site, dans le cloud et sur appareil. La distribution sur appareil se fait via PyTorch ExecuTorch, et la distribution en mode nœud unique via Ollama.
Les distributions regroupent plusieurs fournisseurs d’API pour offrir aux développeurs un point d’accès unique. Elles incluent une interface en ligne de commande (CLI), du code client en plusieurs langages (Python, Node, Kotlin, Swift), ainsi que des conteneurs Docker pour simplifier l’intégration. Elles offrent une solution clé en main pour travailler avec les modèles Llama 3.2 dans des contextes variés.
Llama 3.2 : Meta présente ses premiers modèles multimodaux à Meta Connect 2024
Les étudiants d’aujourd’hui ont grandi avec Internet et les réseaux sociaux. Alors que l’IA générative s’est imposée elle aussi dans leur quotidien, la plateforme d’IA AIPRM a voulu savoir dans quelle mesure ils s’en servaient au Royaume-Uni pour tricher.
Christopher Cemper, fondateur et PDG de LinkResearchTools, Link Detox et URLinspector, est un expert reconnu dans le domaine de l’optimisation des moteurs de recherche (SEO) et du marketing numérique. Il a lancé AIPRM (AI Prompt Repository Manager) pour répondre à la demande croissante d’outils capables de faciliter l’interaction avec les modèles d’IA générative comme ChatGPT.
L’objectif de la plateforme, développée par les experts de LinkResearchTools et URLinspector, est de permettre à ses utilisateurs d’optimiser leur utilisation de ce modèle ainsi que celle de Claude, Midjourney et DALL-E 3, en proposant une gestion efficace des prompts. Elle donne accès à plus de 4 000 invites, vérifiées et approuvées par la communauté, facilitant la création de contenu marketing, de vente, d’exploitation, et d’assistance à la clientèle.
Étudiants de l’enseignement supérieur et tricherie avec la GenAI
Le recours à la tricherie n’est pas nouveau, souvent motivé par une pression pour obtenir de bons résultats, une mauvaise gestion du temps, ou un manque de compréhension des attentes académiques. Elle englobe divers comportements, tels que la demande d’aide à un parent ou un ami pour rédiger un devoir, la copie sur un autre élève, l’achat de dissertations, l’utilisation d’outils ou de notes interdits lors des examens, ou encore le copier-coller sur Internet.
Les enseignants ont habituellement recours à des logiciels pour déceler le plagiat des textes publiés sur le web, mais détecter un contenu généré par l’IA lorsque l’étudiant a ajouté quelques touches personnelles est beaucoup plus ardu, ce qui avait d’ailleurs amené certaines écoles à interdire ou à limiter l’utilisation de ChatGPT .
Des études ont révélé qu’aujourd’hui les étudiants utilisent fréquemment la GenAI dans le cadre de leurs études (86 %), plus de la moitié (54 %) y ayant recours chaque semaine, notamment pour la production de contenu sans attribution, une nouvelle forme de tricherie. Les écoles ont investi dans des logiciels de détection de génération par l’IA, mais ceux-ci peuvent manquer de fiabilité.
L’enquête d’AIPRM
Alors que selon une étude de l’Université de Stanford, plus d’un étudiant sur six admet avoir triché, AIPRM a envoyé plus de 150 demandes d’accès à l’information aux universités britanniques pour découvrir combien d’étudiants ont été pris en flagrant délit de tricherie à l’aide de l’IA au cours des deux dernières années, et où ces infractions sont les plus fréquentes.
Les résultats, provenant des 80 universités disposant de données, montrent que plus de quatre universités sur cinq (82,5 %) ont enquêté sur l’utilisation abusive de l’IA.
Les étudiants de Birmingham City University sont ceux qui ont eu le plus recours à l’IA pour tricher, avec 402 cas au cours des deux dernières années académiques. L’université est celle qui a le plus souffert de l’essor de la GenAI, avec 307 de ces cas survenus en 2022/2023. En comparaison, Birmingham Newman University n’a signalé aucune infraction.
Juste derrière Birmingham City, l’Université de Leeds Beckett a infligé 395 pénalités aux étudiants tricheurs. Parmi ces cas, 205 proviennent de l’année universitaire 2023/2024, indiquant que l’utilisation de l’IA pour tricher est en augmentation dans cette université.
L’Université de Coventry a rapporté 231 sanctions pour utilisation de l’IA, l’Université Robert Gordon 211, suivie de l’Université de Hull avec 193 pénalités. À l’opposé, des universités britanniques comme Cambridge, le Conservatoire royal d’Écosse, l’Université de Londres, l’Université de Gloucestershire, et le Royal College of Art n’ont signalé aucune sanction.
Universités
Nombre de sanctions
Birmingham City University
402
Leeds Beckett University
395
Coventry University
231
Robert Gordon University
211
University of Hull
193
Birkbeck, University of London
147
Leeds Trinity University
119
University of Lincoln
82
University of Kent
74
Abertay University
72
Comment utiliser l’IA de manière éthique dans les études
Christopher C. Cemper commente les résultats de l’enquête et explique comment utiliser l’IA de manière éthique dans les études universitaires :
“Utilisez l’IA comme un ami ou un assistant, mais pas comme un substitut pour rédiger votre travail. L’IA peut être une excellente ressource pour trouver des recherches académiques, générer des idées et résumer des articles. Cependant, assurez-vous que le travail reste le vôtre et qu’il conserve son originalité. Par exemple, l’IA peut vous aider avec la grammaire et le style d’écriture, mais ne l’utilisez pas pour rédiger un article ou une section entière de votre devoir”.
“Utilisez l’IA comme un guide pour améliorer vos compétences, mais veillez toujours à appliquer vos propres capacités de réflexion critique et à ajouter une touche humaine. Cependant, ne présentez pas le travail produit par l’IA comme le vôtre ou sans attribution appropriée, sinon vous risquez de lourdes sanctions pour plagiat”.
GenAI : le nombre d'étudiants britanniques utilisant l'IA pour tricher est en hausse
MV Group, premier groupe indépendant en marketing digital en France, annonce le prochain lancement d’IA VISTA, une plateforme innovante qui promet de transformer les campagnes marketing grâce à l’IA et à la Data. Avec un investissement de plusieurs millions d’euros sur ces prochaines années, ce projet ambitieux marque une étape clé dans l’évolution numérique du groupe.
Créé en 2010, basé à Cesson-Sévigné, près de Rennes, en Bretagne, MV Group s’est donné pour mission d’accroître la performance de ses clients en utilisant tous les leviers du digital : data, webmarketing et médias. Comptant aujourd’hui huit filiales et deux écoles, il a pris en 2017 une avance significative en matière de data grâce à l’acquisition stratégique d’Avanci, une agence de data spécialisée en stratégie de fidélisation clients, renforcée en 2022 par celle du groupe NM Data (ex Neptune media).
En janvier dernier, ce dernier et trois autres filiales du Groupe : Adress Company, Data Company et Ebit Data, ont fusionné avec Avanci, afin de répondre aux exigences du marché en matière de collecte, gestion, analyse et exploitation des données dans les stratégies marketing, notamment grâce à l’intégration de l’IA.
Aujourd’hui, MV Group mobilise plus de 100 experts dédiés à l’IA et la data, consolidant ainsi son positionnement à la pointe de l’innovation, alors que l’adoption de ces technologies reste encore marginale dans le marketing.
Réinventer le marketing digital
IA VISTA incarne l’avenir du marketing digital de l’entreprise. Son objectif : offrir une plateforme technologique unique, capable d’optimiser les performances des campagnes de marketing digital à travers une exploitation intelligente des données. En combinant la 1st party Data des clients avec la 3rd party Data issue de Profilia, la mégabase de données BtoC d’Avanci, IA VISTA ouvre la voie à des ciblages ultra-précis et des contenus hyper-personnalisés.
Une équipe d’experts pour une solution intégrée
Le projet IA VISTA est soutenu par une équipe pluridisciplinaire de plus de 10 experts issus des différentes filiales de MV Group. Cette équipe a été renforcée par l’arrivée de David Flouriot, Responsable Data et IA, ainsi que par de nouveaux talents spécialisés en IA et DevOps. Ensemble, ils travaillent au développement d’une plateforme capable de rendre les données facilement accessibles, enrichies et directement exploitables par les entreprises clientes.
Cette solution a pour ambition de répondre à des besoins multiples :
Amélioration des performances des campagnes : segmentation plus fine des audiences, identification de profils similaires (lookalikes), ciblage géographique optimisé, et création de contenu ultra-ciblé ;
Diffusion sur de multiples supports : IA VISTA permet une diffusion large et homogène des campagnes sur divers canaux tels que les réseaux sociaux, le SMS, l’email, et même le print ;
Conformité renforcée : tout en garantissant la qualité et la transparence des données, cette solution assure une conformité maximale avec le RGPD, un atout crucial dans le paysage digital actuel ;
Une avancée technologique durable et responsable
Outre les performances commerciales, IA VISTA s’inscrit également dans une démarche respectueuse de l’environnement. En optimisant l’utilisation des données et en réduisant les campagnes inutiles, cette technologie permet de diminuer l’empreinte énergétique des actions marketing, contribuant ainsi à un marketing digital plus responsable.
IA VISTA est ainsi une réponse aux enjeux actuels du marketing digital : une personnalisation accrue, une efficacité optimisée et un respect accru des normes environnementales et réglementaires, confirmant le rôle de pionnier de MV Group.
Projet IA VISTA de MV Group : l’IA et la Data au cœur du marketing digital
La troisième édition du Global AI Summit (GAIN), organisée par la Saudi Data & Artificial Intelligence Authority (SDAIA), s’est déroulée du 10 au 12 septembre derniers dans la capitale saoudienne, Riyad. Cet événement de grande envergure a non seulement mis en lumière les dernières avancées technologiques dans le domaine de l’IA, mais a également insisté sur l’importance cruciale d’une action concertée des gouvernements et des décideurs politiques à l’échelle mondiale. Le sommet a appelé à la mise en place d’un cadre éthique rigoureux et d’une gouvernance responsable pour s’assurer que l’IA se développe au service du bien commun et de l’humanité tout entière.
Un sommet en pleine expansion
Depuis sa création en 2020, le Sommet mondial de l’IA a connu une croissance exponentielle, reflétant le rôle central que joue aujourd’hui l’Arabie saoudite dans le domaine de l’IA. Avec plus de 150 sessions, GAIN 2024 a été une plateforme de discussions stratégiques, d’innovations technologiques et de collaborations internationales. Le sommet a accueilli plusieurs annonces importantes, avec plus de 25 lancements de projets et la signature de plus de 80 accords et protocoles d’accord.
Le sommet a été retransmis en direct et visionné 3,7 millions de fois à travers le monde, illustrant l’intérêt croissant pour l’IA et son rôle potentiel dans l’avenir de l’humanité.
Des partenariats stratégiques pour une IA locale et régionale
L’Autorité a signé un protocole d’accord avec Microsoft Arabia visant à renforcer leur collaboration en cours, notamment avec la mise en place un centre d’excellence commun destiné à accélérer l’innovation dans le domaine de l’IA générative, en mettant l’accent sur des modèles linguistiques en langue arabe, avec IBM pour la création d’un Centre de recherche et d’innovation en IA en Arabie Saoudite, et avec NVIDIA pour étendre l’infrastructure d’IA dans tout le Royaume.
D’autres initiatives notables de la SDAIA ont été annoncées, parmi elles, le lancement de la Communauté mondiale de l’IA, ainsi que celui de la plateforme THAKAI, un centre de partage de données et de contenus sur l’IA, en partenariat avec des institutions académiques et des entreprises internationales.
En outre, des lignes directrices relatives à une utilisation responsable de la technologie deepfake ont été présentées, disponibles à la consultation publique.
L’avenir de l’IA
Lors de la deuxième journée du Sommet, les participants ont largement débattu de la nécessité d’établir un code de gouvernance mondial pour l’IA, en résonance avec le thème du sommet : “Intelligence artificielle pour le bien de l’humanité”. Ils ont insisté sur l’importance cruciale d’une gouvernance efficace pour équilibrer les avantages et les risques associés à ces technologies.
Les discussions ont également mis en évidence le besoin urgent de développer une infrastructure robuste qui facilite l’accès aux réseaux de communication et aux services d’IA à l’échelle mondiale. Par ailleurs, les intervenants ont souligné la nécessité de promouvoir une compréhension sociétale approfondie de l’éthique de l’IA, appelant à des politiques claires qui favorisent la transparence, l’utilisation éthique et la durabilité dans les pratiques commerciales.
Le sommet s’est clôturé par un discours du directeur du Centre national d’information d’Arabie saoudite, Son Excellence le Dr Esam Alwagait, qui a remercié les participants :
“ Vos points de vue sincères nous ont non aidé à avoir une vision plus claire de ce qui nous attend, mais nous ont également ancrés dans les réalités auxquelles nous devons faire face. Ensemble, nous avons non seulement imaginé l’avenir de l’IA, mais nous l’avons aussi concrétisé en identifiant les catalyseurs nécessaires pour véritablement libérer son potentiel” .
Il a conclu :
“Il a été incroyablement inspirant de voir le monde se rassembler ici à Riyad, uni par l’élan de mettre l’IA au service de tous. L’engagement en faveur d’une action collaborative a été évident tout au long du sommet”.
Une équipe de chercheurs de l’UC Davis Health a développé une interface cerveau-ordinateur (BCI) qui permet à un homme atteint de sclérose latérale amyotrophique (SLA) de retrouver sa capacité à communiquer. Cette technologie innovante, qui traduit les signaux cérébraux en paroles avec une précision pouvant atteindre 97 %, pourrait redonner espoir aux millions de personnes atteintes de paralysie et de troubles de la parole dans le monde.
L’interface BCI a été implantée dans le cerveau de Casey Harrell, un homme de 45 ans souffrant de la maladie de Lou Gehrig (SLA), une maladie neurodégénérative qui affecte les cellules nerveuses responsables du contrôle des mouvements et des muscles de la parole. Grâce à ce dispositif, Casey Harrell peut désormais s’exprimer par l’intermédiaire d’un ordinateur qui convertit son activité cérébrale en texte parlé, avec une précision qui n’avait jamais été atteinte dans le domaine des neuroprothèses vocales.
L’étude rapportant ces travaux “An Accurate and Rapidly Calibrating Speech Neuroprosthesis” a été publiée le 14 août dernier dans le New England Journal of Medicine.
Des débuts prometteurs pour une technologie innovante
Le Dr David Brandman, neurochirurgien à l’UC Davis et co-auteur principal de l’étude avec Nicholas Card, a supervisé l’implantation de quatre réseaux de microélectrodes dans le gyrus précentral gauche de Casey Harrell une région du cerveau clé pour la coordination des mouvements de la parole. Ces électrodes captent l’activité neuronale lorsque Casey tente de parler, permettant ainsi au système de déchiffrer les phonèmes et les mots qu’il essaie de prononcer. Les mots sont affichés sur l’écran de l’ordinateur avant d’être traduits à voix haute par un modèle de synthèse vocale pré-entraîné affiné par les chercheurs.
David Brandman souligne :
“Cette technologie BCI a non seulement permis à Casey de communiquer avec ses proches, mais elle ouvre la voie à un nouveau monde d’interactions pour des patients incapables de parler. Nous avons franchi une étape décisive dans la compréhension et la décodification de l’activité cérébrale liée à la parole”.
Lors des premiers tests, le dispositif a montré une précision impressionnante de 99,6 % avec un vocabulaire limité à 50 mots, après seulement 30 minutes d’entraînement. En augmentant la taille du vocabulaire à 125 000 mots, le BCI a maintenu une précision de 97,5 %, marquant ainsi une avancée sans précédent.
Une voix retrouvée grâce à l’intelligence artificielle
Malgré les avancées récentes dans la technologie BCI, les tentatives de rétablir la communication ont été lentes et souvent imparfaites. En effet, les algorithmes de machine learning utilisés pour décoder les signaux cérébraux demandaient beaucoup de temps et de données pour fonctionner efficacement.
David Brandman explique :
“Les systèmes BCI de discours précédents comportaient de fréquentes erreurs de mots. Il était donc difficile pour l’utilisateur d’être compris de manière cohérente et constituait un obstacle à la communication. Notre objectif était de développer un système qui permette à quelqu’un d’être compris chaque fois qu’il veut parler.”
Ce qui rend cette technologie encore plus remarquable est la capacité du système à reproduire la voix de Casey telle qu’elle était avant l’apparition de la SLA, cinq ans plus tôt. L’équipe a utilisé des enregistrements audio de Casey datant d’avant la maladie pour entraîner l’IA à générer une voix proche de celle d’origine, restituant non seulement ses mots, mais aussi son identité vocale.
Sergey Stavisky, neuroscientifique à l’UC Davis et co-directeur du laboratoire de neuroprothèses, a souligné l’importance de cette avancée :
“Voir Casey exprimer des pensées et des émotions à travers sa propre voix a été incroyablement émouvant. Pour lui, comme pour nous, c’était un moment de joie pure”.
Perspectives
L’essai clinique, intitulé BrainGate 2, se poursuit avec d’autres participants, et les chercheurs espèrent que cette technologie pourra bientôt être généralisée pour améliorer la vie de milliers de patients atteints de paralysie sévère.
Casey Harrell, le premier patient à bénéficier de cette technologie, résume son expérience :
“Ne pas pouvoir parler, c’est être prisonnier de soi-même. Grâce à cette technologie, je retrouve une partie de ma liberté, et je peux à nouveau participer aux conversations”.
L’équipe de recherche continue de perfectionner le système pour augmenter encore plus la précision et la fluidité du dialogue, avec l’espoir que d’autres applications médicales suivront.
Cette percée est un immense pas en avant pour la science et la technologie, mais surtout pour les millions de personnes dans le monde qui rêvent de retrouver une voix. Avec cette technologie, ce rêve pourrait bientôt devenir une réalité.
Références de l’article :
Université de Californie – Davis Health
“An Accurate and Rapidly Calibrating Speech Neuroprosthesis” New England Journal of Medicine. DOI : 10.1056/NEJMoa2314132
Auteurs : Nicholas S. Card, Maitreyee Wairagkar, Carrina Iacobacci, Xianda Hou, Tyler Singer-Clark, Francis R. Willett, Erin M. Kunz, Chaofei Fan, Maryam Vahdati Nia, Darrel R. Deo, Aparna Srinivasan, Eun Young Choi, Matthew F. Glasser, Leigh R. Hochberg, Jaimie M. Henderson, Kiarash Shahlaie, Sergey D. Stavisky, David M. Brandman.
Une interface cerveau-ordinateur permet à un homme atteint de SLA de retrouver sa voix
Selon les chiffres communiqués par OpenAI, le succès de ChatGPT ne se dément pas, loin de là. Aujourd’hui, le nombre d’utilisateurs hebdomadaires de la version gratuite a non seulement atteint la barre des 200 millions, soit deux fois plus qu’en novembre dernier, mais plus d’un million d’utilisateurs professionnels payants utilisent désormais ses solutions contre 600 000 en avril dernier.
Cette croissance impressionnante repose sur ses trois produits phares : ChatGPT Enterprise (lancé en août 2023), Team (janvier 2024) et Edu (mai 2024). Ces outils offrent aux entreprises et institutions des solutions sur mesure pour améliorer la productivité, la collaboration et l’innovation. Le modèle de “seats” payants permet aux entreprises d’ajuster le nombre de licences en fonction de leurs besoins, consolidant la flexibilité et l’accessibilité des produits d’OpenAI.
Une expansion internationale
Bien que les États-Unis restent le marché principal d’OpenAI, plus de la moitié des seats payants sont désormais répartis à travers le monde. L’Allemagne, le Royaume-Uni et le Japon se hissent parmi les plus grands marchés internationaux, reflétant l’adoption croissante de l’IA en Europe et en Asie.
En Europe, OpenAI travaille avec des partenaires de renommée mondiale, notamment le Financial Times, pour permettre aux équipes de ce dernier de bénéficier des gains de créativité et de productivité apportés par ses outils. L’Université d’Oxford, en partenariat avec Microsoft, mène une transformation numérique majeure grâce aux technologies d’IA développées par OpenAI, tandis que des entreprises comme Sanofi les utilisent pour accélèrer le développement de nouveaux médicaments. BBVA et Zalando figurent également parmi les utilisateurs notables de ChatGPT, le premier cherchant à stimuler la productivité de ses employés et à continuer d’innover dans ses services bancaires, le second pour lancer un assistant de mode alimenté par l’IA sur ses plateformes web et son application.
Selon les équipes d’OpenAI, l’utilisation de son API a doublé depuis le lancement de GPT-4o mini, en juillet dernier. D’autres grandes entreprises européennes l’utilisent pour développer des produits innovants et interagir avec leurs clients : la plateforme Spotify pour son DJ IA personnalisé, Klarna pour améliorer les performances des employés et l’expérience client.
L’impact global de l’IA : gains en productivité et innovation
Une enquête récente menée auprès de 4 700 utilisateurs professionnels d’OpenAI montre que 92 % d’entre eux constatent une nette augmentation de leur productivité, tandis que 88 % déclarent gagner du temps dans leurs tâches quotidiennes. L’IA semble également être un moteur de créativité, avec 75 % des utilisateurs affirmant que les outils d’OpenAI ont stimulé l’innovation au sein de leurs organisations.
Les cas d’utilisation vont de la collecte d’informations à la rédaction et l’édition de contenu, en passant par la génération d’idées nouvelles. Leur adoption dans les secteurs de l’éducation, de la santé, des médias, et des services financiers reflète une tendance globale de transformation numérique facilitée par l’IA.
Brad Lightcap, directeur des opérations d’OpenAI, conclut :
“De la refonte de l’apprentissage des étudiants à l’optimisation des soins aux patients, en passant par la transformation de la manière dont les gouvernements servent leurs citoyens, l’IA redéfinit la manière dont les gens travaillent. Nous sommes fiers d’aider plus d’un million d’utilisateurs professionnels payants à travailler de manière plus productive, à rationaliser leurs opérations et à découvrir de nouvelles opportunités d’innovation”.
ChatGPT OpenAI annonce plus d'un million d'utilisateurs professionnels payants
Deux mois et demi après sa création, Safe Superintelligence Inc (SSI), la start-up cofondée par Ilya Sutskever, Daniel Gross et Daniel Levy, a finalisé un tour de table d’1 milliard de dollars. Rapportée par Reuters, cette levée de fonds, menée par des investisseurs de premier plan tels qu’Andreessen Horowitz, Sequoia Capital, DST Global et SV Angel, reflète la confiance accordée à SSI. La start-up a pris le parti de ne pas commercialiser de produit avant d’avoir la certitude que ses systèmes d’IA ne présentent aucun risque pour l’humanité.
Les trois cofondateurs ont déclaré en juin dernier lors du lancement de SSI :
“La superintelligence est à portée de main. La construction d’une superintelligence sûre (SSI) est le problème technique le plus important de notre époque. Nous avons lancé le premier laboratoire SSI au monde, avec un seul objectif et un seul produit : une superintelligence sûre. Il s’appelle Safe Superintelligence Inc. SSI est notre mission, notre nom et l’ensemble de notre feuille de route produit, car c’est notre seul objectif. Notre équipe, nos investisseurs et notre modèle commercial sont tous alignés pour réaliser SSI”.
Ilya Sutskever avait démissionné le mois précédant le lancement de SSI de son poste de scientifique en chef chez OpenAI, dont il était l’un des cofondateurs, et où il codirigeait avec Jan Leike, l’équipe de superalignement mise en place par la start-up en juillet 2023 pour minimiser les risques potentiels d’une IA qui surpasserait l’intelligence humaine.
L’un comme l’autre considèrent que développer une IA qui serait capable de s’adapter et d’exceller dans un large éventail de domaines, de manière similaire, voire supérieure, à l’intelligence humaine, autrement dit une superintelligence ou IAG, est envisageable avant la fin de cette décennie mais, pour eux, des mesures de sécurité sont nécessaires pour garantir que les systèmes d’IA restent sûrs et alignés avec les valeurs humaines.
Ils alertaient :
“La superintelligence sera la technologie la plus percutante que l’humanité ait jamais inventée et pourrait nous aider à résoudre bon nombre des problèmes les plus importants du monde. Mais le vaste pouvoir de la superintelligence pourrait aussi être très dangereux et pourrait conduire à la perte de pouvoir de l’humanité ou même à l’extinction humaine”.
Donner la priorité à la sécurité
SSI, qui compte aujourd’hui une dizaine d’employés, concentre tous ses efforts sur le développement d’une IAG sécurisée, “et rien d’autre”. Les fonds levés seront utilisés pour acquérir de la puissance de calcul, recruter les meilleurs talents, des ingénieurs et chercheurs qui seront basés à Palo Alto et Tel Aviv, “où nous avons des racines profondes et la capacité de recruter les meilleurs talents techniques”, précisait l’équipe fondatrice lors du lancement de SSI.
La start-up, serait aujourd’hui valorisée à 5 milliards de dollars selon les sources de Reuters. Daniel Gross, interviewé par ce dernier, a précisé :
“Il est important pour nous d’être entourés d’investisseurs qui comprennent, respectent et soutiennent notre mission, qui est de viser directement une superintelligence sûre et en particulier de passer quelques années à faire de la R&D sur notre produit avant de le commercialiser”.
Safe Superintelligence lève 1 milliard de dollars pour accélérer le développement de systèmes d'IA sécurisés
Zhipu AI, licorne chinoise spin-off de l’Université Tsinghua de Pékin a annoncé récemment le lancement de son dernier modèle text-to-vidéo CogVideoX-5B. Comme son prédécesseur, CogVideoX-2B, le modèle est open source, mais est, quant à lui, publié sous la licence CogVideoX qui permet une utilisation gratuite uniquement à des fins de recherche.
Développé avec les techniques d’IA les plus récentes, notamment un auto-encodeur variationnel (VAE) 3D et un transformateur expert pour améliorer l’alignement entre le contenu vidéo et les descriptions textuelles, CogVideoX se distingue par sa capacité à créer des vidéos cohérentes, capturant non seulement des détails visuels riches, mais aussi des mouvements complexes avec une fluidité sans précédent.
Les deux modèles génèrent des vidéos de six secondes, à une fréquence de 8 images par seconde et une résolution de 720×480 pixels. Cette dernière version surpasse son prédécesseur en termes de qualité et de performance.
Des technologies de pointe
L’un des éléments clés de l’architecture de CogVideoX est le VAE causal 3D qui permet une compression efficace des données vidéo, à la fois dans les dimensions spatiales et temporelles. Contrairement aux modèles de génération vidéo antérieurs utilisant un VAE 2D, où l’on observe couramment des scintillements, il permet d’assurer une continuité entre les images dans les vidéos produites par CogVideoX.
La structure du VAE comprend un encodeur, un décodeur et un régularisateur d’espace latent, permettant de réduire la longueur des séquences et les exigences computationnelles pendant l’entraînement, tout en maintenant une reconstruction vidéo de haute qualité.
Un Transformateur Expert pour fusionner les données textuelles et visuelles
L’Expert Transformer est lui aussi un élément essentiel de l’architecture de CogVideoX, spécialement conçu pour gérer l’interaction complexe entre les données textuelles et vidéo.
Dans les transformateurs classiques, toutes les modalités de données sont traitées de manière uniforme, ce qui peut entraîner des inefficacités, notamment lors de la combinaison d’entrées textuelles et vidéo aux caractéristiques et échelles variées. Le transformateur expert de CogVideoX utilise la technique de normalisation “Adaptive LayerNorm” (AdaLN), pour traiter distinctement les caractéristiques du texte et de la vidéo, facilitant leur intégration fluide.
Un entraînement progressif
Les chercheurs ont adopté et conçu plusieurs techniques d’entraînement avancées pour optimiser les performances du modèle. L’entraînement à durée mixte avec la méthode Frame Pack améliore les capacités de généralisation du modèle pour différentes longueurs de vidéo, tout en maintenant une qualité constante, tandis que l’entraînement progressif, utilisant tout d’abord des vidéos basse résolution puis des vidéos de résolution de plus en plus haute, permet au modèle de capturer d’abord les détails généraux avant de les affiner.
L’échantillonnage uniforme explicite, quant à lui, stabilise la courbe de perte d’entraînement et accélère la convergence en définissant différents intervalles d’échantillonnage temporel sur chaque rang parallèle de données. Le modèle apprend ainsi efficacement sur l’ensemble de la séquence vidéo.
CogVideoX-5B
CogVideoX-2B avait été salué pour ses performances, notamment en matière de capture de mouvement humain, de contenu dynamique et de restauration de scènes. Le nouveau modèle, avec ses paramètres plus élevés, le surpasse non seulement dans ces domaines, mais également en termes de suivi des instructions, de génération vidéo et d’effets visuels.
Des exemples de vidéos qu’il a générées sont partagées sur Hugging Face.
Pour faciliter les développements futurs, les chercheurs ont rendu open-source une partie des poids du modèle CogVideoX accessible sur GitHub et du VAE 3D. Ils travaillent au développement de modèles plus grands. Pour plus d’informations sur leur approche, vous pouvez consulter leur article de recherche sur arXiv.
La sortie du modèle marque une nouvelle étape dans le domaine de la génération vidéo à partir de texte, avec des implications potentielles dans divers secteurs, allant de la production cinématographique à l’éducation, en passant par le marketing et les médias.
Zhipu AI dévoile CogVideoX-5B, son dernier modèle text-to-video open source
L’IA joue un rôle de plus en plus important dans la gestion de projet, avec une adoption croissante par les professionnels du secteur. Selon une récente étude de Capterra, 42 % des responsables de projet français déclarent utiliser des solutions d’IA pour soutenir leurs opérations quotidiennes. Ce chiffre témoigne de l’importance croissante accordée à cette technologie pour améliorer l’efficacité et la gestion des projets dans des environnements de plus en plus complexes.
L’étude “2024 Impactful Project Management” de Capterra a été réalisée en ligne en mai 2024 auprès de 2 500 professionnels de la gestion de projet, dont 200 en France.
L’IA : un investissement rentable
L’IA peut transformer la gestion de projet en offrant des outils puissants pour l’analyse, la planification, la gestion des ressources, et la collaboration, tout en réduisant les tâches répétitives et en améliorant la prise de décision.
L’étude révèle que 96 % des responsables de projet français ayant recours à l’IA ont constaté un retour sur investissement positif au cours de l’année écoulée. Forts de ces résultats, 29 % d’entre eux prévoient d’augmenter leurs investissements en IA d’ici 2025, témoignant ainsi de la confiance croissante dans cette technologie pour améliorer l’efficacité des projets.
Les avantages de l’IA en gestion de projet
Les chefs de projet français reconnaissent plusieurs bénéfices clés de l’IA :
Amélioration de la prise de décision : 65 % des professionnels soulignent que l’IA leur fournit des informations cruciales pour prendre des décisions plus éclairées ;
Identification des risques : 48 % des répondants indiquent que l’IA les aide à repérer plus facilement les risques potentiels ;
Simplification de la planification : 55 % des chefs de projet soulignent la contribution de l’IA dans la planification des projets grâce à l’automatisation des tâches ;
Augmentation de la productivité : 54 % des utilisateurs d’IA rapportent une amélioration de la productivité et de l’efficacité.
Des défis persistants
L’intégration de l’IA aux technologies de gestion de projet se heurte à un certain nombre d’obstacles. L’étude souligne plusieurs défis :
Qualité des données : 37 % des utilisateurs mentionnent que la qualité des données générées par l’IA est parfois insuffisante, pouvant ainsi biaiser les résultats et les analyses ;
Engagement des employés : 35 % des chefs de projet rapportent un manque d’engagement des salariés, souvent dû à une méconnaissance du fonctionnement de l’IA ;
Complexité d’interprétation : L’IA traite un volume massif de données, rendant leur interprétation parfois complexe pour les responsables de projet, 30% d’entre eux soulignent ce problème ;
Coûts cachés : 29 % des répondants mentionnent des coûts inattendus liés à l’utilisation de l’IA, notamment pour la formation nécessaire à une bonne maîtrise de l’outil.
Des responsables de projet confiants
Malgré ces défis, l’avenir de l’IA en gestion de projet en France semble prometteur. 85 % des chefs de projet se disent confiants dans leur capacité à intégrer efficacement l’IA dans leurs pratiques quotidiennes, ce qui laisse entrevoir une adoption encore plus large de cette technologie dans les années à venir.
Les conseils de Capterra
Pour implémenter avec succès l’IA dans la gestion de projets, il est nécessaire de connaître ses limitations mais également de mettre en place de bonnes pratiques. Selon Capterra, un processus robuste de contrôle des données, une formation adéquate des employés, la mise en place de politiques sur l’utilisation de l’IA et, enfin, définir un équilibre entre humain et IA sont absolument nécessaires.
Emilie Audubert, analyste de contenu chez Capterra, conclut :
“L’intégration de l’intelligence artificielle dans la gestion de projet n’est plus un concept futuriste, mais une réalité d’aujourd’hui. Les technologies de l’IA fournissent aux responsables de projets de nouveaux outils pour optimiser les ressources, prévoir les risques et soutenir l’efficacité des flux opérationnels. Cependant, même les utilisateurs les plus aguerris doivent rester informés des derniers développements de l’intelligence artificielle et de ses limitations pour espérer réussir son implémentation au sein des projets de leur entreprise”.
L'IA un atout pour les chefs de projet français, malgré ses défis et ses limitations
En juin 2023, Lisa Su, la CEO d’AMD, dévoilait le GPU Instinct MI300X, conçu pour l’IA générative et le HPC. Ce processeur graphique de nouvelle génération a démontré des performances impressionnantes lors des benchmarks MLPerf Inference v4.1, confirmant sa capacité à rivaliser avec les solutions de pointe de l’industrie, notamment le NVIDIA H100. Ces résultats marquent une avancée significative pour AMD, mettant en lumière la robustesse et la polyvalence de sa plateforme d’inférence full-stack.
L’importance des benchmarks MLPerf
Les benchmarks MLPerf, développés par MLCommons, sont essentiels pour évaluer la performance des matériels et logiciels d’intelligence artificielle (IA). Alors que les modèles de langage deviennent de plus en plus complexes, la nécessité d’une puissance de calcul efficace et d’une optimisation logicielle rigoureuse devient primordiale. Pour les entreprises, performer dans ces benchmarks fournit des preuves tangibles de l’efficacité de leurs solutions d’IA dans des scénarios d’inférence et d’entraînement.
Performances de l’AMD Instinct MI300X avec LLaMA2-70B
La soumission du GPU AMD Instinct MI300X au benchmark MLPerf Inference v4.1 a utilisé le modèle de langage LLaMA2-70B, reconnu pour ses performances élevées et sa polyvalence dans des applications réelles comme le traitement du langage naturel. Quatre tests ont été réalisés avec le GPU fonctionnant sur un système Supermicro AS-8125GS-TNMR2 dans deux scénarios distincts
deux dans le scénario hors ligne, destiné à maximiser le débit de traitement en jetons par seconde ;
les deux autres dans le scénario de serveur, visant à simuler des requêtes en temps réel avec des contraintes de latence strictes.
Les tests ont été effectués à l’aide de processeurs EPYC « Genoa » de 4ème génération et des processeurs EPYC « Turin » de 5ème génération.
Grâce à sa mémoire de 192 Go, le MI300X a pu exécuter l’ensemble du modèle LLaMA2-70B sur un seul GPU, évitant ainsi la surcharge réseau liée à la distribution du modèle sur plusieurs unités de traitement. Grâce à l’optimisation logicielle ROCm, le MI300X peut évoluer de manière quasi linéaire de 1 à 8 GPU, offrant une flexibilité et une performance accrues pour les charges de travail intensives.
Optimisations et Innovations
Instinct MI300X, compte 153 milliards de transistors, 192 Go de mémoire HBM3 à large bande passante et 12 chiplets. Le GPU dispose également d’une bande passante mémoire de 5,2 TB/s et de 896 Go/s de bande passante Infinity Fabric.
La clé du succès du MI300X réside dans plusieurs facteurs :
Grande capacité mémoire : Avec 192 Go de mémoire HBM3, le GPU peut traiter des modèles de grande taille sans avoir besoin de les distribuer entre plusieurs unités, ce qui optimise le débit d’inférence ;
Support du FP8 : AMD a intégré le format numérique FP8 dans sa pile logicielle ROCm, permettant une quantification précise des modèles sans perte significative de performance ;
Optimisations logicielles : L’équipe d’AMD a travaillé sur l’optimisation du noyau, l’amélioration des algorithmes de planification dans vLLM, et l’amélioration de la gestion du cache KV, tout cela contribuant à une performance plus fluide et plus rapide.
Comparaison avec NVIDIA H100
La combinaison des GPU AMD Instinct MI300X et des processeurs AMD EPYC de 4ème génération montre une synergie efficace, optimisant les performances pour les charges de travail d’IA. Les performances de cette configuration sont très proches de celles du NVIDIA DGX H100, avec une différence de seulement 2 à 3 % dans les scénarios de serveur et hors ligne, en utilisant une précision FP8.
Dans certains cas, le MI300X a même dépassé le H100, notamment grâce à l’optimisation du traitement des LLMs. Cette réussite positionne AMD comme un concurrent sérieux sur le marché des accélérateurs d’IA, où NVIDIA domine.
La société déclare sur LinkedIn :
“De sa mémoire GPU massive, qui s’adapte à l’ensemble du modèle LLaMA2-70B sur un seul GPU avec de l’espace à revendre, à la prise en charge avancée de FP8 et aux optimisations logicielles de pointe, nous avons repoussé les limites des performances de l’IA. Exceller dans MLPerf Inference v4.1 est une étape importante pour AMD, soulignant notre engagement en faveur de la transparence et de la fourniture de données standardisées qui permettent aux entreprises de prendre des décisions éclairées”.
AMD prévoit de lancer les prochaines itérations de la série AMD Instinct, avec entre autres avancées, de la mémoire supplémentaire, la prise en charge de types de données de faible précision et une puissance de calcul accrue, dans les prochains mois. Les futures versions de ROCm apporteront des améliorations logicielles, notamment des améliorations du noyau et une prise en charge avancée de la quantification.
AMD dévoile les premiers résultats des GPU Instinct MI300X sur les benchmarks MLPerf Inference v4.1
LambdaTest, plateforme de test unifiée basée sur le cloud, a récemment dévoilé KaneAI, le premier studio de test alimenté par la GenAI, conçu pour transformer la création, la gestion et l’exécution des tests. Avec des fonctionnalités avancées telles que la création de tests en NLP (langage naturel), la planification intelligente des tests et l’analyse des causes profondes en temps réel, KaneAI promet de redéfinir les standards de l’industrie tout en élargissant l’accès aux tests au-delà des ingénieurs et des développeurs.
KaneAI : une nouvelle ère dans l’automatisation des tests
Depuis longtemps, l’automatisation des tests est un élément essentiel du développement logiciel, mais elle n’est pas sans défis. Les tests automatisés, souvent en retard par rapport aux cycles de développement, nécessitent une maintenance constante et deviennent rapidement inefficaces à grande échelle. Même les solutions low-code/no-code, bien que simplifiant le processus, atteignent leurs limites face aux besoins croissants en matière de tests.
KaneAI de LambdaTest est le premier agent de test d’IA logicielle de bout en bout. Conçu spécifiquement pour les équipes d’ingénierie qualité, KaneAI permet la création et l’évolution de cas de test complexes via le langage naturel, ce qui réduit considérablement le temps et les compétences nécessaires pour démarrer l’automatisation des tests.
Des fonctionnalités avancées
KaneAI ne se contente pas d’automatiser les tests ; il les réinvente. Parmi les fonctionnalités clés, on trouve la planification intelligente des tests, la correction des tests par l’IA, et des assertions conditionnelles avancées. KaneAI supporte également des flux de travail complexes, assurant une couverture complète des tests, quel que soit le niveau de difficulté.
Contrairement aux solutions traditionnelles, KaneAI propose des fonctionnalités d’édition bidirectionnelle, permettant aux utilisateurs de rédiger des tests en code ou en langage naturel. Les tests peuvent ensuite être exportés en plusieurs langages de programmation, rendant la maintenance des tests simple et évolutive, même à grande échelle.
L’outil propose également une analyse des causes profondes (RCA) en temps réel, réduisant ainsi les temps d’arrêt des applications et accélérant les cycles de publication tout en maintenant une qualité optimale du produit.
Une intégration fluide avec les outils existants
KaneAI s’intègre de manière transparente aux outils populaires tels que Jira, Slack, GitHub Actions et Microsoft Teams, permettant aux équipes de l’incorporer facilement dans leurs flux de travail DevOps existants. Cette intégration renforce la valeur ajoutée de KaneAI, en faisant un atout pour toute équipe d’ingénierie qualité cherchant à optimiser ses processus de test.
Un tournant pour l’ingénierie qualité
Avec l’introduction de KaneAI, LambdaTest s’impose comme une solution complète pour toutes les exigences d’ingénierie de la qualité logicielle de bout en bout. De la planification, la création, l’exécution, l’analyse et au reporting des tests, LambdaTest couvre désormais toutes les fonctions, ainsi que les capacités de base du déploiement d’environnements cloud pour l’exécution de tests sur des appareils et des navigateurs réels.
Asad Khan, cofondateur et PDG de LambdaTest, commente :
“Au cours des 6 dernières années, nous avons écouté les commentaires des utilisateurs sur la façon dont nous pouvons résoudre leurs tâches de test. KaneAI est le résultat de l’approche novatrice de notre équipe pour s’attaquer à ce problème. L’équipe d’ingénierie et de produit travaille sur ce produit révolutionnaire depuis plus d’un an, repoussant les limites de ce qui est possible en ingénierie de la qualité. Ils se sont assurés que chaque aspect de KaneAI répondait aux défis du monde réel auxquels les équipes de test sont confrontées au quotidien”.
Disponibilité et accès anticipé
La version bêta privée de KaneAI est disponible depuis le 21 août dernier. Les équipes d’ingénierie qualité intéressées peuvent s’inscrire pour un accès anticipé et découvrir en avant-première ce qui pourrait bien être le futur de l’automatisation des tests logiciels.
KaneAI de LambdaTest redéfinir l'automatisation des tests logiciels à l'ère de la GenAI
Alors que le Congrès américain peine à établir une réglementation encadrant les systèmes d’IA, l’état de Californie a décidé de se doter de sa propre réglementation au grand dam des principales entreprises du secteur de l’Etat, OpenAI en tête.
La loi SB 1047 en Californie est une proposition législative visant à encadrer les modèles d’IA générative. Elle a été introduite par le sénateur démocrate Scott Wiener dans le but de prévenir les dommages potentiels que des systèmes d’IA puissants pourraient causer, comme des cyberattaques ou des incidents qui pourraient entraîner des pertes massives de vies humaines. Ses détracteurs, comme ceux de l’AI Act, estiment qu’elle pourrait freiner l’innovation et faire fuir les investisseurs.
Le 2 août dernier, la société de capital-risque Andreessen Horowitz (“a16z”), basée à la Silicon Valley écrivait au sénateur Wiener :
“Bien que nous soyons convaincus que vos intentions sont de protéger la sécurité des Californiens – un objectif louable, bien sûr – le projet de loi tel qu’il est actuellement rédigé n’atteindra pas ses objectifs. Il entravera l’innovation et l’investissement dans cette technologie émergente importante, affaiblira la position des États-Unis en tant que leader mondial de la technologie et créera des obstacles inutiles et arbitraires pour une industrie compétitive qui stimule la création d’emplois en Californie à une échelle record. C’est pourquoi votre législation a généré des réactions ouvertes et des préoccupations généralisées de la part de presque tous les principaux développeurs et investisseurs de l’écosystème de l’IA”.
Face à cette opposition, les législateurs californiens ont apporté des modifications au projet de loi. Le 15 août dernier, celui-ci a été adopté par la California Appropriations Committee, une commission législative de l’Assemblée de l’État de Californie, dernière étape avant qu’il ne soit soumis à un vote final.
Le sénateur Wiener a précisé à TechCrunch :
“Nous avons accepté un certain nombre d’amendements très raisonnables proposés, et je pense que nous avons répondu aux principales préoccupations exprimées par Anthropic et beaucoup d’autres dans l’industrie. Ces amendements s’appuient sur des modifications importantes apportées précédemment au SB 1047 pour répondre aux besoins uniques de la communauté open source, qui est une source importante d’innovation”.
La version amendée du projet de loi a en effet atténué certaines exigences initiales, comme la création d’une nouvelle agence de régulation, qui a été retirée, mais elle propose néanmoins la mise en place d’un conseil consultatif chargé de développer des normes pour les systèmes d’IA les plus avancés. En outre, la législation maintient les obligations pour les développeurs de LLMs de tester la sécurité de leurs systèmes et de simuler des cyberattaques. En cas de non-respect, des amendes sont prévues, mais sans sanctions pénales.
Opposition et soutien au projet de loi
Malgré ces compromis, le projet de loi rencontre une ferme opposition de la part d’acteurs clés du secteur technologique, comme OpenAI, Google, et Meta. OpenAI, par exemple, a exprimé des préoccupations concernant le risque de voir les innovateurs quitter la Californie pour des environnements moins régulés. Des chercheurs reconnus comme Yann LeCun ou Fei-Fei Li, de l’université de Stanford, ont critiqué le projet de loi. Pour Yann LeCun, l’un des parrains de l’IA, il vise à répondre à une “illusion de ‘risque existentiel’ poussée par une poignée de groupes de réflexion délirants”, pour Fei-Fei Li, il nuira à l’écosystème d’IA naissant.
Certaines figures influentes, comme Nancy Pelosi, membre du parti démocrate, bien qu’elles soutiennent l’idée de protéger les consommateurs et de réguler l’IA, estiment que le projet de loi actuel est mal conçu et pourrait nuire à la position de leader de la Californie dans le domaine de l’IA.
Les défenseurs du projet, comme Scott Wiener et des experts comme les deux autres parrains de l’IA, Geoffrey Hinton et Joshua Bengio, estiment quant à eux que la régulation est nécessaire pour anticiper les dangers potentiels des systèmes d’IA tout en soutenant l’innovation responsable.
Le projet de loi SB 1047 doit encore passer par un vote à l’Assemblée californienne avant la fin du mois. Si elle est adoptée, ce sera au gouverneur Gavin Newsom de décider de sa promulgation. La décision du gouverneur est encore incertaine, car il n’a pas pris publiquement position sur ce texte.
Ce projet de loi est suivi de près, car il pourrait poser un précédent pour la régulation de l’IA aux États-Unis et influencer la manière dont d’autres États, voire le gouvernement fédéral, abordent cette question.
La Californie prend les devants sur la régulation de l'IA controverses autour de la loi SB 1047
HubSpot, la plateforme de gestion de la relation client (CRM) dédiée aux entreprises en croissance, a dévoilé hier l’édition 2024 de son rapport sur “Les tendances IA des marketeurs”. Basé sur une enquête réalisée en collaboration avec The Next Wave auprès de plus de 1 000 professionnels du marketing et professionnels de la publicité à travers le monde, il met en lumière l’évolution rapide de l’adoption de l’IA dans le secteur.
Créée en 2006 par Brian Halligan et Dharmesh Shah, deux anciens étudiants du MIT, HubSpot est une plateforme client qui fournit les logiciels, les intégrations et les ressources nécessaires pour connecter les équipes de marketing, de vente, de gestion de contenu et de service client. Elle publie régulièrement des rapports sur les tendances actuelles et futures du marketing. Ce dernier rapport montre qu’en quelques mois, l’utilisation de l’IA par les marketeurs a considérablement augmenté, passant de 35 % l’année dernière à 74 % cette année.
Optimisme autour du potentiel de l’IA
Le rapport révèle que la majorité des marketeurs voient dans l’IA un levier de croissance. En effet, 68 % affirment que l’IA a amélioré la dynamique de leur entreprise, 69 % indiquent qu’elle a permis de personnaliser l’expérience client, et 70 % estiment qu’elle a favorisé la collaboration entre les équipes.
L’IA a permis à plus de 7 marketeurs sur 10 de consacrer moins de temps aux tâches manuelles et plus de temps aux aspects importants de leur rôle : ce qui a permis de stimuler leur évolution professionnelle pour 68 % d’entre eux.
Près de 7 responsables sur 10 ayant investi dans l’IA déclarent avoir bénéficié d’un ROI (retour sur investissement) positif en termes de productivité et d’efficacité des employés. Ils considèrent que l’IA apporte une valeur ajoutée non pas en remplaçant leur équipe, mais en l’améliorant. Ils précisent également que les outils d’IA et d’automatisation permettent aux employés :
d’être plus productifs (45 %) ;
de prendre des décisions éclairées, basées sur la data (39 %) ;
de partager des données plus efficacement (39 %) ;
d’être plus efficaces dans leur travail (34 %).
Adoption croissante et intégration aux outils existants
Près de 3 marketeurs sur 4 intègrent des outils d’IA dans leur travail. Les cas d’utilisation les plus courants partagent un objectif commun : l’unification. En effet, 74 % d’entre eux affirment que l’intégration de capacités d’IA dans les outils existants, notamment les CRM et les outils de productivité, a encouragé l’adoption de cette technologie.
Les cinq principaux cas d’utilisation sont les suivants :
Les chatbots pour des réponses rapides et personnalisées (35 %) ;
Les outils de CRM et de marketing améliorés par l’IA (25 %) ;
Les outils de productivité améliorés par l’IA pour rationaliser les tâches quotidiennes (23 %) ;
Les outils d’IA visuelle pour générer des images (23 %) ;
Les outils de génération de texte pour créer plus rapidement des contenus performants (22 %).
L’IA, moteur de la création de contenu
Les canaux de marketing se multiplient : un précédent rapport de HubSpot souligne d’ailleurs l’omniprésence des réseaux sociaux dans les stratégies marketing des entreprises, leur usage pour le service client et la vente en ligne ainsi qu’une utilisation croissante de l’IA générative pour se démarquer.
En effet, l’IA est principalement utilisée pour la création de contenu (43 %), et ce pour la deuxième année consécutive. Cependant, les marketeurs tiennent à garder un certain contrôle : 86 % apportent des modifications avant publication.
Les principales tâches liées à la création de contenu sont :
la génération d’images (47 %) ;
la rédaction de textes (45 %);
la vérification de la qualité du contenu (44 %).
Les formats les plus courants sont :
les emails et newsletters (47 %) ;
les posts sur les réseaux sociaux (46 %) ;
les articles de blog (38 %).
Nicholas Holland, VP Product et GM, Marketing Hub chez HubSpot, commente :
“L’IA se transforme en un véritable catalyseur de productivité pour les équipes de marketing. Elle leur permet de créer plus de contenu, de naviguer sur un plus grand nombre de canaux et de générer plus de leads, tout en améliorant la qualité et la personnalisation. Les professionnels du marketing qui s’appuient sur l’IA et l’intègrent à leurs processus sont sans aucun doute ceux qui se différencieront”.
Etude HubSpot montée en puissance de l'IA dans les stratégies marketing
Selon un récent rapport de Canalys, une société d’analyse de marché spécialisée dans la technologie, 8,8 millions de PC compatibles avec l’IA ont été expédiés au deuxième trimestre 2024, ce qui représente 14 % de l’ensemble des expéditions de PC durant cette période.
Par PC compatible avec l’IA, Canalys entend un ordinateur de bureau ou un ordinateur portable dotés de chipsets ou de blocs dédiés aux charges de travail d’IA, tels que le Neural Engine d’Apple, le XDNA d’AMD, l’Hexagon de Qualcomm ou encore l’AI Boost d’Intel. Ces innovations permettent des performances optimisées pour des tâches comme la reconnaissance vocale, l’analyse d’images, et d’autres applications nécessitant de puissantes capacités de traitement en temps réel.
L’analyste principal de Canalys, Ishan Dutt, souligne que le deuxième trimestre de 2024 a marqué un tournant décisif pour l’expansion des PC compatibles avec l’IA. L’arrivée des PC Copilot+ de Qualcomm, dotés de la série de puces Snapdragon X, a été un catalyseur important, bien que les volumes d’expéditions aient été modestes en raison d’une disponibilité géographique limitée. Toutefois, l’adoption rapide de ces technologies par les OEM Windows laisse entrevoir une montée en puissance de cette catégorie dans les mois à venir.
Du côté des processeurs x86, Intel et AMD n’ont pas été en reste. Intel a intensifié la livraison de ses chipsets Core Ultra, qui ont enregistré de solides performances, tandis qu’AMD a introduit sa série de processeurs Ryzen AI 300 en juin, avec des lancements de produits prévus dès mi-juillet. Ces développements renforcent les perspectives de croissance continue pour le marché des PC compatibles avec l’IA.
Des prévisions optimistes pour 2024 et au-delà
Selon Ishan Dutt :
“Avec une base solide maintenant établie, les expéditions de PC compatibles avec l’IA sont sur le point de gagner en popularité au second semestre 2024”.
L’ensemble du secteur semble aligné sur des prévisions ambitieuses : environ 44 millions d’unités de PC compatibles avec l’IA devraient être expédiées d’ici la fin de l’année 2024, un chiffre qui pourrait grimper à 103 millions en 2025. Canalys prévoit qu’ils représenteront 60 % des PC expédiés en 2027. Cette croissance sera largement soutenue par une adoption plus large des utilisateurs finaux, alimentée par une offre de produits diversifiée à différents niveaux de prix.
Apple en tête de course
Avec 60% de parts de marché, Apple domine actuellement le marché des PC IA grâce à son portefeuille Mac intégrant les puces de la série M, équipées du Neural Engine. L’entreprise a récemment annoncé “Apple Intelligence”, une nouvelle fonctionnalité en phase bêta pour les développeurs aux États-Unis mais qu’elle a préféré reporter en Europe en raison du DMA. Elle permettra d’exploiter pleinement les capacités d’IA sur Mac, avec une compatibilité étendue à la majorité des appareils déjà en circulation, offrant ainsi une mise à niveau sans précédent pour les utilisateurs de Mac.
Windows renforce sa présence
Côté Windows, les expéditions de PC compatibles avec l’IA ont augmenté de 127 % par rapport au trimestre précédent, une performance impressionnante. Lenovo, le plus grand fournisseur de PC au monde, a lancé ses premiers modèles équipés de Snapdragon X, avec une croissance séquentielle de 228 % pour ses expéditions de PC compatibles avec l’IA. Quant à HP, 8 % des expéditions de PC Windows ont été des modèles compatibles avec l’IA, grâce notamment à sa gamme Omnibook X 14 et EliteBook Ultra G1 Snapdragon Copilot+ en plus de son offre croissante d’appareils Core Ultra dans diverses gammes de produits.
Dell, un autre acteur majeur, a également renforcé sa présence sur ce segment avec des lancements échelonnés de PC Copilot+ dans ses gammes XPS, Latitude, et Inspiron. Cette montée en gamme des offres IA, en particulier dans les segments premium de plus de 800 US ont augmenté de 9 % en séquentiel au T2 2024, les expéditions de PC compatibles avec l’IA dans ces tranches de prix ayant augmenté de 126 %. À mesure que la gamme de fonctionnalités des applications propriétaires et tierces qui exploitent le NPU augmente et que les avantages en termes de performances et d’efficacité deviennent plus clairs, la proposition de valeur pour les PC compatibles avec l’IA restera forte. C’est particulièrement important au cours des 12 prochains mois, car une partie importante de la base installée sera actualisée dans le cadre du cycle de mise à niveau de Windows en cours”.
Pour recevoir un exemplaire gratuit du rapport “Canalys Now and Next in AI PCs”, cliquer ici.
Les ventes des PC dopés à l'IA décollent avec 14% de parts de marché au second trimestre 2024
Alors que l’IA occupe une place de plus en plus grande dans notre quotidien et que les entreprises sont nombreuses à envisager son adoption, qu’en est-il de notre compréhension des risques liés sur lesquels alertent de nombreux experts ? Les cadres actuels d’évaluation de ces risques, bien qu’utiles, montrent des lacunes significatives. Pour tenter de les combler, les chercheurs du MIT publient “AI Risk Repository”, un référentiel qui comprend une base de données accessible au public, comptant plus de 700 risques liés à l’IA, qui sera élargie et mise à jour pour s’assurer qu’elle reste pertinente.
Ce référentiel a été élaboré par des chercheurs du MIT CSAIL, du MIT FutureTech, de l’Université du Queensland, du Future of Life Institute, de la KU Leuven et d’Harmony Intelligence. En rendant cette base de données accessible au public, ils espèrent non seulement sensibiliser davantage aux risques potentiels de l’IA, mais aussi encourager une collaboration plus étroite entre les différents acteurs concernés, qu’il s’agisse de développeurs, de régulateurs ou de simples utilisateurs. L’objectif est de créer un cadre de référence commun qui facilite la discussion, la recherche et la mise en place de mesures de prévention adaptées, permettant ainsi une adoption plus sûre et plus éthique de l’IA.
Peter Slattery, postdoctorant entrant au MIT FutureTech Lab et actuel chef de projet, explique :
“Étant donné que la littérature sur les risques liés à l’IA est dispersée dans des revues à comité de lecture, des prépublications et des rapports de l’industrie, et qu’elle est très variée, je crains que les décideurs ne consultent involontairement des aperçus incomplets, passent à côté de préoccupations importantes et développent des angles morts collectifs”.
Un référentiel inédit des risques liés à l’IA
Pour construire ce référentiel, les chercheurs ont passé une revue systématique des taxonomies existantes et d’autres classifications structurées des risques liés à l’IA, ce qui leur a permis de recenser et d’analyser 43 cadres déjà en place, d’identifier les forces et les faiblesses de chaque approche. Ils ont intégré les éléments les plus pertinents et robustes de ces différents cadres existants pour créer une classification qui capture de manière complète les divers types de risques associés à l’IA.
Ce référentiel se distingue par son approche systématique et exhaustive. Il est structuré autour de deux taxonomies principales. Une taxonomie causale, qui classe les risques selon leurs facteurs d’origine : entité (humain ou IA), intentionnalité et timing (avant ou après déploiement) et une taxonomie de domaine, qui les organise en 7 catégories : la confidentialité et la sécurité, la désinformation, l’interaction homme-machine, les acteurs malveillants et usage abusif, la discrimination et la toxicité, les dommages socio-économiques et environnementaux, et les défaillances et les limites des systèmes d’IA.
Les 7 domaines ont ensuite été divisés en 23 sous-domaines, souvent négligés dans les évaluations traditionnelles. Selon l’examen des chercheurs, les 43 cadres n’ont mentionné que 34 % des 23 sous-domaines de risque identifiés, près d’un quart en couvrant moins de 20 %. Aucun document ou aperçu n’a mentionné la totalité des 23 sous-domaines de risque, les plus complets n’en couvrant que 70 %.
L’analyse montre que certains domaines de risque, tels que la “sécurité des systèmes d’IA” et les “préjudices socio-économiques”, reçoivent une attention disproportionnée par rapport à d’autres, comme “l’interaction homme-machine” ou la “désinformation”. Par exemple, les risques liés à la “discrimination injuste” sont fréquemment abordés, et ont été mentionnés par 62 % des documents alors que des sujets tels que le “bien-être et les droits de l’IA” (2 %) sont presque totalement ignorés.
Chacun des 777 risques extraits des 43 cadres étudiés a été rigoureusement analysé et classé en fonction de cette double taxonomie, qui permet une analyse plus fine et une gestion plus efficace des risques. Les chercheurs ont également souligné que plus de 65 % de ces risques émergent après le déploiement des systèmes d’IA, ce qui met en évidence l’importance de la vigilance continue et de l’adaptation des stratégies de gestion des risques une fois que les technologies sont en usage réel.
Neil Thompson, directeur du MIT FutureTech Lab et l’un des chercheurs principaux du projet, commente :
“Le référentiel des risques d’IA est, à notre connaissance, la première tentative de sélectionner, d’analyser et d’extraire rigoureusement des cadres de risque d’IA dans une base de données de risques accessible au public, complète, extensible et catégorisée. Cela fait partie d’un effort plus vaste visant à comprendre comment nous réagissons aux risques liés à l’IA et à identifier s’il existe des lacunes dans nos approches actuelles”.
Ajoutant :
“Nous commençons par une liste de contrôle complète, pour nous aider à comprendre l’étendue des risques potentiels. Nous prévoyons de l’utiliser pour identifier les lacunes dans les réponses organisationnelles. Par exemple, si tout le monde se concentre sur un type de risque tout en négligeant d’autres d’importance similaire, c’est quelque chose que nous devrions remarquer et aborder”.
Le référentiel est disponible gratuitement en ligne, peut être téléchargé, copié et utilisé. Il continuera d’évoluer au fur et à mesure que de nouveaux risques seront identifiés et que de nouvelles analyses seront effectuées. Les chercheurs encouragent à contribuer à cette ressource afin qu’elle reste pertinente et à jour.
Références de l’article :
Slattery, P., Saeri, A. K., Grundy, E. A. C., Graham, J., Noetel, M., Uuk, R., Dao, J., Pour, S., Casper, S., & Thompson, N. (2024). “Une revue systématique des données probantes et un cadre de référence commun pour les risques liés à l’intelligence artificielle”.http://doi.org/10.13140/RG.2.2.28850.00968
AI Risk Repertory le MIT publie un référentiel des risques liés à l'IA
La licorne franco-américaine Hugging Face a annoncé récemment l’acquisition de XetHub, une start-up américaine spécialisée dans la gestion de fichiers pour les projets d’IA, ce qui lui permettra d’améliorer ses capacités de stockage et de gestion des données afin de répondre aux besoins croissants de modèles toujours plus grands et complexes.
Fondé en 2021 à Seattle par Yucheng Low, Ajit Banerjee, et Rajat Arya, tous anciens membres de l’équipe de machine learning (ML) d’Apple, XetHub s’est donné pour mission de simplifier l’expérimentation de données à grande échelle. Sa plateforme peut gérer des fichiers individuels de plus de 1 To (téraoctet) et des référentiels dont la taille totale dépasse 100 To, une nette amélioration par rapport à Git LFS, qui limite la taille des fichiers à 5 Go et celle des référentiels à 10 Go.
La start-up s’est démarquée en adaptant Git pour gérer des référentiels de données massifs, une compétence essentielle pour les équipes travaillant avec des modèles ML complexes et volumineux. Sa technologie permet non seulement de stocker efficacement ces énormes fichiers, mais aussi de faciliter la collaboration en permettant aux équipes de travailler simultanément sur ces ensembles de données.
Yucheng Low, cofondateur de XetHub, explique :
“L’objectif de XetHub est de permettre aux équipes de ML de fonctionner comme des équipes logicielles, en adaptant le stockage de fichiers Git aux To, en permettant de manière transparente l’expérimentation et la reproductibilité, et en fournissant les capacités de visualisation nécessaires pour comprendre comment les ensembles de données et les modèles évoluent”.
L’impact de XetHub sur le développement d’Hugging Face
La plateforme collaborative Hub de Hugging Face stocke 1,3 million de modèles d’IA, 450 000 jeux de données, 680 000 espaces et reçoit chaque jour 1 milliard de requêtes.
En 2020, lors de la création de la première version du Hub, l’équipe a choisi d’utiliser Git LFS (Large File Storage), une solution de stockage permettant de gérer des fichiers volumineux de manière efficace, mais qui montre désormais ses limites face à l’augmentation exponentielle de la taille des modèles d’IA. La technologie de XetHub permettra de passer à une solution de stockage plus adaptée, optimisant non seulement la capacité, mais aussi l’efficacité des mises à jour et des collaborations.
Grâce à cette acquisition, Hugging Face prévoit de remplacer Git LFS par une version optimisée de son propre système de stockage et de gestion de versions, intégrant les avancées technologiques de XetHub. Les utilisateurs du Hub pourront ainsi bénéficier d’une réduction significative de la bande passante et du temps de téléchargement lors de la mise à jour de fichiers volumineux.
Des cas d’utilisation concrets
Les innovations majeures que XetHub apporte sont la gestion des fichiers fragmentés et la déduplication. Par exemple, dans un scénario où un fichier Parquet de 10 Go nécessite une mise à jour d’une seule ligne, les utilisateurs ne devront plus télécharger l’intégralité du fichier, mais seulement les fragments modifiés. Cette fonctionnalité est cruciale à une époque où les modèles d’IA atteignent des tailles inédites, comme le nouveau modèle BigLlama-3.1-1T de Maxime Labonne.
De même, la mise à jour de fichiers de modèle GGUF, où une simple modification de métadonnées dans un dépôt Llama 3.1 405B pouvait auparavant nécessiter le téléchargement de plusieurs gigaoctets, sera désormais possible en quelques secondes.
Yucheng Low conclut :
“Avec toute l’équipe de XetHub, je suis très enthousiaste à l’idée de rejoindre Hugging Face et de poursuivre cette mission visant à faciliter la collaboration et le développement de l’IA – en intégrant la technologie XetHub dans Hub – et à proposer ces fonctionnalités à la plus grande communauté ML au monde !”
Hugging Face renforce son infrastructure IA avec l'acquisition de XetHub
L’appel à projets “Concours d’innovation i-Nov” est un dispositif de soutien financé par le plan France 2030 qui a pour vocation de sélectionner des projets d’innovation à fort potentiel pour l’économie française. Pour cette 14ème édition, les projets attendus devront porter sur quatre thématiques : le numérique, la santé, les transports, mobilités, villes et bâtiments durables ainsi que les énergies, ressources et milieux naturels. Les candidatures sont ouvertes aux startups et aux PME jusqu’au 1er octobre prochain.
Favoriser l’émergence de champions nationaux
Hydrogène décarboné, agroalimentaire, santé, mobilités, matériaux de construction et villes durables, métaux critiques ou encore technologies numériques : autant de secteurs stratégiques couverts par le volet I-Nov des Concours d’innovation. Financé par l’État via France 2030 et opéré par Bpifrance en collaboration avec l’ADEME, ce dispositif pérenne et éprouvé a déjà récompensé 692 lauréats depuis 2017. Il soutient des projets innovants portés par des start-up et des PME, favorisant ainsi l’émergence d’entreprises leaders dans leur domaine à l’échelle mondiale.
Une ambition soutenue par des concours complémentaires
Cette nouvelle édition s’inscrit dans la continuité des Concours d’innovation, qui se déclinent autour de trois volets complémentaires : i-PhD, i-Lab et i-Nov. Ces concours marquent un engagement fort et durable de l’État via des financements, une labellisation et une communication renforcée. Ils visent à soutenir le développement d’entreprises fortement innovantes et technologiques, écoresponsables et œuvrant pour une société plus durable. En amont de la chaîne de valeur des innovations, les concours i-PhD et i-Lab encouragent l’émergence et la création de start-up deep tech issues des avancées de la recherche de pointe française.
Quatre thématiques pour la 14ème vague du volet I-Nov
Le volet I-Nov cofinance des projets de recherche, développement et innovation dont les coûts totaux se situent entre 1 et 5 millions d’euros, et dont la durée est comprise entre 12 et 36 mois. Les projets doivent démontrer une réelle prise en compte de la transition énergétique et écologique et être déposés par un porteur unique. Pour cette nouvelle édition, quatre thématiques prioritaires ont été définies :
Énergies, ressources et milieux naturels : projets portant par exemple sur le développement des énergies renouvelables, économie circulaire, stockage d’énergie, et innovations dans la production d’énergie nucléaire.
Transports, mobilités, villes et bâtiments durables : projets sur les véhicules à faibles impacts, systèmes énergétiques, optimisation des flux logistiques, et services intelligents pour la mobilité.
Santé : innovations dans les solutions thérapeutiques, dispositifs médicaux, robotique chirurgicale, jumeaux numériques, solutions logicielles pour la santé, et diagnostics innovants.
Numérique : Les projets seront évalués sur leur pertinence, caractère disruptif, modèle économique, prise en compte des enjeux éthiques, sociétaux, réglementaires, sécuritaires et environnementaux. Les projets attendus porteront par exemple sur l’IA, le big data, la cybersécurité, le cloud, l’électronique, le robotique, le quantique, la blockchain, l’EdTech, et les univers immersifs.
La production de briques réutilisables, telles que les communs numériques et les solutions open source, sera particulièrement valorisée. Toute contribution à la construction d’un bouquet technologique souverain, visant à limiter la dépendance aux technologies et ressources étrangères, sera également appréciée.
Le périmètre et les orientations spécifiques pour chacune de ces thématiques sont détaillés dans le cahier des charges disponible sur le site de Bpifrance.
Modalités de candidature
Les start-up et PME intéressées ont jusqu’au 1er octobre 2024 à 12h00 (midi, heure de Paris) pour déposer leur candidature. Toutes les informations nécessaires et les documents requis sont accessibles sur le site de Bpifrance : Appel à projets – Concours d’innovation i-Nov.
France 2030 lancement de l'AAP de la 14ème édition du concours d'innovation I-Nov
Qonto, un des leaders européens de la gestion financière pour les PME (petites et moyennes entreprises, comptant jusqu’à 250 salariés) et les indépendants, a dévoilé son troisième rapport sur les habitudes de dépenses de ses plus de 500 000 clients en France, en Allemagne, en Italie et en Espagne. Cette édition met en lumière une augmentation notable des investissements des PME et des freelances européens dans l’IA.
Fondée en 2016 par Alexandre Prot et Steve Anavi, Qonto est une fintech française visant à simplifier la gestion financière et administrative des entreprises. Depuis sa création, elle a connu une croissance rapide et a levé, lors de plusieurs séries de fonds, un total de 622 millions d’euros pour se développer sur le marché européen et améliorer ses services. En 2021, elle a été la première néobanque à intégrer l’indice next40 du programme French Tech Next40/120, et depuis, y figure chaque année. Elle compte aujourd’hui plus de 500 000 clients et emploie 1 400 personnes.
Cette étude a été réalisée entre janvier 2023 et mars 2024. La répartition des secteurs est basée sur les valeurs de la Nomenclature statistique des activités économiques dans la Communauté européenne (NACE), un système de classification des activités économiques utilisé dans l’Union européenne. L’analyse des données a porté sur le nombre moyen de transactions effectuées par carte bancaire par entreprise, ainsi que sur les montants moyens dépensés pour chaque transaction, en tenant compte des paiements par carte et des virements bancaires.
Adoption croissante de l’IA par les PME européennes
L’analyse de Qonto montre que l’utilisation des outils d’IA parmi les PME en Europe a nettement augmenté, passant de moins de 1 % des entreprises utilisant au moins une solution d’IA au premier trimestre 2023 à 8 % au premier trimestre 2024. En France, l’adoption de l’IA a suivi une tendance similaire, avec une croissance marquée de moins de 1 % à presque 8 % sur la même période.
La domination d’OpenAI sur le marché de l’IA
Le rapport révèle également que parmi les différents acteurs de l’IA, OpenAI domine nettement le marché, captant 80 % de part de marché parmi les clients de Qonto. Cette part de marché est en forte hausse par rapport aux 60 % enregistrés l’année précédente. Toutefois, des entreprises comme Midjourney, Mistral, Elevenlabs et Scaleway voient également une augmentation de leur base d’utilisateurs professionnels, indiquant une diversification des préférences et des besoins en matière d’IA.
Philippine Rougevin-Baville, Directrice Générale France chez Qonto, commente :
“Ces tendances mettent en évidence non seulement la résilience et l’adaptabilité des PME européennes, mais aussi le rôle crucial de la technologie dans la future gestion des opérations commerciales. Cela montre également que, lorsqu’elles disposent d’outils numériques utiles, les PME tendent à les utiliser de plus en plus”.
En réponse à cette demande croissante pour des solutions technologiques, Qonto a récemment lancé un outil de création de logo d’entreprise assisté par IA. En seulement deux mois, cette fonctionnalité a déjà été adoptée par 35 % des clients de Qonto, illustrant la rapidité avec laquelle les entreprises intègrent de nouvelles technologies dans leurs opérations quotidiennes.
Rapport Qonto 2024 une nette augmentation de l'utilisation de l'IA au sein des PME françaises et européennes
Snowflake annonce qu’il héberge et optimise la collection de LLM Llama 3.1 dans sa plateforme Snowflake Cortex AI, offrant aux entreprises un accès sécurisé et sans serveur au modèle open source le plus avancé de Meta, Llama 3.1 405B. Parallèlement, la société rend open source sa pile d’optimisation d’inférence et de fine-tuning pour les grands modèles de langage, démocratisant ainsi l’accès aux IA génératives pour les entreprises et la communauté open source.
Lancée en novembre dernier, Snowflake Cortex AI est une suite de fonctionnalités d’IA entièrement gérées, conçues pour permettre aux entreprises de créer et de déployer des applications d’IA génératives de manière sécurisée et sans serveur. Le service propose une interface de développement sans code, accessible aux utilisateurs de tous niveaux techniques. Il donne accès à des LLM de pointe, notamment ceux de Mistral AI, de Google et AI21 Labs, mais également à Snowflake Arctic, à Llama 3 (8B et 70B), aux LLM Reka-Core et désormais à la famille Llama 3.1.
Une collaboration stratégique pour l’innovation
Développée en collaboration avec des acteurs clés de l’IA, dont DeepSpeed, Hugging Face et vLLM, la pile d’optimisation de Snowflake offre des outils et des technologies pour optimiser l’inférence et le fine-tuning des LLMs de manière efficace et rentable. Cette initiative s’inscrit dans le cadre de l’engagement de Snowflake à fournir des solutions de pointe en matière d’intelligence artificielle tout en favorisant l’innovation ouverte.
Caractéristiques techniques et avantages
Optimisation de l’Inférence
Réduction de la latence : La pile permet de réduire la latence d’inférence jusqu’à trois fois par rapport aux solutions open source existantes, offrant ainsi une performance en temps réel indispensable pour les applications critiques ;
Augmentation du débit : Avec une amélioration du débit de 1,4 fois, les utilisateurs peuvent traiter un volume plus important de requêtes en moins de temps, optimisant ainsi l’efficacité opérationnelle.
Fine-tuning efficace
Utilisation minimale de ressources : Le fine-tuning des modèles massifs peut désormais être réalisé en utilisant un seul nœud GPU, réduisant considérablement les coûts et la complexité.
Support de fenêtres de contexte étendu : Avec une prise en charge des fenêtres de contexte allant jusqu’à 128K, les modèles peuvent gérer des contextes plus larges et produire des résultats plus cohérents et pertinents.
Llama 3.1 405B a ainsi été optimisé pour l’inférence en temps réel et à haut débit avec une fenêtre de contexte massive de 128K à l’aide d’un seul nœud GPU au sein de Cortex AI.
Vivek Raghunathan, VP of AI Engineering chez Snowflake, commente :
“Nous ne nous contentons pas de fournir les modèles de pointe de Meta à nos clients via Snowflake Cortex AI. Nous armons les entreprises et la communauté de l’IA avec de nouvelles recherches et un code open source supportant des fenêtres de contexte de 128K, l’inférence multi-nœuds, le parallélisme de pipeline, la quantization en virgule flottante de 8 bits, et bien plus, afin de faire progresser l’intelligence artificielle pour l’écosystème global.”
Engagement en matière de sécurité et de confiance
Snowflake a également intégré des mécanismes de sécurité avancés dans sa pile open source avec Snowflake Cortex Guard. Pour développer cette nouvelle fonctionnalité, l’entreprise a utilisé Llama Guard 2 de Meta, qui recourt à des algorithmes avancés pour détecter et filtrer automatiquement les contenus potentiellement nuisibles, offensants ou inappropriés dans les sorties des modèles de langage. Les applications d’IA construites sur cette pile sont ainsi protégées contre les contenus nuisibles.
Ryan Klapper, leader IA chez Hakkoda, assure :
“La sécurité et la confiance sont des impératifs business lorsqu’il s’agit d’exploiter l’intelligence artificielle générative, et Snowflake nous offre les garanties nécessaires pour innover et utiliser à grande échelle des grands modèles de langage de pointe. La combinaison des modèles Llama de Meta au sein de Snowflake Cortex AI nous ouvre encore plus de possibilités pour des applications internes basées sur les RAG, permettant à nos parties prenantes d’accéder à des informations précises et pertinentes”.
Snowflake annonce l'intégration de Llama 3.1 et l'open source de sa pile d'optimisation d'inférence
“Assez grand”, c’est ainsi que Mistral AI a choisi d’intituler le communiqué présentant la deuxième génération de son modèle linguistique phare, le lendemain où Meta dévoilait ses modèles Llama 3.1. Par rapport à son prédécesseur, Mistral Large 2 est, selon la start-up, nettement plus performant en génération de code, en mathématiques et en raisonnement. Il fournit également une prise en charge multilingue beaucoup plus forte et des capacités d’appel de fonctions avancées.
Alors que le plus puissant modèle de la famille Llama 3.1 totalise 405 milliards de paramètres, Mistral Large 2 en compte 123. Avec une fenêtre contextuelle étendue à 128 000 jetons (32 000 pour Mistral Large) et un support pour plus de 80 langages de programmation, dont Python, Java, C, C++ et JavaScript, le modèle est conçu pour des applications complexes nécessitant une inférence à nœud unique et une gestion efficace des contextes longs. Il prend en charge des dizaines de langues, dont le français, l’allemand, l’espagnol, l’italien, le portugais, le néerlandais, le russe, le chinois, le japonais, le coréen, l’arabe et le hindi.
Il a été publié sous la licence Mistral Research License (MRL), permettant l’utilisation et la modification uniquement à des fins de recherche et d’utilisation non commerciale. Pour les utilisations commerciales nécessitant un auto-déploiement, une licence commerciale Mistral doit être acquise en contactant Mistral AI.
Génération de code et raisonnement
La première version de Mistral Large a été publiée en février dernier. La licorne a ensuite présenté en mai son premier modèle de génération de code Codestral et dernièrement, Codestral Mamba. Mistral Large 2, qui bénéficie des travaux réalisés pour ces 2 modèles, a été entraîné sur une large quantité de code. Il surpasse largement son prédécesseur et offre, selon Mistral AI, des performances égales à celles de modèles de premier plan tels que GPT-4o, Claude 3 Opus et Llama 3 405B.
En MMLU, il atteint une précision de 84,0 % sur le benchmark pré-entraîné, établissant un nouveau standard de performance/coût. Un effort particulier a été consacré à minimiser les “hallucinations” du modèle, ces moments où l’IA génère des informations incorrectes ou non pertinentes. Le résultat est un modèle plus prudent et perspicace, offrant des réponses fiables et précises.
Précision des performances de Mistral Large sur MultiPL-E (capacité du modèle à générer du code correct et fonctionnel dans plusieurs langages de programmation).
Raisonnement mathématique : précision des performances sur les benchmarks des générations GSM8K (8 coups) et MATH (0 coup, sans CoT).
Performance sur MMLU multilingue (mesurée sur le modèle de fondation pré-entraîné)
Suivi des instructions et conversations longues
Les capacités de Mistral Large 2 en matière de suivi des instructions et de gestion des conversations longues ont été considérablement améliorées. Le modèle excelle dans le suivi des instructions précises et dans la gestion des interactions complexes sur plusieurs tours, ce qui le rend particulièrement adapté pour des applications commerciales nécessitant des réponses succinctes et précises.
D’autre part, ses compétences améliorées en matière d’appel et de récupération de fonctions et sa capacité à exécuter efficacement des appels de fonctions parallèles et séquentiels, le rendent très utile pour des applications professionnelles complexes.
Disponibilité
Mistral Large 2, que l’on peut tester gratuitement sur Le Chat de Mistral AI, est dès à présent disponible via la Plateforme de la start-up sous la version 24.07 et les plateformes Google Cloud Platform, Azure AI Studio, Amazon Bedrock et IBM watsonx.ai. Les poids du modèle instruct sont hébergés sur HuggingFace.
Mistral Large 2 des capacités de génération de code, en mathématiques et en raisonnement de pointe
NVIDIA annonce le lancement d’un nouveau service NVIDIA AI Foundry qui permettra aux entreprises d’utiliser la nouvelle famille Llama 3.1 pour créer des modèles personnalisés avec leurs données propriétaires ainsi que des données synthétiques générées par Llama 3.1 405B et le modèle NVIDIA Nemotron.
Le service couvre la curation, la génération de données synthétiques, le réglage fin, la récupération, les garde-fous et l’évaluation pour déployer des microservices NVIDIA NIM Llama 3.1 personnalisés avec les nouveaux microservices NVIDIA NeMo Retriever introduits le 23 juillet dernier pour des réponses précises.
NVIDIA avait lancé NVIDIA AI Foundry, une plateforme permettant de créer des modèles d’IA génératifs personnalisés avec des données d’entreprise et des connaissances spécifiques à un domaine, en novembre dernier sur Microsoft Azure. Ce service rassemblait trois éléments : une collection de modèles de base d’IA NVIDIA, le cadre et les outils NeMo de NVIDIA ainsi que les services de calcul intensif d’IA dans le cloud NVIDIA DGX, afin d’offrir aux entreprises une solution de bout en bout pour créer des modèles d’IA génératifs personnalisés.
Aujourd’hui, les entreprises peuvent utiliser le nouveau service AI Foundry pour personnaliser les modèles communautaires y compris la nouvelle collection Llama 3.1, ainsi que NVIDIA Nemotron, CodeGemma de Google DeepMind, CodeLlama, Gemma de Google DeepMind, Mistral, Mixtral, Mistral NeMo 12b, présenté il y a quelques jours, Phi-3, StarCoder2 et d’autres.
Les clients peuvent générer leurs modèles AI Foundry sous forme de microservices d’inférence NVIDIA NIM (NeMo Inference Microservices), qui incluent le modèle personnalisé, des moteurs optimisés et une API standard, pour s’exécuter sur l’infrastructure accélérée de leur choix. Ces microservices permettent une exécution rapide et efficace des modèles d’IA en production, avec des améliorations significatives des performances par rapport aux méthodes d’inférence traditionnelles.
Comment fonctionne NVIDIA AI Foundry ?
NVIDIA AI Foundry utilise des données d’entreprise, ainsi que des données générées synthétiquement, pour augmenter et modifier les connaissances générales contenues dans un modèle de fondation pré-entraîné. Une fois que le modèle est personnalisé, évalué et doté de garde-fous, il est généré en tant que microservice d’inférence NIM de la plateforme NVIDIA AI Enterprise 5.0 introduite en mars dernier lors de la GTC 2024. Les développeurs utilisent l’API standard du NIM pour créer des applications génératives alimentées par l’IA. Les connaissances acquises à partir des applications en cours de déploiement peuvent être réinjectées dans AI Foundry afin d’améliorer encore les modèles personnalisés.
Accenture, Aramco, AT&T, Uber sont parmi les premiers à utiliser les nouveaux microservices Llama NVIDIA NIM.
NVIDIA AI Foundry intègre Llama 3.1 pour aider les entreprises à créer des modèles personnalisés
Qlik, acteur mondial de l’intégration de données, de l’analytique et de l’IA, a annoncé l’extension de son partenariat avec la Convention-cadre des Nations Unies sur les changements climatiques (CCNUCC). Cette collaboration vise à renforcer les capacités de la CCNUCC à accélérer les négociations climatiques en utilisant des données fiables et des analyses avancées.
Adoptée lors du “Sommet de la Terre de Rio” en 1992, la CCNUCC est entrée en vigueur le 21 mars 1994 et a été ratifiée par 197 pays, appelés Parties à la Convention . Elle reconnaît la vulnérabilité de tous les pays aux effets du changement climatique et appelle à des efforts particuliers pour en atténuer les conséquences, notamment dans les pays en développement qui n’ont pas les moyens de le faire seuls.
Tous les ans, une Conférence des Parties (COP) est organisée pour évaluer les progrès réalisés dans la lutte contre le changement climatique et pour négocier de nouveaux engagements. C’est lors de la COP21, en décembre 2015 à Paris, qu’a été adopté l’Accord de Paris. Cet accord vise à limiter l’augmentation de la température mondiale “à bien en dessous de 2°C par rapport aux niveaux préindustriels” et à poursuivre les efforts pour “limiter cette augmentation à 1,5°C”.
Les 196 Parties signataires de l’Accord de Paris doivent soumettre des contributions déterminées au niveau national (CDN) décrivant leurs plans pour réduire les émissions de gaz à effet de serre. Face à l’augmentation exponentielle des relevés effectués et des documents produits, la CCNUCC a entamé un processus visant à exploiter les données et l’IA en vue de renforcer les initiatives en matière d’action climatique.
Les objectifs du partenariat avec Qlik
Cette collaboration a pour objectif d’améliorer la capacité de la convention à accélérer les négociations relatives au changement climatique en favorisant la prise de mesures fondées sur les données.
La CNUCC dispose de données régulières sur les émissions de GES, les politiques et les mesures des pays, les progrès accomplis dans la réalisation des objectifs, les impacts du changement climatique et l’adaptation, les niveaux de soutien et les besoins en matière de renforcement des capacités.
Les solutions avancées de Qlik lui permettent de mieux gérer et réconcilier ces vastes quantités de données dont la qualité et le contexte varient souvent d’un pays à l’autre, ainsi que d’améliorer la transparence et la qualité des rapports climatiques.
Exemples concrets du partenariat
Intégration des données : Les applications de Qlik sont associées au référentiel de données de la CCNUCC pour former une plateforme unifiée d’accès et d’analyse des données ;
Tableaux de bord publics : Les tableaux de bord interactifs développés permettent de présenter des données climatiques au grand public de façon à la fois précise et transparente ;
Renforcement des compétences : Des formations sont dispensées aux collaborateurs de la CCNUCC pour améliorer leur niveau de data literacy et faciliter l’utilisation des produits Qlik ;
Intégration de l’IA : L’analyse continue de l’IA est incorporée dans les applications analytiques de la CCNUCC pour une meilleure compréhension de la crise climatique.
Joaquim Barris, data scientist de la CCNUCC, explique :
“Le partenariat avec Qlik nous permet d’accomplir des progrès significatifs dans nos initiatives d’action climatique en nous appuyant sur des outils avancés d’intégration de données et d’IA. Cette collaboration nous permettra de prendre des mesures plus immédiates fondées sur les données, ainsi que de mieux comprendre nos données diplomatiques, politiques et climatiques. Nous nous réjouissons tout particulièrement d’explorer la capacité de l’IA à analyser des données de tous types, y compris non structurées. L’importance que Qlik accorde aux socles de données et analytique en fait un partenaire idéal pour exploiter pleinement le potentiel de l’intelligence artificielle”.
Julie Kae, VP Sustainability & DEIB, et Executive Director de Qlik.org, ajoute :
“C’est un grand honneur pour Qlik de soutenir la CCNUCC dans sa mission de lutte contre le changement climatique. En intégrant nos solutions de données et d’IA, nous souhaitons fournir à la CCNUCC les outils nécessaires pour aider les pays à mettre en œuvre des politiques climatiques efficaces et opportunes”.
Qlik et la CCNUCC un partenariat renforcé pour accélérer l'action climatique
La stratégie d’IBM consiste à proposer à la fois des modèles d’IA tiers et ses propres modèles sur sa plateforme watson.ai, certains sont open source, d’autres des modèles propriétaires. La société élargit son catalogue de modèles watsonx.ai avec Mistral Large, le modèle de génération de texte le plus puissant de la licorne française Mistral AI.
La start-up fait partie des partenaires stratégiques d’IBM qui a d’ailleurs participé à sa dernière levée de fonds. Mistral Large va venir rejoindre la version optimisée du modèle ouvert Mixtral-8x7B sur watsonx.ai qui héberge également les modèles open source Llama de Meta, notamment Llama3, ou le LLM de langue arabe ALLaM de la Saudi Data and AI Authority (SDAIA). On peut y retrouver également la famille de modèles de fondation Granite développés par IBM Research, qui inclut des modèles de code open-source, des modèles de langage et des modèles scientifiques pour les séries temporelles et les données géospatiales.
Une protection de la propriété intellectuelle
Conformément à son engagement envers une innovation responsable, IBM offrira également une indemnisation plafonnée pour la propriété intellectuelle de Mistral Large. Il s’agit du premier modèle de fondation tiers à bénéficier de cette protection, soulignant l’importance qu’IBM accorde à la sécurité et à la confiance de ses clients dans l’utilisation de ses technologies d’IA.
Fonctionnalités avancées de Mistral Large
Mistral Large apporte plusieurs fonctionnalités clés qui peuvent transformer les opérations d’entreprise :
Optimisation du RAG : Amélioration de l’interaction conversationnelle et du traitement de documents volumineux, permettant des analyses plus approfondies ;
Appel de fonction : Intégration facilitée avec des outils externes et des APIs, offrant des possibilités illimitées pour créer des applications personnalisées ;
Expertise en codage : Capacités avancées pour générer, réviser et commenter du code, avec des résultats en format JSON pour une interaction plus naturelle avec les développeurs ;
Capacités multilingues : Support natif pour le français, l’allemand, l’espagnol et l’italien, en plus de l’anglais, et compatibilité avec des dizaines d’autres langues ;
IA responsable : Garde-fous intégrés pour assurer une utilisation sécurisée et éthique de l’IA.
Une plateforme flexible et intégrée
Le studio d’IA IBM watsonx.ai fait partie de la plateforme d’IA et de données IBM watsonx, il permet aux entreprises d’entraîner, valider, ajuster et déployer des modèles d’IA. Pour ce faire, il propose une gamme de produits prêts à l’emploi, notamment un entrepôt de données de type Lakehouse, un laboratoire d’invite (Prompt Lab), un Tuning Studio, et des capacités de supervision des environnements de production et de gouvernance IA.
Sa flexibilité permet aux entreprises de déployer les modèles disponibles dans l’environnement de leur choix, que ce soit sur site ou chez un fournisseur de Cloud public, évitant ainsi des investissements coûteux en infrastructure.
IBM annonce la disponibilité de Mistral Large sur watsonx.ai
Mistral AI a annoncé ce 16 juillet dernier deux nouveaux LLM publiés sous licence Apache 2.0 : Codestral Mamba 7B et Mathstral 7B. Le premier utilise la nouvelle architecture Mamba introduite fin 2023 par les chercheurs de renom Albert Gu et Tri Dao, et est destiné à la génération de code comme son prédécesseur Codestral. Mathstral, basé sur Mistral 7B, est un modèle spécialisé dans les tâches mathématiques et scientifiques, développé dans le cadre de la collaboration de Mistral AI avec le Projet Numina.
Codestral Mamba 7B : une architecture innovante
Codestral Mamba se distingue par une approche radicalement différente de celle des modèles Transformer traditionnels. Mistral AI explique :
“Contrairement aux modèles Transformer, les modèles Mamba offrent l’avantage de l’inférence temporelle linéaire et la capacité théorique de modéliser des séquences de longueur infinie. Ils permettent aux utilisateurs d’interagir de manière approfondie avec le modèle avec des réponses rapides, quelle que soit la longueur d’entrée. Cette efficacité est particulièrement pertinente pour les cas d’utilisation de la productivité du code. C’est pourquoi nous avons formé ce modèle avec des capacités avancées de code et de raisonnement, lui permettant d’être aussi performant que les modèles basés sur les transformateurs SOTA”.
Performances du modèle
Codestral Mamba a été soumis à des benchmarks détaillés, testant sa capacité de récupération contextuelle jusqu’à 256 000 jetons. Les résultats confirment son potentiel en tant qu’assistant de code local et sa capacité à gérer des tâches complexes.
Le modèle a démontré des performances supérieures aux modèles open source concurrents CodeLlama 7B, CodeGemma-1.17B et DeepSeek dans les tests HumanEval.
Disponibilité
Codestral Mamba a été publié sous la licence Apache 2.0, offrant une liberté complète d’utilisation et de modification. Il est disponible à des fins de tests sur la plateforme de Mistral AI et sur Hugging Face, où il peut être déployé en utilisant le SDK mistral-inférence, qui s’appuie sur les implémentations de référence du dépôt GitHub de Mamba. Il peut également l’être sur TensorRT-LLM pour ceux qui préfèrent cette option de déploiement et bientôt sur llama.cpp pour l’inférence locale.
Mathstral 7B : une avancée dans les problèmes mathématiques complexes
Mathstral est une contribution significative de Mistral AI à la communauté scientifique, destinée à résoudre des problèmes mathématiques avancés nécessitant un raisonnement logique complexe et multi-étapes.
Basé sur Mistral 7B, disposant d’une fenêtre contextuelle de 32 000 jetons, Mathstral excelle dans les matières STEM, atteignant des performances de pointe dans sa catégorie. Il a obtenu 56,6 % sur MATH et 63,47 % sur MMLU.
Avec un calcul plus intensif au moment de l’inférence, le modèle peut atteindre des scores encore plus élevés : MATH avec vote majoritaire: 68,37%, MATH avec un modèle de récompense fort parmi 64 candidats: 74,59%.
Mathstral illustre les excellents compromis performance/vitesse obtenus en construisant des modèles pour des objectifs spécifiques, une philosophie que Mistral AI promeut activement. Les poids de Mathstral sont disponibles sur HuggingFace, et le modèle peut être utilisé tel quel ou affiné avec mistral-inference et mistral-finetune.
Mistral AI annonce deux nouveaux modèles open source Codestral Mamba 7B et Mathstral 7B
Teradata, plateforme d’analyse et de données cloud, annonce l’intégration de la plateforme d’IA DataRobot à ses produits Teradata VantageCloud et ClearScape Analytics. Cette collaboration vise à optimiser l’utilisation de l’IA, en donnant aux entreprises davantage de moyens et de flexibilité pour développer et mettre en œuvre des modèles d’IA performants et sécurisés à grande échelle.
En 2022, Teradata a annoncé le lancement de Teradata VantageCloud et Teradata VantageCloud Lake, offrant aux entreprises une plateforme complète d’analyse et de données dans le cloud pour résoudre leurs défis commerciaux les plus importants, tout en accélérant les résultats pour de nombreux cas d’utilisation.
Elle a également dévoilé ClearScape Analytics, qui élevait ses capacités d’analyse en introduisant plus de 50 nouvelles séries chronologiques et fonctions ML dans la base de données, ainsi que des ModelOps intégrés conçus pour opérationnaliser rapidement les initiatives d’IA/ML.
Cette plateforme permet aux entreprises d’exploiter pleinement leurs données pour des analyses prédictives, descriptives et prescriptives, facilitant ainsi la prise de décisions éclairées et la maximisation de la valeur des données.
Le partenariat avec DataRobot
Fondée en 2012, DataRobot propose une plateforme complète de machine learning automatisé qui permet aux entreprises de construire, déployer et gérer des modèles d’IA de manière rapide et efficace. Elle prend en charge une large gamme de modèles, y compris les modèles prédictifs et génératifs, permettant ainsi aux entreprises de résoudre divers types de problèmes analytiques.
La plateforme offre une intégration facile avec divers environnements de données et outils analytiques. L’intégration avec Teradata permettra aux clients de tirer pleinement parti des capacités des deux entreprises.
Daniel Spurling, vice-président senior de la gestion des produits chez Teradata, explique :
“DataRobot est connu pour ses modèles précis et de haut niveau, et VantageCloud offre l’évolutivité et l’efficacité incroyables dont les entreprises modernes ont besoin. Ensemble, les résultats d’un modèle large peuvent être explicables, gouvernés et exploitables. Le potentiel de l’IA augmente rapidement, et Teradata et DataRobot ouvrent la voie aux organisations pour accélérer l’adoption de l’IA de confiance, à une échelle qui compte”.
Les avantages pour les utilisateurs
Opérationnalisation à grande échelle : Grâce à la fonctionnalité Bring Your Own Model (BYOM) de ClearScape Analytics, les utilisateurs peuvent importer et opérationnaliser les modèles d’IA de DataRobot directement dans VantageCloud. Cela permet un accès plus rapide aux données et aux résultats, accélérant ainsi l’innovation ;
Flexibilité pour les data scientists : DataRobot offre une plateforme complète pour le cycle de vie de l’IA, permettant aux data scientists d’utiliser leurs outils et technologies préférés. Cette flexibilité est cruciale pour tirer parti des dernières innovations en IA ;
Déploiement économique et sécurisé : Teradata VantageCloud permet le déploiement de modèles d’IA à grande échelle dans le même environnement que celui où résident les données, sans coût de licence supplémentaire. Les entreprises peuvent ainsi contrôler les coûts tout en garantissant la responsabilité et la sécurité des modèles déployés. Le déploiement peut être effectué sur tous les fournisseurs de cloud et sur site.
Ces nouvelles fonctionnalités sont d’ores et déjà disponibles.
Teradata et DataRobot un partenariat pour accélérer l’adoption d’une IA de confiance à grande échelle
Le secteur pétrolier et gazier, traditionnellement perçu comme une industrie lourde et complexe, est actuellement en pleine transformation grâce aux progrès de l’IA et de la robotique. Selon GlobalData, une entreprise leader dans le domaine des données et de l’analytique, ces technologies révolutionnaires redéfinissent les normes de productivité, d’efficacité, de durabilité et de sécurité dans ce secteur clé de l’économie mondiale.
Basée à Londres, créée en 1999, GlobalData est une entreprise d’analyse de données et de conseil. Elle fournit des analyses commerciales et des données exclusives à différents secteurs, notamment ceux de la santé, de la consommation, de la vente au détail, de la finance, de la technologie et des services professionnels.
Son dernier rapport, intitulé “Cognitive Energy: Transforming Oil & Gas with AI and Robotics”, fait partie d’une série en cours sur le secteur pétrolier et gazier.
Saurabh Daga, chef de projet pour la technologie disruptive chez GlobalData, souligne le rôle clé de ces technologies pour le secteur :
“L’IA et la robotique apportent des changements profonds et étendus dans le secteur pétrolier et gazier, redéfinissant fondamentalement ce qui est possible. Ces technologies nous aident à surmonter des défis allant de la réduction des coûts à l’amélioration de la sécurité et de la durabilité, établissant de nouvelles références en matière d’efficacité et d’innovation. Des opérations autonomes, à l’optimisation du forage, en passant par les inspections d’usines et l’optimisation des flottes, elles transforment les opérations en amont, intermédiaires et en aval, repoussant les limites de l’efficacité et de l’innovation”.
Innovations clés et applications pratiques
Le rapport de GlobalData présente plus de 50 innovations concrètes de l’IA et de la robotique, démontrant leur impact révolutionnaire sur les différents aspects du secteur. Il explore également des domaines émergents tels que l’IA générative et la robotique d’inspection de pipelines avec des exemples pratiques de l’industrie.
Voici quelques exemples illustrant ces avancées :
Réduction des émissions de carbone : SLB (anciennement Schlumberger) et INEOS Energy se sont associés pour intégrer des capacités d’IA via la plateforme numérique Delfi de SLB. Cette collaboration vise à améliorer la performance opérationnelle dans l’ensemble des opérations pétrolières et gazières, de capture et stockage du carbone (CSC), et de nouvelles acquisitions. Elle marque une avancée majeure vers des solutions énergétiques durables et à faible émission de carbone, en particulier dans la région de la mer du Nord.
Forage de précision : Shell a mis en œuvre une technologie d’IA générative pour optimiser ses opérations de forage offshore. En collaboration avec la startup texane SparkCognition, Shell utilise cette technologie propriétaire conjointe pour améliorer ses capacités d’exploration et de forage en mer profonde.
Inspections Offshore : Petrobras a recours à des robots d’inspection autonomes ANYmal X, développés par ANYbotics, pour automatiser les inspections de ses installations offshore. Cette initiative permet de réduire les risques pour les travailleurs et d’améliorer l’efficacité des inspections.
Robots d’inspection de pipelines : Kawasaki Heavy Industries, en collaboration avec TotalEnergies, a testé un véhicule sous-marin autonome (AUV) nommé SPICE pour l’inspection des pipelines sous-marins. Ce robot, équipé d’un bras robotique, est conçu pour répondre aux besoins croissants de maintenance des infrastructures sous-marines.
Vers un avenir plus vert et plus efficace
L’adoption de l’IA et de la robotique dans le secteur pétrolier et gazier ne se limite pas seulement à l’amélioration des opérations existantes. Elle ouvre également la voie à un avenir plus durable et plus respectueux de l’environnement. Ces technologies avancées permettent une meilleure gestion des ressources, une réduction des émissions de carbone et une amélioration significative de la sécurité sur les sites d’exploitation.
Saurabh Daga conclut :
“L’avenir du secteur pétrolier et gazier dépend de l’IA et de la robotique sur l’ensemble de sa chaîne de valeur. Les défis tels que l’intégration des données, les réglementations de sécurité et la main-d’œuvre qualifiée nécessitent des solutions collaboratives et des investissements stratégiques en R&D. Surmonter ces obstacles permettra de débloquer l’efficacité, la durabilité et l’innovation dans le secteur”.
Pour retrouver le rapport de Globaldata, cliquer ici.
Globaldata l'IA et la robotique débloquent une efficacité durable dans le secteur pétrolier et gazier
Sopra Steria Next, le cabinet de conseil dédié à l’accompagnement des entreprises dans leur transformation numérique du groupe français Sopra Steria, a collaboré avec Microsoft pour accélérer le déploiement de Copilot pour Microsoft 365. L’offre sur mesure résultant de cette collaboration, qui vise à promouvoir l’adoption de l’IA générative au sein des entreprises, sera prochainement disponible sur la marketplace de Microsoft.
Selon une étude de Sopra Steria Next, le marché de la GenAI devrait connaitre une croissance exponentielle d’ici 2028, passant d’environ 8 milliards de dollars en 2023 à plus de 100 milliards en 2028.
L’assistant IA Copilot de Microsoft a commencé à être déployé dans le cadre de la mise à jour gratuite de Windows 11 en septembre 2023, avant de l’être sur Bing, désormais rebaptisé Copilot, Edge et Microsoft 365. En janvier dernier, Microsoft annonçait le lancement de Copilot Pro, une offre premium à destination des particuliers et des entreprises.
Copilot, qui utilise les modèles d’IA générative d’OpenAI, est intégré à différentes applications Microsoft 365, notamment à :
Word : Pour la génération de texte, la création de contenu, les résumés, et les suggestions de mise en forme ;
Excel : Pour les suggestions de formules, de différents types de graphiques, et l’analyse des données ;
PowerPoint : Pour la création de présentations à partir de fichiers Word ou d’invites, l’ajout de diapositives et d’images ;
Outlook : Pour le résumé des e-mails, la génération de réponses, et l’organisation des tâches ;
Teams : Pour l’organisation des réunions, la gestion des conversations, et la collaboration en temps réel.
Les premières entreprises à l’avoir utilisé reconnaissent un gain de productivité : 70 % des utilisateurs de Copilot ont déclaré qu’ils étaient plus productifs et 68 % qu’il améliorait la qualité de leur travail, selon un rapport publié par Microsoft en novembre dernier. Cependant son adoption est encore un défi pour certaines autres, Sopra Steria Next entend les accompagner dans cette démarche.
Fabrice Asvazadourian, directeur général de Sopra Steria Next, explique :
“Copilot pour Microsoft 365 est un outil certes extraordinaire, mais sans un accompagnement adéquat, le potentiel de productivité peut rester sous-exploité. Avec cette approche, nous proposons de transformer une innovation en résultats tangibles, et de placer la formation et le management au cœur de la réussite de l’intelligence artificielle générative en entreprise”.
Trois conditions de succès
L’offre de Sopra Steria Next pose trois conditions de succès à la bonne adoption de l’IA générative en entreprise, organisées autour de trois axes :
L’humain : Donner les clés de compréhension et d’utilisation aux collaborateurs pour un usage responsable de l’IA, via des séminaires et des ateliers d’exploration de cas d’usages ;
La technologie : Garantir un déploiement optimal de Copilot pour Microsoft 365 grâce à des audits et analyses d’impact de l’IA sur les secteurs d’activité, permettant de concevoir une stratégie de déploiement et d’accompagnement personnalisée ;
Le business : Mesurer la performance et les gains pour l’entreprise afin d’effectuer les ajustements nécessaires pour ancrer durablement l’utilisation de l’IA générative dans le quotidien des équipes.
Philippe Clapin, directeur général de Sopra Steria Next France, conclut :
“Alors que le marché de l’IA générative entame son passage à l’échelle et sa monétisation, nous sommes particulièrement fiers de faire partie des premiers cabinets de conseil en France à proposer un tel accompagnement à nos clients. Aujourd’hui, beaucoup de décideurs regardent l’IA avec surprise ; notre volonté est de leur faire comprendre que c’est aujourd’hui que tout se joue, et que l’IA générative n’est pas qu’une brique technologique, c’est un nouveau paradigme dans le monde du travail”.
Sopra Steria Next-Microsoft accélérer l'adoption de l'intelligence artificielle générative avec Copilot pour Microsoft 365
Prophesee, start-up parisienne spécialisée dans les systèmes de vision artificielle basés sur l’ingénierie neuromorphique, annonce un investissement de 15 millions d’euros pour développer la prochaine génération d’IA neuromorphique dédiée aux téléphones mobiles. Ce projet, baptisé PERSEPHONE, cofinancé par Bpifrance dans le cadre de l’appel à projet “IA Embarquée” de France 2030, vise au développement d’une nouvelle génération de capteurs neuromorphiques, fabriqués en France.
La vision neuromorphique est une technologie inspirée du fonctionnement du système visuel humain, en particulier du couple œil-cerveau. Elle se base sur des capteurs et des algorithmes qui imitent la manière dont le cerveau humain traite les informations visuelles. Contrairement aux caméras traditionnelles, qui capturent des images à des intervalles de temps fixes (par exemple, 30 images par seconde), les capteurs neuromorphiques capturent les changements dans une scène de manière asynchrone, en se concentrant uniquement sur les variations locales de luminosité.
Elle est utilisée dans différents domaines comme les véhicules autonomes, la robotique, la surveillance et la sécurité, la santé et les appareils mobiles.
Appliquée aux téléphones mobiles, l’IA neuromorphique rend possible de nombreuses avancées technologiques significatives en termes de qualité d’image, de très basse consommation énergétique, de traitement beaucoup plus rapide et de confidentialité des données puisque le traitement embarqué ne nécessite pas l’utilisation et le stockage dans un cloud.
Le projet PERSEPHONE
Le projet de Prophesee permettra l’exécution de modèles avancés d’IA appliqués à la vision directement au cœur des appareils mobiles, améliorant ainsi la qualité des photos et des vidéos.
Les capteurs neuromorphiques Metavision de Prophesee se distinguent par leur capacité à capturer les mouvements dans une scène de manière continue et à des vitesses extrêmes. Chaque pixel du capteur intègre une intelligence dédiée, lui permettant d’agir comme un neurone et de s’activer de manière autonome en fonction du mouvement qu’il détecte. Cette approche innovante permet non seulement un défloutage de haute performance mais également une synchronisation parfaite entre le capteur d’image et le capteur neuromorphique, comblant ainsi les vides d’information à l’échelle de la microseconde pour extraire algorithmiquement les informations de mouvement.
Luca Verre, CEO de Prophesee commente :
“Ce nouveau financement dans le cadre de France 2030 confirme le leadership technologique de Prophesee. Avec nos partenaires de référence, nous avons l’ambition de faire émerger la nouvelle génération d’IA neuromorphique embarquée à destination du marché du téléphones mobiles où notre technologie assure un saut technologique”.
PERSEPHONE Prophesée développe une IA neuromorphique pour smartphone avec le soutien de Bpifrance
C’est par courrier qu’OpenAI a appris ce mardi 10 juillet que Microsoft avait décidé de ne plus occuper le poste d’observateur au sein de son conseil d’administration. Phil Schiller, responsable de l’App Store d’Apple, qui devait occuper un siège similaire à la suite de l’accord récent entre OpenAI et Apple pour intégrer ChatGPT dans les iPhones, ne le fera finalement pas, Apple ayant décidé de renoncer à ce poste, selon les sources du Financial Times.
Microsoft a investi massivement dans OpenAI : 13 milliards de dollars depuis 2019. Les 10 milliards investis en 2023 ont permis à la start-up de tenir financièrement alors que l’engouement autour de ChatGPT, dont seule la version gratuite existait, lui faisait perdre de l’argent. En contrepartie, Microsoft devait recevoir une partie des profits générés par OpenAI jusqu’à ce que l’investissement soit récupéré, puis obtenir 49 % de son capital.
Microsoft a obtenu ce poste d’observateur après que Sam Altman, évincé de son poste de PDG, ait réintégré sa place à la direction d’OpenAI et le conseil d’administration qui l’avait limogé, remanié. S’il pouvait participer aux réunions, il n’avait pas droit de vote.
La société écrit :
“Au cours des huit derniers mois, nous avons été témoins de progrès significatifs de la part du conseil d’administration nouvellement formé et nous sommes confiants dans la direction de l’entreprise. Compte tenu de tout cela, nous ne pensons plus que notre rôle limité d’observateur soit nécessaire”.
Selon un porte-parole d’OpenAI, la start-up réfléchit à “une nouvelle approche pour informer et impliquer ses principaux partenaires stratégiques”. Des réunions seront organisées régulièrement avec des partenaires clés tels que Microsoft et Apple ainsi que les investisseurs Thrive Capital et Khosla Ventures, afin de les informer des progrès et assurer une collaboration plus forte en matière de sûreté et de sécurité. Elles devraient être dirigées par Sarah Friar, la nouvelle directrice financière d’OpenAI.
La mainmise des grandes entreprises du secteur technologique sur le marché de l’IA générative.
Ce retrait pourrait être lié aux enquêtes des régulateurs de la concurrence américains et européens. La Federal Trade Commission a lancé en janvier dernier une enquête sur les investissements et les partenariats impliquant des start-ups d’IA générative et d’importants fournisseurs de services cloud, les investissements de Microsoft dans OpenAI en font partie.
Microsoft et Apple sont tous deux sous le viseur de la Commission européenne. Celle-ci reproche notamment à Apple les règles de l’App Store, jugées contraires au règlement sur les marchés numériques (DMA). En conséquence, Apple a décidé de ne pas lancer en Europe trois fonctionnalités prévues pour iOS 18, dont Apple Intelligence, son IA générative, en raison des obligations imposées par le DMA.
Si elle a conclu que Microsoft n’avait pas pris le contrôle sur OpenAI, elle estime qu’il enfreint les règles de concurrence de l’UE en liant son application Teams à Word et Excel.
Microsoft abandonne son poste d'observateur au conseil d'administration d'OpenAI, Apple renonce au sien
Le ministère japonais de la Défense a dévoilé le 2 juillet dernier sa première politique de base sur l’utilisation de l’intelligence artificielle. Celle-ci devrait lui permettre de faire face à la pénurie de main-d’oeuvre à laquelle est confrontée le pays et de ne pas se laisser distancer par des puissances mondiales comme la Chine et les États-Unis en matière d’applications militaires de l’IA.
En 2022, face aux tensions géopolitiques régionales (menaces nucléaires de la Corée du Nord, pressions de la Chine sur Taïwan) et mondiales (guerre entre la Russie et l’Ukraine), le Japon a révisé sa Stratégie de sécurité nationale (NSS) adoptée en 2013 pour renforcer la défense nationale et promouvoir la paix et la stabilité de la région. Il a décidé de doubler son budget de la défense d’ici 2027, d’investir dans des technologies avancées et de renforcer les capacités des FAD (Forces japonaises d’autodéfense).
L’annonce du ministère de la Défense survient alors que les FAD peinent à recruter et manquent de capacités pour exploiter la puissance des nouvelles technologies. La nouvelle politique de l’IA vise à remédier à ces défis en priorisant son application dans plusieurs domaines clés où elle permettra “d’accélérer la prise de décision, assurer la supériorité des capacités de collecte et d’analyse d’informations, réduire la charge du personnel et économiser la main-d’œuvre”.
Les sept domaines prioritaires identifiés sont la détection et l’identification de cibles à l’aide d’images radar et satellites, la collecte et l’analyse de renseignements, le développement de ressources militaires sans pilote, le soutien logistique, le commandement et le contrôle, la cybersécurité et l’efficacité du travail administratif.
En observant que les États-Unis prévoient d’utiliser l’IA pour intégrer divers systèmes et analyser de grandes quantités de données afin d’améliorer la prise de décision, et que la Chine cherche à moderniser son armée en utilisant l’IA, notamment pour ses systèmes d’armes autonomes, la politique de base souligne l’urgence pour le Japon de s’adapter aux nouvelles méthodes de guerre tout en augmentant son efficacité opérationnelle.
“Nous sommes à un tournant décisif : soit nous devenons une organisation efficace et innovante grâce à l’utilisation de l’IA, soit nous restons une organisation inefficace et dépassée”, indique-t-elle.
L’Importance du contrôle humain
Toutefois, le ministère insiste sur le fait que “l’IA doit soutenir le jugement humain”. La politique stipule clairement que l’implication humaine est indispensable dans l’utilisation de l’IA, le développement de systèmes d’armes létales entièrement autonomes n’est donc pas envisagé. Cette approche vise à minimiser les risques d’erreurs et de biais, et à assurer que la technologie soit mise en œuvre conformément aux directives gouvernementales et aux discussions internationales sur la réduction des risques.
Japon le ministère de la Défense présente sa 1ère politique de base sur l'utilisation de l'IA
Des chercheurs du MIT et de l’Université de Bâle ont utilisé l’IA générative pour développer une technique basée sur la physique afin de classer les transitions de phase dans les matériaux ou les systèmes physiques. Cette méthode, nettement plus efficace que les approches d’apprentissage automatique traditionnelles, pourrait transformer la manière dont les scientifiques explorent les propriétés des matériaux. Leurs résultats ont été récemment publiés dans la revue Physical Review Letters.
Comprendre les transitions de phase
Les diagrammes de phase sont fondamentaux en physique et essentiels pour la compréhension du comportement des matériaux dans diverses conditions. Ils décrivent les états dans lesquels un matériau peut exister : l’eau, par exemple, peut être trouvée sous forme de glace, de liquide ou de vapeur. Entre ces phases, des transitions de phase se produisent en fonction de différents paramètres tels que la température ou la pression.
Les transitions de phase sont un sujet de recherche très actif, les scientifiques s’intéressent particulièrement aux transitions dans des matériaux moins conventionnels ou des systèmes complexes, tels que le passage d’un conducteur ordinaire à un supraconducteur ou d’un état non magnétique à un état ferromagnétique. Ces transitions sont détectées grâce à un “paramètre de commande” qui varie de manière significative lors du changement de phase.
Cependant, le calcul des diagrammes de phase est extrêmement complexe, reposant traditionnellement sur une expertise théorique approfondie et des techniques manuelles fastidieuses. Les systèmes physiques sont en effet constitués de nombreuses particules interagissant entre elles, créant une multitude d’états possibles, états qui étaient classés jusque-là grâce aux réseaux de neurones.
Julian Arnold, doctorant dans le groupe de Christoph Bruder de l’Université de Bâle, explique :
“Le problème est qu’un solide ou un liquide est constitué de très nombreuses particules – atomes ou molécules. Ces particules interagissent, c’est-à-dire qu’elles s’attirent ou se repoussent ; ils forment ce que l’on appelle un système à N corps. Il existe de nombreuses possibilités pour l’état général du matériau – caractérisé par la position des particules, mais aussi des propriétés supplémentaires, telles que l’orientation des spins, qui indiquent la direction de l’aimantation”.
Une nouvelle approche basée sur l’IA générative
Les chercheurs du MIT et de l’Université de Bâle ont exploité des modèles génératifs d’IA pour développer un cadre d’apprentissage automatique capable de cartographier automatiquement les diagrammes de phase des systèmes physiques. Contrairement aux classificateurs discriminants, les modèles génératifs estiment la distribution de probabilité des données et peuvent générer de nouveaux points de données qui correspondent à cette distribution, ce qui permet de construire un classificateur basé sur la physique sans nécessiter de grandes quantités de données d’entraînement.
Cette approche est inspirée de modèles d’IA générative comme ChatGPT, qui utilisent des algorithmes complexes pour générer du contenu nouveau à partir de données existantes. En appliquant cette technique aux systèmes physiques, les chercheurs peuvent estimer approximativement les distributions de probabilité des états du système, permettant une classification plus efficace et précise des phases.
Frank Schäfer, postdoctorant au laboratoire Julia du laboratoire d’informatique et d’IA (CSAIL) et co-auteur, souligne :
“C’est une très bonne façon d’incorporer quelque chose que vous savez sur votre système physique au plus profond de votre schéma d’apprentissage automatique. Cela va bien au-delà de la simple ingénierie des caractéristiques sur vos échantillons de données ou de simples biais inductifs”.
Julian Arnold teste actuellement cette méthode sur des modèles de trous noirs pour détecter leurs transitions de phase. À l’avenir, cette technique pourrait automatiser les laboratoires de physique, l’algorithme définissant automatiquement les paramètres de contrôle des expériences et calculant immédiatement les diagrammes de phase à partir des données mesurées. Les scientifiques pourraient également utiliser cette approche pour résoudre différentes tâches de classification binaire dans les systèmes physiques.
Implications pour les modèles de langage
Il est intéressant de noter que cette méthode inspirée de ChatGPT peut également être appliquée à des modèles de langage comme ChatGPT lui-même. Par exemple, la “température” de ChatGPT peut être ajustée pour contrôler la créativité de l’algorithme. Une température basse produit des résultats prévisibles, tandis qu’une température élevée génère du texte plus aléatoire et chaotique. La technique des chercheurs pourrait déterminer la transition optimale entre ces phases et ajuster les modèles de langage en conséquence.







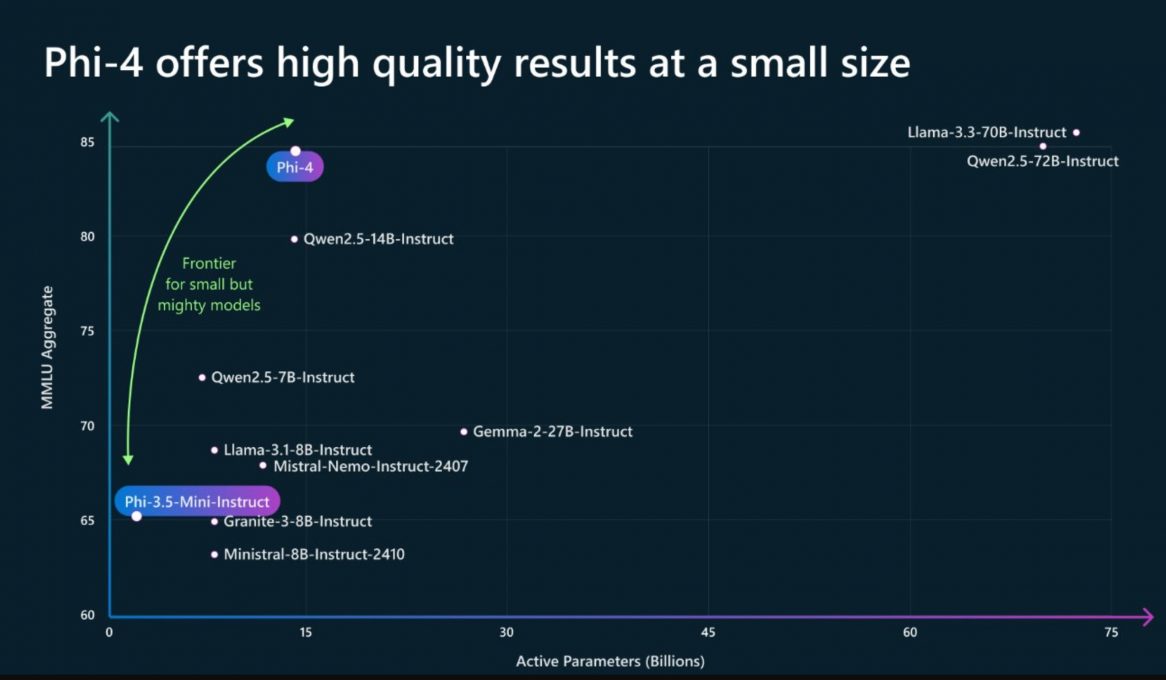
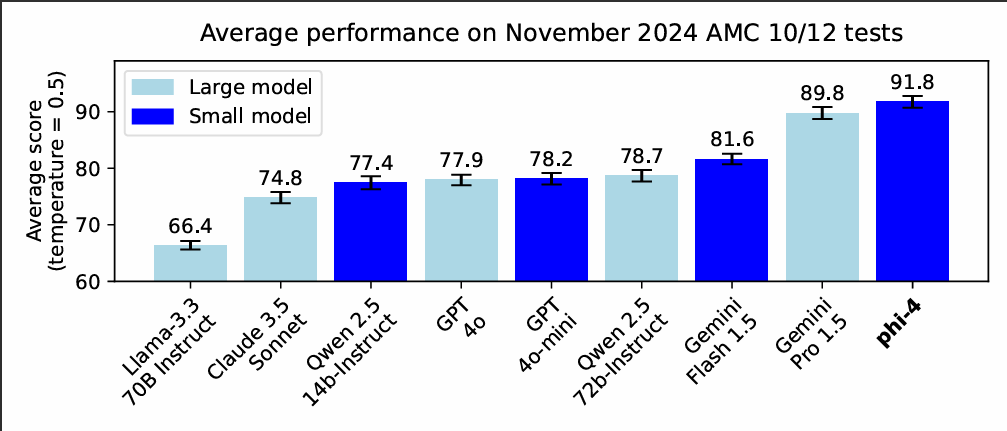







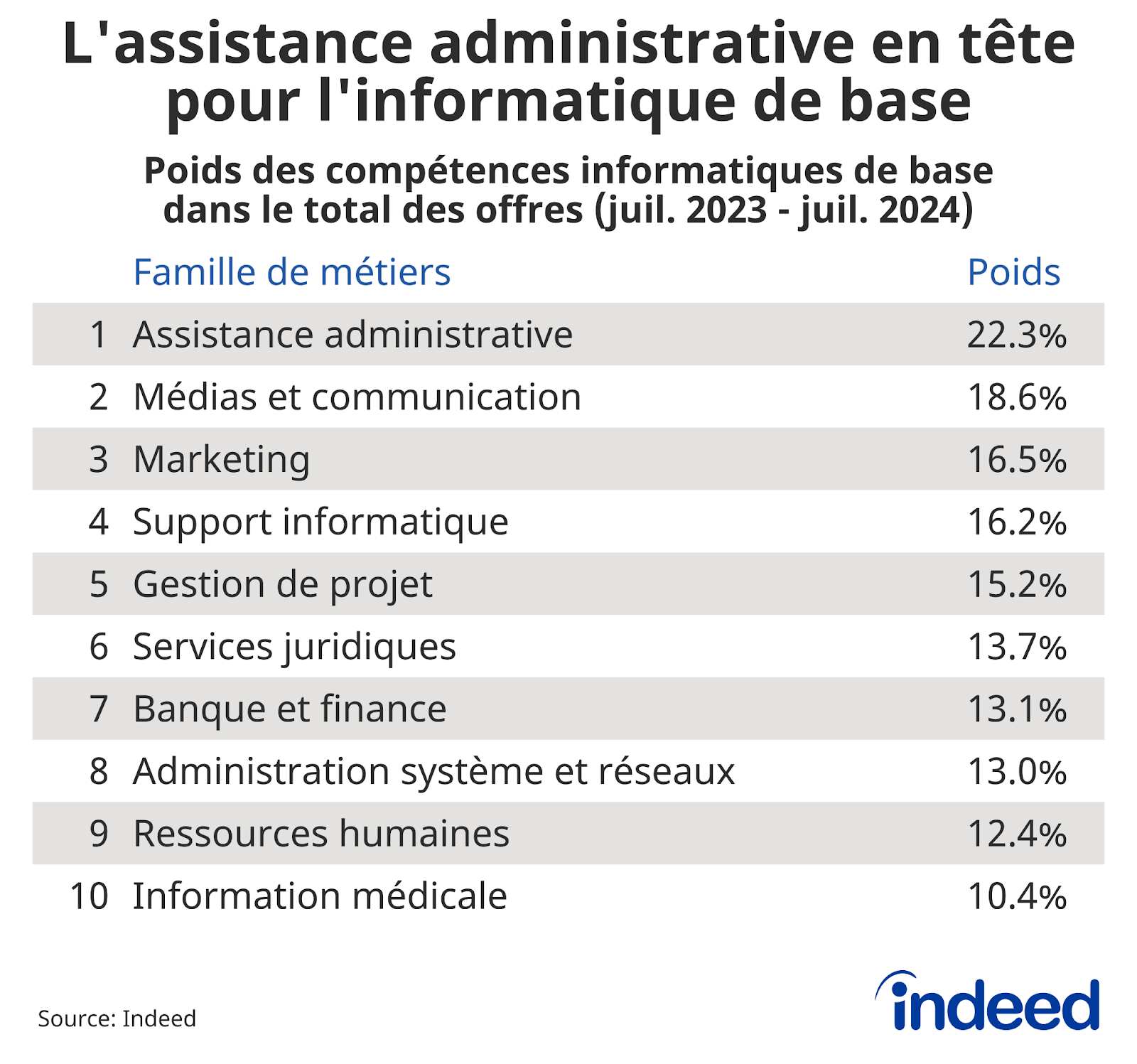







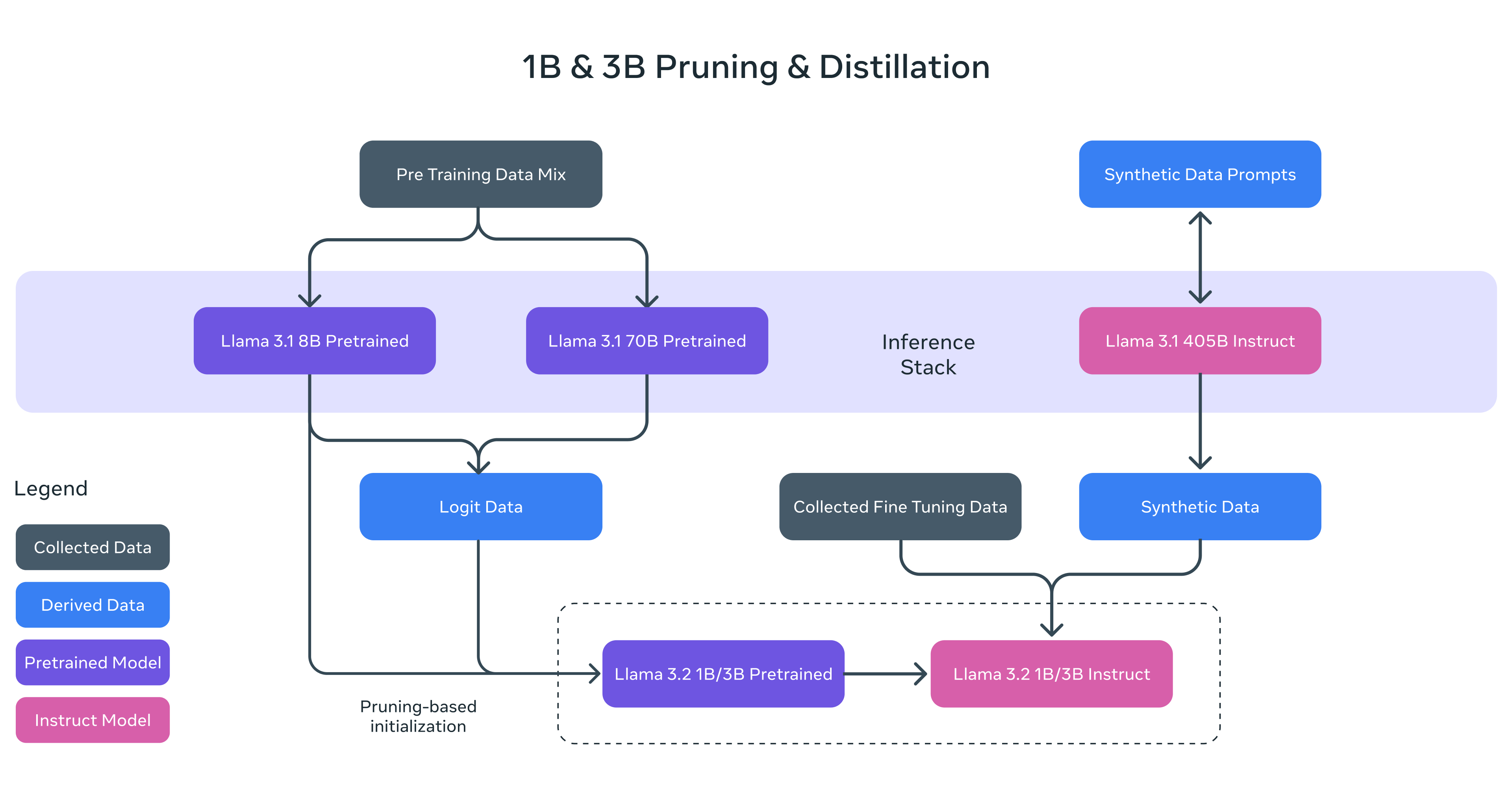
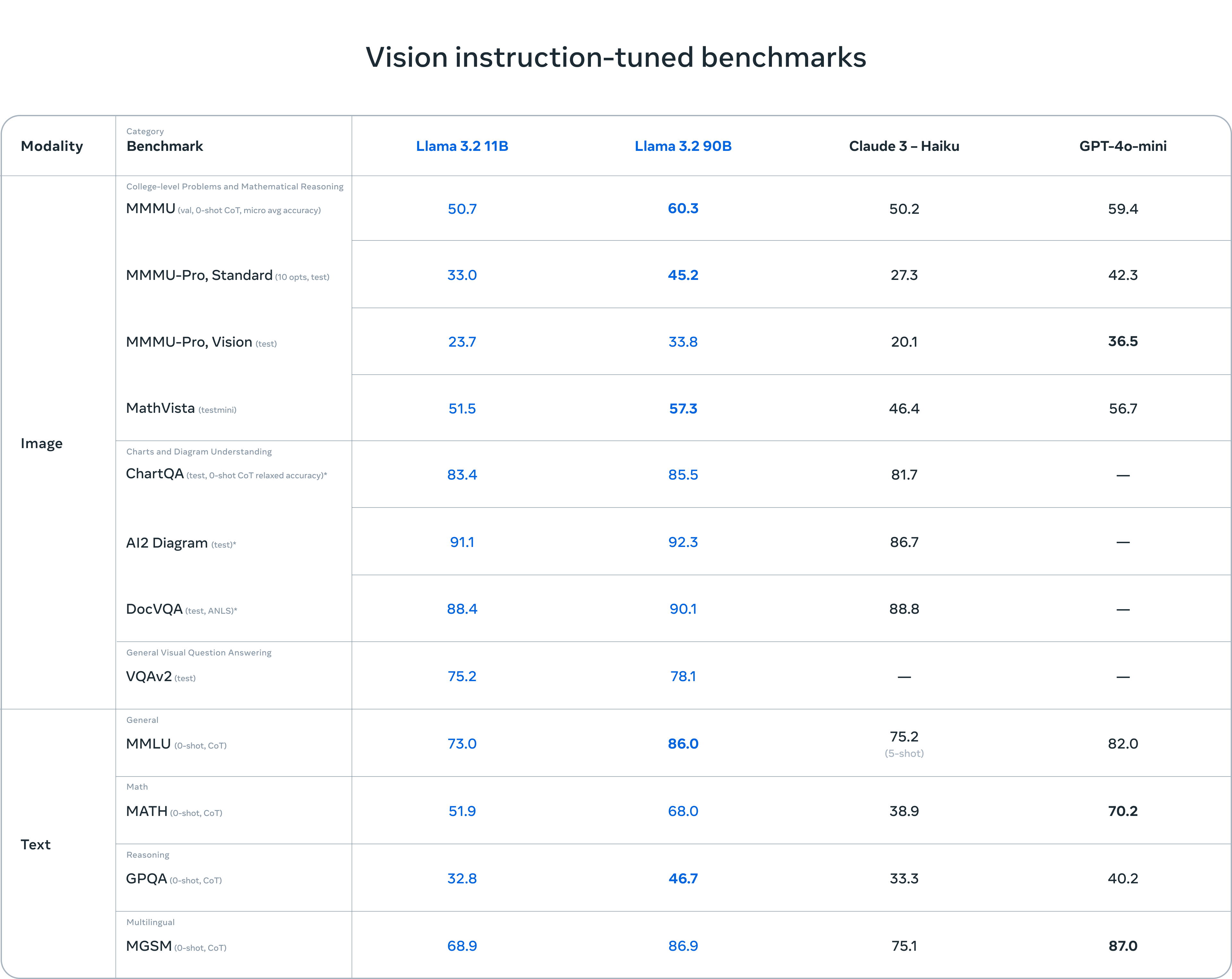
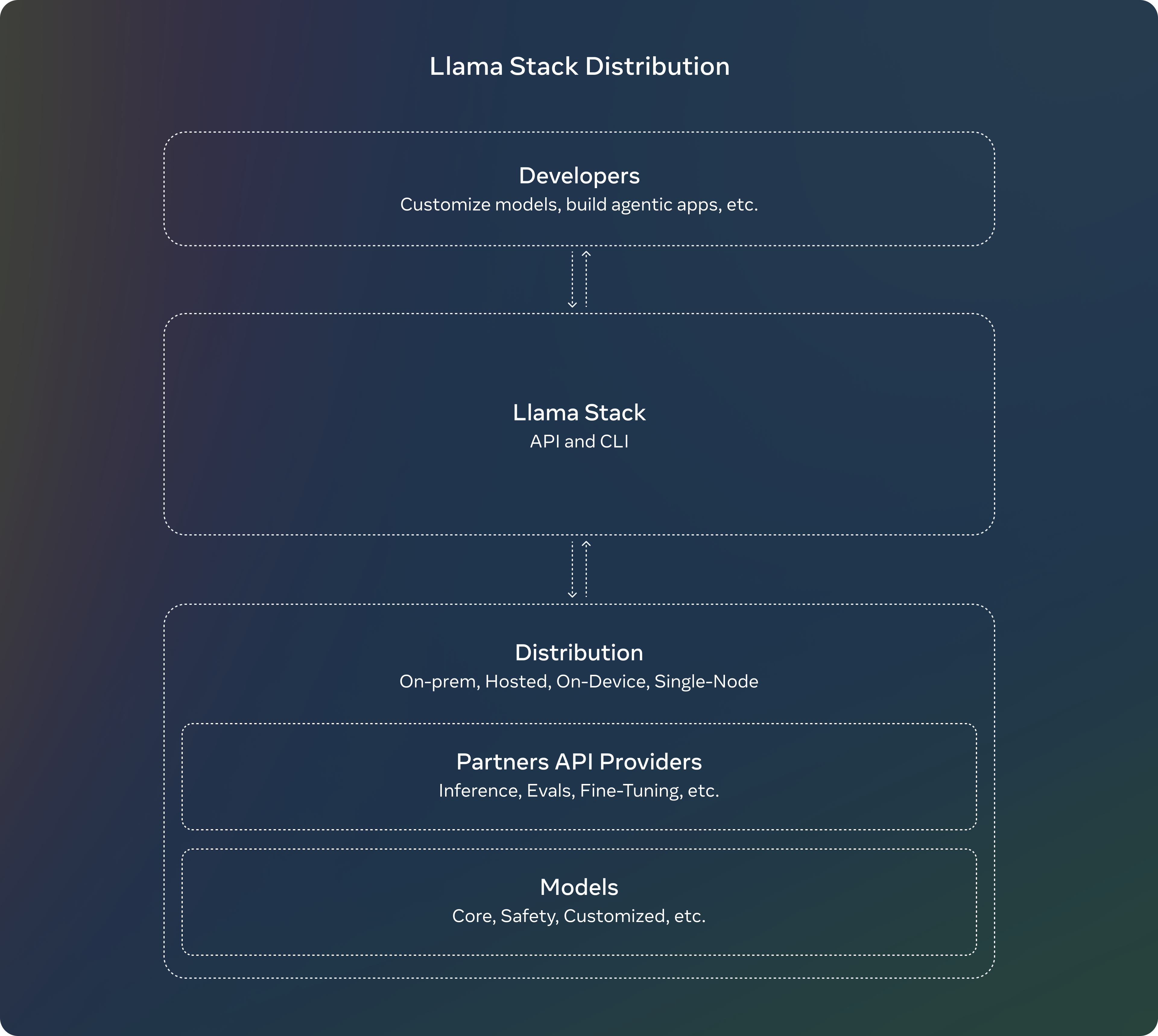














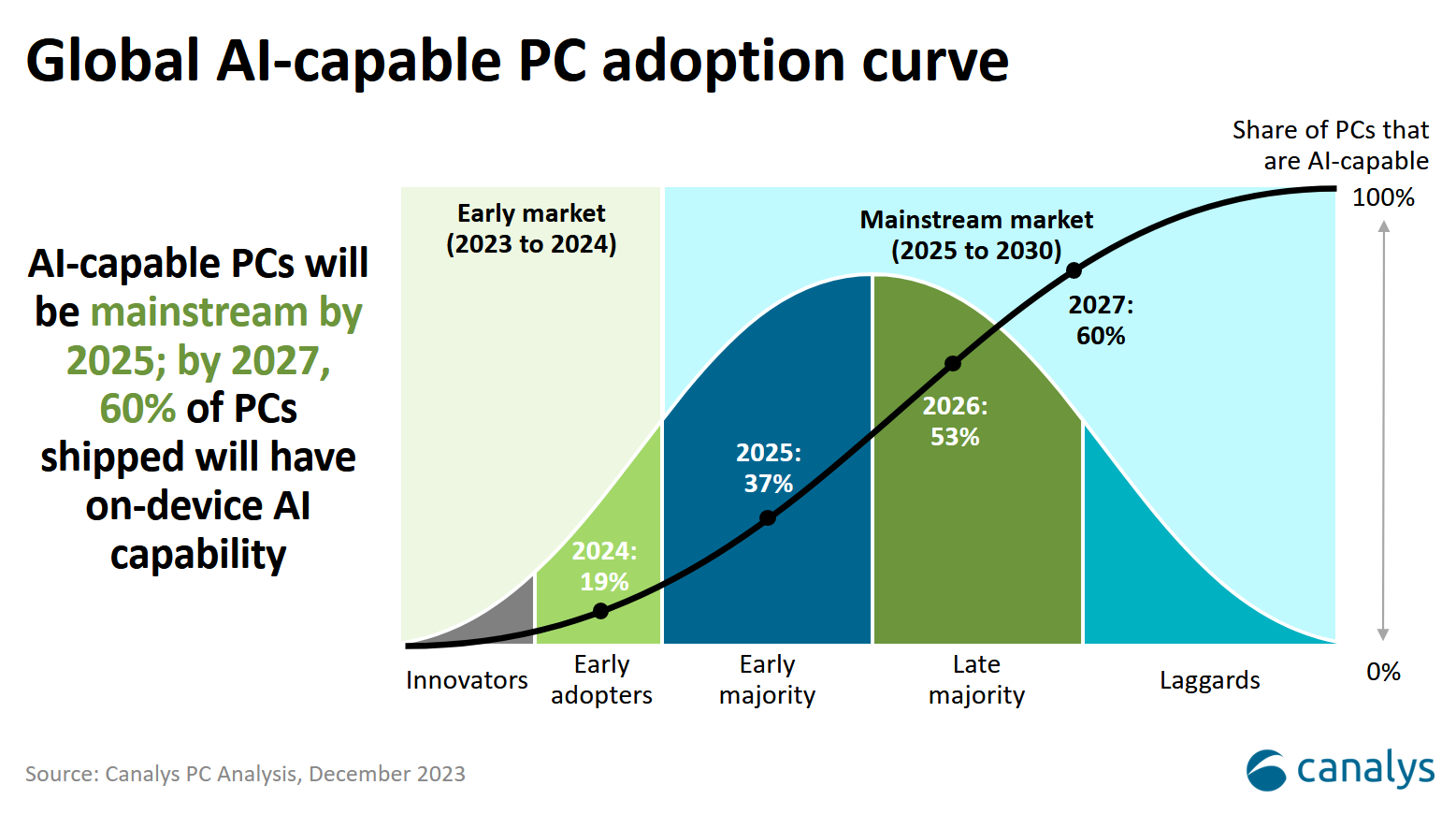
 US ont augmenté de 9 % en séquentiel au T2 2024, les expéditions de PC compatibles avec l’IA dans ces tranches de prix ayant augmenté de 126 %. À mesure que la gamme de fonctionnalités des applications propriétaires et tierces qui exploitent le NPU augmente et que les avantages en termes de performances et d’efficacité deviennent plus clairs, la proposition de valeur pour les PC compatibles avec l’IA restera forte. C’est particulièrement important au cours des 12 prochains mois, car une partie importante de la base installée sera actualisée dans le cadre du cycle de mise à niveau de Windows en cours”.
US ont augmenté de 9 % en séquentiel au T2 2024, les expéditions de PC compatibles avec l’IA dans ces tranches de prix ayant augmenté de 126 %. À mesure que la gamme de fonctionnalités des applications propriétaires et tierces qui exploitent le NPU augmente et que les avantages en termes de performances et d’efficacité deviennent plus clairs, la proposition de valeur pour les PC compatibles avec l’IA restera forte. C’est particulièrement important au cours des 12 prochains mois, car une partie importante de la base installée sera actualisée dans le cadre du cycle de mise à niveau de Windows en cours”.