Orange est un acteur majeur du numérique en Europe, au Moyen-Orient ainsi qu’en Afrique. L’inclusivité digitale et le développement durable du continent africain sont au cœur de son plan “Lead the future” lancé en 2023. C’est d’ailleurs dans le cadre de cet engagement envers l’inclusion que le Groupe annonce une collaboration avec OpenAI et Meta, visant à intégrer des langues régionales africaines dans des modèles d’IA open source, notamment Whisper et Llama.
De nombreuses langues sont encore so
Orange est un acteur majeur du numérique en Europe, au Moyen-Orient ainsi qu’en Afrique. L’inclusivité digitale et le développement durable du continent africain sont au cœur de son plan “Lead the future” lancé en 2023. C’est d’ailleurs dans le cadre de cet engagement envers l’inclusion que le Groupe annonce une collaboration avec OpenAI et Meta, visant à intégrer des langues régionales africaines dans des modèles d’IA open source, notamment Whisper et Llama.
De nombreuses langues sont encore sous-représentées dans l’apprentissage des LMMs, c’est particulièrement vrai en Afrique où de nombreux dialectes co-existent.
L’initiative, qui débutera en 2025, se concentrera dans un premier temps sur l’incorporation du wolof et du pulaar, deux langues régionales parlées respectivement par 16 millions et 6 millions de personnes en Afrique de l’Ouest. Les modèles affinés permettront aux populations locales de communiquer plus naturellement dans leur langue. Ils seront intégrés aux services clients d’Orange et rendus disponibles gratuitement pour des projets éducatifs, de santé publique et autres usages non commerciaux.
Orange prévoit d’étendre ce projet aux langues africaines parlées dans les 18 pays où il est présent, comme le lingala, le swahili et le bambara. Dans ce but, il collaborera avec des startups locales et des entreprises technologiques africaines, afin de bâtir un écosystème d’innovation IA inclusif, remédiant ainsi à la sous-représentation du continent dans le domaine de l’IA.
Accord exclusif avec OpenAI
Orange a en outre signé un accord avec OpenAI lui donnant un accès direct et exclusif en Europe à ses modèles les plus avancés, garantissant que les données sont traitées et stockées en Europe.
Cet accès anticipé aux modèles d’IA de pointe d’OpenAI facilitera la mise en œuvre de nouveaux cas d’utilisation, comme les interactions vocales basées sur l’IA avec les clients d’Orange.
Orange, OpenAI et Meta s'associent pour intégrer les langues régionales africaines dans les modèles d'IA open source
Eden AI annonce avoir levé 3 millions d’euros lors d’un tour de seed mené par Galion.exe avec la participation de 50 Partners et d’éminents business angels tels qu’Olivier Pomel (co-fondateur de Datadog) Sébastien Pahl (co-fondateur de Docker) et Alix de Sagazan (co-fondatrice d’ABTasty).
Cofondée à Lyon en 2021 par Taha Zemmouri, son PDG et Samy Melaine, son CTO, la start-up s’est donnée pour mission de rendre l’IA accessible aux entreprises quelque soit leur taille. Plus de 500 organisations d
Eden AI annonce avoir levé 3 millions d’euros lors d’un tour de seed mené par Galion.exe avec la participation de 50 Partners et d’éminents business angels tels qu’Olivier Pomel (co-fondateur de Datadog) Sébastien Pahl (co-fondateur de Docker) et Alix de Sagazan (co-fondatrice d’ABTasty).
Cofondée à Lyon en 2021 par Taha Zemmouri, son PDG et Samy Melaine, son CTO, la start-up s’est donnée pour mission de rendre l’IA accessible aux entreprises quelque soit leur taille. Plus de 500 organisations dans le monde, dont Atos (Eviden) et le Conseil de l’Europe lui font confiance pour transformer leurs stratégies d’intégration de l’IA, rationaliser le déploiement et améliorer l’efficacité opérationnelle.
Ce financement lui permettra de recruter de nouveaux ingénieurs, d’accélérer le développement de nouveaux produits et d’élargir son écosystème de partenaires.
Une réponse à la complexité de l’intégration de l’IA
De nombreuses entreprises rencontrent des obstacles lorsqu’il s’agit d’intégrer l’IA. Les défis techniques, les ressources limitées, le manque d’expertise et la nécessité de naviguer dans un écosystème complexe de fournisseurs freinent souvent leur adoption. Eden AI propose une solution centrale : une plateforme unifiée offrant accès à plus de 70 technologies couvrant des domaines variés tels que le traitement du langage naturel, la vision par ordinateur ou la GenAI, et à 100 modèles d’IA de fournisseurs de premier plan tels que Google, AWS et OpenAI.
Cette plateforme se distingue par sa facilité d’utilisation et sa scalabilité. Elle permet à ses utilisateurs de créer des flux de travail d’IA complexes de manière intuitive, de gérer les coûts, suivre les performances et superviser toutes les solutions d’IA intégrées à partir d’un seul tableau de bord.
Modèles de flux de travail d’Eden AI
Perspectives d’avenir
Eden AI a pour projets d’étendre ses capacités de flux de travail, de déployer des fonctionnalités d’analyse et de surveillance avancées et de s’étendre à l’échelle mondiale.
Taha Zemmouri, cofondateur et PDG d’Eden AI, conclut :
“Nous pensons que chaque entreprise, quelle que soit sa taille ou son expertise technique, devrait être en mesure de tirer parti de l’IA pour stimuler l’efficacité et l’innovation. Notre objectif ultime est de devenir la plateforme définitive pour la création d’applications alimentées par l’IA à grande échelle”.
L’IA appliquée à la robotique a le vent en poupe. Pour exemple, Physical Intelligence, une jeune start-up basée à San Francisco a annoncé lundi dernier avoir levé la somme de 400 millions de dollars lors d’un tour de table mené par Jeff Bezos, fondateur et président exécutif du conseil d’administration d’Amazon, Thrive Capital et Lux Capital. OpenAI, Redpoint Ventures et Bond figurent parmi les autres investisseurs.
A son lancement, en mars dernier, Physical Intelligence (Pi) annonçait avoir reç
L’IA appliquée à la robotique a le vent en poupe. Pour exemple, Physical Intelligence, une jeune start-up basée à San Francisco a annoncé lundi dernier avoir levé la somme de 400 millions de dollars lors d’un tour de table mené par Jeff Bezos, fondateur et président exécutif du conseil d’administration d’Amazon, Thrive Capital et Lux Capital. OpenAI, Redpoint Ventures et Bond figurent parmi les autres investisseurs.
A son lancement, en mars dernier, Physical Intelligence (Pi) annonçait avoir reçu des financements initiaux de 70 millions de dollars apportés par de Khosla Ventures, Lux Capital, OpenAI, Sequoia Capital et Thrive Capital. Grâce à cette dernière levée de fonds, la start-up serait aujourd’hui valorisée à environ 2 milliards de dollars.
Son PDG et cofondateur Karol Hausman était auparavant chercheur scientifique chez Google DeepMind. Pi déclare sur son site :
“L’intelligence physique apporte l’IA à usage général dans le monde physique. Nous sommes un groupe d’ingénieurs, de scientifiques, de roboticiens et de bâtisseurs d’entreprise qui développent des modèles de fondation et des algorithmes d’apprentissage pour alimenter les robots d’aujourd’hui et les appareils à commande physique du futur”.
Son objectif est de développer un modèle d’IA polyvalent, capable de piloter divers robots et dispositifs physiques pour des applications multiples. Contrairement à la robotique traditionnelle, souvent axée sur des tâches spécifiques et répétitives dans des environnements contrôlés, Physical Intelligence travaille à créer une IA plus adaptative pour des interactions dans le monde réel.
Elle a d’ailleurs partagé sur son blog le 31 octobre dernier le fruit de son travail des huit derniers mois : π0 (pi-zéro) et détaille son approche dans un article, expliquant :
“À l’instar des LLM, notre modèle est formé sur des données larges et diverses et peut suivre diverses instructions textuelles. Contrairement aux LLM, il s’étend sur des images, du texte et des actions et acquiert de l’intelligence physique en s’entraînant sur l’expérience incarnée de robots, apprenant à émettre directement des commandes motrices de bas niveau via une nouvelle architecture. Il peut contrôler une variété de robots différents et peut être soit invité à effectuer la tâche souhaitée, soit affiné pour le spécialiser dans des scénarios d’application difficiles”.
π0 est entraîné à partir de données multitâches et multirobots, incluant des tâches complexes comme plier du linge, nettoyer des tables, et assembler des boîtes. Il utilise un modèle de langage visuel (VLM) pré-entraîné, capable de manipuler des objets avec précision en temps réel grâce à un nouveau système d’appariement de flux pour des actions continues. Il peut ainsi être adapté rapidement pour de nouvelles tâches, surmontant ainsi les limites des modèles précédents.
La société qui collabore avec plusieurs entreprises et laboratoires de robotique, notamment pour affiner les conceptions matérielles pour la téléopération et l’autonomie, reconnait qu’il lui reste “un long chemin à parcourir”. Cependant, pour elle, “ces premiers résultats brossent un tableau prometteur pour l’avenir des modèles de fondation robotique”.
IA et robotique : Physical Intelligence annonce une levée de fonds de 400 millions de dollars
Alors que les modèles d’IA deviennent de plus en plus sophistiqués, des craintes ont surgi sur leurs risques potentiels pour la société, notamment dans des domaines sensibles comme la cybersécurité, la chimie ou la biologie. Anthropic, qui a mis à jour récemment sa politique de mise à l’échelle responsable (RSP), exhorte les gouvernements à adopter rapidement des mesures réglementaires efficaces, alertant : “La fenêtre de la prévention proactive des risques se referme rapidement”.
Cofondée en 20
Alors que les modèles d’IA deviennent de plus en plus sophistiqués, des craintes ont surgi sur leurs risques potentiels pour la société, notamment dans des domaines sensibles comme la cybersécurité, la chimie ou la biologie. Anthropic, qui a mis à jour récemment sa politique de mise à l’échelle responsable (RSP), exhorte les gouvernements à adopter rapidement des mesures réglementaires efficaces, alertant : “La fenêtre de la prévention proactive des risques se referme rapidement”.
Cofondée en 2021 par les frère et sœur Daniela et Dario Amodei, qui avaient travaillé auparavant chez OpenAI, rejoints par la suite par d’anciens collaborateurs de la start-up, Anthropic est aujourd’hui l’un des leaders de l’IA générative.
Son objectif est de rendre les systèmes plus fiables, orientables et interprétables. Elle a pour cela développé l’IA constitutionnelle, une approche d’entraînement des modèles de langage visant à inculquer des valeurs et des principes spécifiques dans les systèmes d’IA. Sa famille de modèles Claude est ainsi guidée par un ensemble de principes comme ceux de la Déclaration des droits de l’Homme pour générer des réponses plus honnêtes et alignées sur des valeurs éthiques.
En juillet 2023, Anthropic faisait partie des sept grandes entreprises s’engageant officiellement devant le gouvernement Biden à mettre en place de nouvelles normes de sûreté, de sécurité et de confiance et, avec trois d’entre elles, Microsoft, Anthropic et Google, lançait le Frontier Model Forum, un organisme industriel dédié au développement sûr et responsable des modèles d’IA de pointe.
Au mois de septembre suivant, la start-up, soulignant les risques réels que pourraient représenter les modèles de frontière pour les domaines cybernétique et CBRN (chimiques, biologiques, radiologiques et nucléaires) d’ici 2 à 3 ans, présentait sa politique de mise à l’échelle responsable.
Pour elle :
“Une réglementation judicieuse et étroitement ciblée peut nous permettre d’obtenir le meilleur des deux mondes : profiter des avantages de l’IA tout en atténuant les risques. Traîner les pieds pourrait conduire au pire des deux mondes : une réglementation mal conçue et impulsive qui entrave le progrès tout en ne parvenant pas à prévenir les risques.”
Vers un cadre réglementaire inspiré du RSP d’Anthropic ?
Certains acteurs de l’IA ont anticipé ces défis liés à l’IA en adoptant une RSP, plus ou moins similaire à celle d’Anthropic, qui ajuste les mesures de sécurité en fonction des capacités atteintes par les modèles : des seuils de performance sont définis pour chaque nouvelle génération de systèmes, et des mécanismes de sécurité sont déployés lorsque ces seuils sont franchis.
Les RSP permettent aux entreprises de gérer proactivement les risques liés aux IA de pointe, tout en optimisant leurs performances sur le marché. Elles offrent également des avantages en termes de transparence et de responsabilité : les entreprises qui adoptent ce modèle s’engagent à documenter leurs pratiques de sécurité, à identifier et évaluer les risques de manière continue, et à investir dans des équipes dédiées à la sécurité. Chez Anthropic, des équipes spécialisées en sécurité informatique, en interprétabilité, et en évaluations d’équipes adverses (équipe rouge) sont intégrées dans la feuille de route de chaque nouveau modèle.
Dario Amodei soulignait, il y a un an, au Sommet de sécurité de l’IA de Bletchley :
“Les RSP ne sont pas destinés à se substituer à la réglementation, mais plutôt à en être un prototype. Je ne veux pas dire que nous voulons que le RSP d’Anthropic soit littéralement inscrit dans les lois – notre RSP n’est qu’une première tentative de résoudre un problème difficile, et est presque certainement imparfait à bien des égards”.
Les trois piliers d’une réglementation ciblée efficace
Selon l’entreprise, “ce cadre réglementaire ne sera pas parfait“, mais “Quelle que soit la réglementation à laquelle nous parvenons, elle doit être aussi chirurgicale que possible”.
Elle identifie trois piliers essentiels :
Transparence : Actuellement, il n’existe pas de mécanisme permettant de vérifier l’adhésion des entreprises à leurs politiques de sécurité. Exiger la publication de ces politiques et de leurs évaluations pourrait permettre de construire un registre public des risques associés aux systèmes d’IA ;
Promotion de pratiques de sécurité robustes : Les entreprises devraient être encouragées, voire obligées, à renforcer leurs mesures de sécurité et à maintenir des standards élevés en matière de gestion des risques. Des organismes de réglementation pourraient ainsi établir les normes minimales en matière de sûreté que chaque système doit respecter ;
Simplicité et ciblage : Toute réglementation devrait rester aussi claire et ciblée que possible pour éviter d’entraver l’innovation. Une loi simple et bien définie réduit la complexité pour les entreprises et facilite le respect des règles sans générer des obligations excessives.
Des approches autres que celles d’Anthropic réunissent ces trois conditions, ce qu’elle reconnaît volontiers, concluant :
“Il est essentiel au cours de l’année prochaine que les décideurs politiques, l’industrie de l’IA, les défenseurs de la sécurité, la société civile et les législateurs travaillent ensemble pour élaborer un cadre réglementaire efficace qui réponde aux conditions ci-dessus et qui soit acceptable pour un large éventail de parties prenantes”.
Lors de sa conférence annuelle Universe, GitHub a annoncé la semaine dernière une série d’innovations pour son outil de développement basé sur l’IA : GitHub Copilot, qui intègre désormais des modèles de pointe d’Anthropic, Google et OpenAI. GitHub a également dévoilé sa dernière avancée pour démocratiser la création de logiciels, permettant aux développeurs, qu’ils soient novices ou expérimentés, de concevoir des micro-applications à partir d’instructions en langage naturel : GitHub Spark.
GitH
Lors de sa conférence annuelle Universe, GitHub a annoncé la semaine dernière une série d’innovations pour son outil de développement basé sur l’IA : GitHub Copilot, qui intègre désormais des modèles de pointe d’Anthropic, Google et OpenAI. GitHub a également dévoilé sa dernière avancée pour démocratiser la création de logiciels, permettant aux développeurs, qu’ils soient novices ou expérimentés, de concevoir des micro-applications à partir d’instructions en langage naturel : GitHub Spark.
GitHub Copilot multi-modèle : vers plus de flexibilité
Créé par GitHub en collaboration avec OpenAI, l’outil d’assistance à la programmation basé sur l’IA, Copilot, était initialement alimenté par Codex, une version d’OpenAI GPT-3 spécialement conçue pour les tâches de codage. Copilot a évolué au fil des mises à jour pour inclure GPT 3.5-turbo et, récemment, les modèles GPT 4o et 4o-mini, pour répondre à différentes exigences de latence et de qualité. GitHub a décidé d’intégrer de nouveaux modèles d’IA de pointe pour permettre aux développeurs et aux entreprises de l’utiliser en fonction de leurs politiques internes, préférences technologiques et besoins en matière de sécurité.
Claude 3.5 Sonnet d’Anthropic, o1-preview et o1-mini d’OpenAi ont ainsi été déployés dans Copilot Chat, Gemini 1.5 Pro de Google devrait les y rejoindre dans les semaines à venir. Les développeurs peuvent basculer entre les modèles au cours d’une conversation.
Thomas Dohmke, PDG de GitHub, commente :
“En 2024, nous avons connu un boom des modèles de langage de haute qualité, grands et petits, qui excellent chacun individuellement dans différentes tâches de programmation. Il n’y a pas de modèle unique pour régir tous les scénarios, et les développeurs s’attendent à ce que l’agence construise avec les modèles qui leur conviennent le mieux. Il est clair que la prochaine phase de génération de code d’IA ne sera pas seulement définie par une fonctionnalité multimodèle, mais aussi par un choix multimodèle. Aujourd’hui, c’est exactement ce que nous offrons”.
Créer des applications en langage naturel
GitHub a l’ambition d’atteindre 1 milliard de développeurs : Spark, développé dans le laboratoire GitHub Next, est sa dernière avancée pour démocratiser la création de logiciels, permettant aux utilisateurs de tous niveaux de concevoir des micro-applications ou “Sparks” via des instructions en langage naturel. Avec une interface intuitive et une boucle de feedback en temps réel, GitHub Spark permet d’itérer, tester et partager des applications, offrant une flexibilité maximale tant pour les novices que pour les développeurs expérimentés.
Spark repose sur les modèles d’OpenAI et Anthropic. Les développeurs expérimentés peuvent apporter directement des modifications au code sous-jacent, tandis que les utilisateurs ou les développeurs novices peuvent itérer entièrement en langage naturel. Une fois satisfaits de leur spark, ils peuvent l’exécuter automatiquement sur leur ordinateur de bureau, leur tablette ou leur appareil mobile. Ils peuvent également choisir de partager leur micro-application avec un contrôle d’accès personnalisé, ainsi que permettre à d’autres de la remixer et de s’appuyer sur leur création.
L’expérience IA native s’étend à toute la plateforme GitHub
En plus du multi-modèle, GitHub introduit de nouvelles fonctionnalités, telles que :
Copilot dans VS Code : les développeurs peuvent désormais appliquer des modifications sur plusieurs fichiers simultanément grâce à des instructions en langage naturel ;
Extensions de Copilot : elles permettent d’intégrer des outils externes et des fonctionnalités personnalisées dans l’environnement de développement ;
Copilot Autofix et campagnes de sécurité : les développeurs bénéficient d’une correction automatisée des vulnérabilités et de nouveaux outils pour la gestion des campagnes de sécurité.
GitHub Octoverse 2024 : tendances en IA et adoption de Python
Le rapport Octoverse 2024 montre que Python a dépassé JavaScript en termes d’utilisation, en raison de sa polyvalence dans les projets d’IA. De plus, GitHub enregistre une augmentation de 98 % des projets d’IA générative, une tendance propulsée par l’adoption mondiale de l’IA, notamment en Inde, en Allemagne et au Japon.
Le rapport souligne également une croissance significative de la communauté des développeurs, en particulier en Afrique, en Amérique latine et en Asie.
Principales annonces Universe 2024 : GitHub Copilot devient multi-modèles, introduction de Spark pour créer des micro-applications en langage naturel
Teledyne FLIR, filiale de Teledyne Technologies Incorporated, acteur majeur du développement de solutions d’imagerie infrarouge, de systèmes intelligents et de détection, annonce l’ajout d’une nouvelle solution à sa famille de logiciels Teledyne FLIR Prism : Prism AIMMGen.
Prism AIMMGen est un service de génération de modèles d’IA exempt d’ITAR (International Traffic in Arms Regulations) qui permet la création automatisée de modèles d’IA et d’apprentissage automatique à l’aide de données générée
Teledyne FLIR, filiale de Teledyne Technologies Incorporated, acteur majeur du développement de solutions d’imagerie infrarouge, de systèmes intelligents et de détection, annonce l’ajout d’une nouvelle solution à sa famille de logiciels Teledyne FLIR Prism : Prism AIMMGen.
Prism AIMMGen est un service de génération de modèles d’IA exempt d’ITAR (International Traffic in Arms Regulations) qui permet la création automatisée de modèles d’IA et d’apprentissage automatique à l’aide de données générées synthétiquement. Il permet ainsi aux intégrateurs de systèmes qui développent des produits d’IA/ML pour des applications commerciales, de première intervention ou de défense de réaliser d’importantes économies en termes de coûts et de délais.
Une réponse aux défis de la collecte de données réelles
Le développement de modèles IA/ML nécessite traditionnellement une collecte et un étiquetage manuels des données, des tâches chronophages et coûteuses, particulièrement dans des contextes où les objets à détecter sont rares ou difficiles à capturer dans des scénarios réels, comme les cibles militaires. Prism AIMMGen surmonte ces obstacles en générant des millions d’exemples d’objets synthétiques, prêts pour le ML, dans des conditions variées et sur différents spectres, notamment la lumière visible et l’infrarouge. Ce processus réduit de façon drastique les délais et les coûts d’ingénierie, permettant de produire des modèles de haute qualité en quelques jours plutôt qu’en plusieurs semaines. Son infrastructure interne de MLOps garantit que les données sont sécurisées et que les modèles peuvent être développés, déployés et maintenus efficacement.
Dan Walker, Vice-président de Teledyne FLIR, explique :
“Avec le rythme et la sophistication que connaît le développement de systèmes, il est essentiel d’exploiter des données synthétiques intelligentes pour former les modèles d’IA les meilleurs de leur catégorie. AIMMGen accélère la mise sur le marché des développeurs tout en garantissant à leurs produits d’IA respectifs d’être prêts à faire face à tous les scénarios possibles dans pratiquement toutes les conditions environnementales”.
Caractéristiques clés de Prism AIMMGen
Génération illimitée d’images synthétiques : Un accès à un vaste lac de données non soumis aux restrictions ITAR, applicable à de multiples cas d’utilisation en détection d’objets.
Ensembles de données spécifiques : Capacité à produire des millions d’images synthétiques annotées automatiquement, adaptées aux besoins spécifiques d’applications diverses, avec un outil interactif de recherche pour un apprentissage optimisé.
Optimisation automatisée des modèles : Génération rapide de modèles IA performants avec une infrastructure MLOps sécurisée, permettant de répondre aux besoins des développeurs dans des délais très courts.
À l’occasion du Sommet de la Francophonie, que la France a accueilli les 4 et 5 octobre derniers, le ministère de la Culture et la Direction interministérielle du numérique (DINUM) ont lancé la version bêta du 1er comparateur francophone d’IA conversationnelle : Compar:IA.
Cet outil gratuit, fruit de 9 mois de travail de Lucie Termignon, a été développé dans le cadre de la start-up d’Etat Compar:IA (incubateurs de l’Atelier numérique et AllIAnce) intégrée au programme beta.gouv.fr de la DINUM.
I
À l’occasion du Sommet de la Francophonie, que la France a accueilli les 4 et 5 octobre derniers, le ministère de la Culture et la Direction interministérielle du numérique (DINUM) ont lancé la version bêta du 1er comparateur francophone d’IA conversationnelle : Compar:IA.
Cet outil gratuit, fruit de 9 mois de travail de Lucie Termignon, a été développé dans le cadre de la start-up d’Etat Compar:IA (incubateurs de l’Atelier numérique et AllIAnce) intégrée au programme beta.gouv.fr de la DINUM.
Il vise à répondre à trois objectifs :
Sensibiliser les citoyens à l’IA générative et ses enjeux ;
Veiller au respect de la diversité des cultures francophones dans les modèles d’IA conversationnelle ;
Contribuer à la transparence des modèles d’IA générative.
La plateforme Compar:IA
Pour l’instant, le site Compar:IA donne accès à 11 modèles d’IA, l’un propriétaire Gemini 1,5 pro de Google, les autres open source. On retrouve Command R de Cohere, Gemma 2 9B de Google, 3 modèles Llama 3.1 de Meta, 3 modèles de Mistral AI (Mistral Nemo, 2 versions de Mixtral), Phi-3.5-mini de Microsoft, Queen 2-7B d’Alibaba et enfin le modèle chinois Yi 1.5 de 01-ai. Chacun des modèles est explicité.
Les utilisateurs peuvent discuter avec deux d’entre eux à l’aveugle pour comparer leurs réponses. Dans ce but, huit tâches sont proposées. On peut, par exemple, demander aux modèles de générer de nouvelles idées, d’expliquer simplement un concept, de rédiger un document administratif ou de raconter une histoire.
Dans quel but ?
Les IA conversationnelles sont souvent biaisées du fait qu’elles sont majoritairement sur des données anglaises, ce qui les amène à produire des réponses stéréotypées ou incorrectes pour les langues et cultures non-anglophones.
Les internautes peuvent contribuer à les améliorer en donnant leur avis. Les données de préférence issues de la comparaison des modèles sont collectées, nettoyées pour créer des jeux de données d’évaluations humaines en français, ciblés sur des tâches spécifiquement liées à la langue et la culture française.
Les jeux de données constitués seront accessibles librement et pourront être utilisés pour améliorer l’expression des modèles d’IA conversationnelle sur des tâches en français.
Le comparateur sera prochainement intégré à un parcours pédagogique créé spécifiquement par Pix, un service public en ligne ouvert à tous pour évaluer, développer et certifier ses compétences numériques au travers de défis apprenants et ludiques.
De nombreux médias avaient rapporté qu’OpenAI était en pourparlers pour une levée de fonds qui la valoriserait à plus de 100 milliards de dollars, ce que la start-up a confirmé mercredi dans un communiqué. Elle y annonce avoir levé 6,6 milliards de dollars qui la valorisent en fait à 157 milliards de dollars. Jeudi, elle faisait savoir qu’elle avait établi une nouvelle facilité de crédit de 4 milliards de dollars auprès de plusieurs grandes banques, ce qui lui donnera accès à plus de 10 milliard
De nombreux médias avaient rapporté qu’OpenAI était en pourparlers pour une levée de fonds qui la valoriserait à plus de 100 milliards de dollars, ce que la start-up a confirmé mercredi dans un communiqué. Elle y annonce avoir levé 6,6 milliards de dollars qui la valorisent en fait à 157 milliards de dollars. Jeudi, elle faisait savoir qu’elle avait établi une nouvelle facilité de crédit de 4 milliards de dollars auprès de plusieurs grandes banques, ce qui lui donnera accès à plus de 10 milliards de dollars de liquidités.
La start-up qui revendique désormais plus d’un million d’utilisateurs payants et plus de 250 millions d’utilisateurs hebdomadaires de ChatGPT a de nouveau séduit les investisseurs. Le tour de table a été mené par la société de capital-risque Thrive Capital qui a investi 1,3 milliard de dollars, Microsoft, le principal investisseur d’OpenAI, a quant à lui participé à hauteur de 750 millions de dollars. Parmi les autres investisseurs, on trouve Nvidia, Softbank, Khosla Ventures, Altimeter Capital, Fidelity, Tiger Global et MGX.
OpenAI assure dans son communiqué :
“Le nouveau financement nous permettra de renforcer notre leadership dans la recherche sur l’IA de pointe, d’augmenter notre capacité de calcul et de continuer à créer des outils qui aident les gens à résoudre des problèmes difficiles”.
OpenAI a commencé comme une organisation à but non lucratif lors de sa création en 2015. Cependant, en 2019, elle a restructuré ses opérations et est devenue une organisation à but lucratif limitée, tout en conservant une entité à but non lucratif qui supervise ses activités, “OpenAI Inc.”
Ce modèle hybride permet à OpenAI de lever des fonds auprès d’investisseurs tout en respectant ses principes fondateurs de développer une intelligence artificielle générale (AGI ou IAG) bénéfique pour l’humanité. Les investisseurs ont un rendement plafonné, ce qui signifie qu’ils ne peuvent pas recevoir un retour illimité sur leurs investissements, tout excédent étant reversé à l’entité non lucrative, afin de maintenir l’objectif de la mission à long terme.
Un modèle qui pourrait être amené à changer puisque, selon Reuters, les investisseurs ont négocié des conditions qui leur permettraient de récupérer leur capital ou de renégocier la valorisation : le financement a été réalisé sous forme de billets convertibles, avec une conversion en actions conditionnée à un changement structurel réussi vers une entité à but lucratif, qui ne serait plus sous le contrôle du conseil d’administration de l’organisme à but non lucratif, ainsi qu’à la suppression du plafond des rendements pour les investisseurs.
La start-up, qui a connu depuis novembre dernier de nombreux rebondissements, plaintes et départs de dirigeants, a rapidement fait face à une concurrence féroce. Le succès fulgurant de ChatGPT ne s’est pas démenti, bien au contraire. La version gratuite continue de lui faire perdre des sommes importantes, tout comme le développement de ses nouveaux modèles. Les modèles d’IA tels que GPT consomment en effet une quantité considérable d’énergie et nécessitent des serveurs spécialisés pour traiter les requêtes en temps réel.
Ces pertes financières sont en partie compensées par ses trois produits phares : ChatGPT Enterprise (lancé en août 2023), Team (janvier 2024) et elle table sur un CA d’environ 3,7 milliards de dollars pour 2024.
Sarah Friar, directrice financière d’OpenAI, évoquant la levée de fonds et la facilité de crédit de 4 milliards de dollars avec JPMorgan Chase, Citi, Goldman Sachs, Morgan Stanley, Santander, Wells Fargo, SMBC, UBS et HSBC, affirme :
“Cette facilité de crédit renforce encore notre bilan et nous offre la flexibilité nécessaire pour saisir les opportunités de croissance futures. Nous sommes fiers d’avoir les banques et les investisseurs les plus solides au monde qui nous soutiennent”.
Levée de fonds historique de 6 milliards de dollars, facilité de crédit de 4 milliards : OpenAI conforte sa position de leader
Ce 1er octobre, le projet DATAWISE (Data Annotation Technology Advancement With Innovative Solutions for Efficiency), lauréat de l’AAP R&D Booster de la région AURA (Auvergne-Rhône-Alpes), est officiellement lancé. Porté par Neovision, en collaboration avec le laboratoire LIRIS (Laboratoire d’Informatique en Images et Systèmes d’Information), ce projet a pour objectif automatiser l’annotation des données, étape cruciale pour l’entraînement des modèles d’IA en vision par ordinateur.
Datawise
Ce 1er octobre, le projet DATAWISE (Data Annotation Technology Advancement With Innovative Solutions for Efficiency), lauréat de l’AAP R&D Booster de la région AURA (Auvergne-Rhône-Alpes), est officiellement lancé. Porté par Neovision, en collaboration avec le laboratoire LIRIS (Laboratoire d’Informatique en Images et Systèmes d’Information), ce projet a pour objectif automatiser l’annotation des données, étape cruciale pour l’entraînement des modèles d’IA en vision par ordinateur.
Datawise est l’un des projets labellisés par Minalogic, le pôle de compétitivité des technologies du numérique en Auvergne-Rhône-Alpes, retenus par le programme R&D Booster de la région AURA, dans la thématique “Intelligence Artificielle”. Ce dispositif vise à favoriser et soutenir des projets collaboratifs de R&D entre acteurs de la recherche académique et entreprises de la région pour concrétiser le développement de nouveaux produits, procédés ou services.
Ce projet d’automatisation d’annotation des données a été proposé par Neovision, une société grenobloise créée en 2014, experte en ML et computer vision, spécialisée dans le développement de solutions d’IA sur mesure et est mené en collaboration avec le LIRIS. Cette unité mixte de recherche (UMR 5205) du CNRS, de l’INSA de Lyon, de l’Université Claude Bernard Lyon 1, de l’Université Lumière Lyon 2 et de l’Ecole Centrale de Lyon, à laquelle nous avions consacré un article dans le n° 10 de notre magazine est largement reconnue pour ses travaux de pointe dans les domaines du traitement d’image, des systèmes d’information et des sciences des données.
Automatiser l’annotation des données : une réponse à un défi crucial
L’accès à de vastes volumes de données de qualité est essentiel pour le développement de modèles d’IA performants. Cependant, dans des domaines comme la vision par ordinateur, la préparation et l’annotation manuelles de ces données, fastidieuses et chronophages, représentent souvent un obstacle majeur.
Comme l’explique Stefan Duffner, chercheur au LIRIS,
“Cette préparation des données peut considérablement ralentir les cycles de développement des IAs et détourner les Data Scientists de leur cœur de métier : l’analyse et la valorisation des données”.
Ce partenariat allie l’innovation technologique du secteur privé aux dernières avancées académiques, créant une synergie propice à la création de solutions robustes et évolutives pour répondre aux besoins des secteurs industriels. Il permettra de développer des technologies capables d’automatiser non seulement l’annotation des données, mais également leur nettoyage, permettant ainsi d’accélérer le développement des modèles d’IA et d’en améliorer les performances tout en limitant les biais.
Lucas Nacsa, PDG et cofondateur de Neovision, explique :
“Les IA dédiées au traitement d’images sont souvent initialement entraînées sur des tâches simples, comme la reconnaissance de chiens ou de chats, avant de passer à des objets plus complexes. Cette méthode d’apprentissage limite parfois leurs performances. Notre ambition est de développer des modèles capables de s’entraîner directement sur des données industrielles complexes, sans nécessiter une préparation manuelle massive des données. Cela représente un bond en avant significatif en matière de performance et accélère considérablement le processus de création de solutions d’IA.”
Un partenariat stratégique
En automatisant l’annotation des données, DATAWISE ouvrira de nouvelles perspectives pour de nombreux secteurs industriels, en particulier ceux qui manipulent de grandes quantités de données visuelles. Les technologies développées dans le cadre de ce projet rendront les solutions d’IA plus accessibles et renforceront la compétitivité des entreprises, notamment en leur permettant d’exploiter des bases de données jusqu’ici sous-utilisées.
À terme, les partenaires envisagent l’intégration de grands modèles de langage (LLM) aux outils développés, afin d’améliorer l’ergonomie des solutions et ainsi encourager leur adoption par les entreprises.
Ce jeudi 12 septembre, OpenAI a lancé OpenAI o1, une nouvelle série de modèles d’IA dotés de capacités de raisonnement avancées pour résoudre des problèmes complexes. OpenAI o1, appelé en interne Strawberry, peut, selon la start-up, résoudre des problèmes plus difficiles que les modèles précédents en sciences, en codage et en mathématiques.
Dans son blog, OpenAI annonce: “Nous avons développé une nouvelle série de modèles d’IA conçus pour passer plus de temps à réfléchir avant de répondre”.
Les
Ce jeudi 12 septembre, OpenAI a lancé OpenAI o1, une nouvelle série de modèles d’IA dotés de capacités de raisonnement avancées pour résoudre des problèmes complexes. OpenAI o1, appelé en interne Strawberry, peut, selon la start-up, résoudre des problèmes plus difficiles que les modèles précédents en sciences, en codage et en mathématiques.
Dans son blog, OpenAI annonce: “Nous avons développé une nouvelle série de modèles d’IA conçus pour passer plus de temps à réfléchir avant de répondre”.
Les capacités de raisonnement avancées d’OpenAI o1 reposent sur la chaîne de pensée (chain of thought) et l’apprentissage par renforcement. La chaîne de pensée est le processus par lequel l’IA décompose un problème complexe en étapes logiques plus simples avant de fournir une réponse. Grâce à l’apprentissage par renforcement, o1 perfectionne cette chaîne de pensée et affine ses stratégies. Il apprend à identifier et corriger ses erreurs, à décomposer les étapes complexes en étapes plus simples, et à essayer une approche différente lorsque l’approche utilisée ne fonctionne pas.
Les modèles précédents, comme GPT-4o, répondent rapidement à des questions en se basant sur des patterns appris à partir de données massives. Toutefois, pour résoudre des tâches complexes, telles que des problèmes scientifiques, mathématiques ou logiques, un simple accès à une grande base de connaissances ne suffit pas toujours.
Cette nouvelle capacité à décomposer un problème en étapes et à tenter d’élaborer un jugement critique sur les réponses fournies afin de simuler une réflexion humaine est particulièrement utile dans les domaines nécessitant un raisonnement long et nuancé :
Mathématiques complexes : Résolution de problèmes en plusieurs étapes, où une simple erreur de calcul ou de logique dans une étape peut compromettre le résultat final ;
Programmation : Analyse des erreurs dans un code et élaboration d’une solution optimale après avoir envisagé plusieurs options ;
Sciences : Compréhension et application de théories scientifiques complexes pour résoudre des questions à plusieurs facettes.
La famille OpenAI o1
La famille o1 se compose pour l’instant de deux modèles : o1-preview et o1-mini, plus rapide, 80 % moins cher, excellant, selon OpenAI dans les STEM, en particulier les mathématiques et le codage, d’ores et déjà disponibles pour ChatGPT Plus et les développeurs de niveau 5 de l’API.
La start-up a évalué les performances de o1-preview, o1, la prochaine mise à jour du modèle, par rapport à celles de GPT-4o.
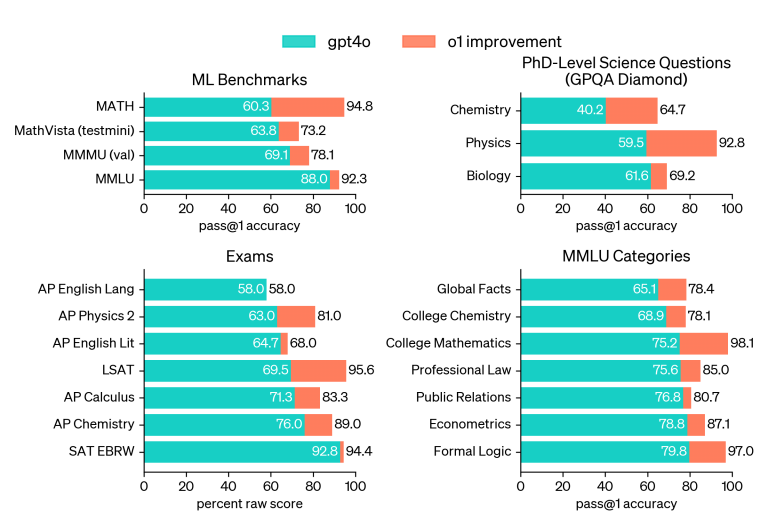
Sur le diamant GPQA, qui teste l’expertise en chimie, en physique et en biologie, o1 a surpassé les performances des experts titulaires d’un doctorat qu’elle avait recruté, devenant ainsi le premier modèle à le faire sur ce benchmark. Il s’est classé dans le 89e centile sur les questions de programmation compétitives de Codeforces et figure parmi les 500 meilleurs étudiants américains lors des qualifications pour les Olympiades de Mathématiques des États-Unis (AIME).
Crédit image : OpenAI. o1 s’améliore considérablement par rapport à GPT-4o sur les benchmarks de raisonnement difficiles. Les barres pleines montrent la précision pass@1 et la région ombrée montre la performance du vote majoritaire (consensus) avec 64 échantillons.
OpenAI o-1 a également surpassé GPT-4o sur 54 des 57 sous-catégories MMLU.
Crédit image : OpenAI. o1 s’améliore par rapport à GPT-4o sur un large éventail de benchmarks, y compris les sous-catégories MMLU 54/57. Sept sont illustrés.
OpenAI prévoit des mises à jour et des améliorations régulières. Ces modèles sont en phase préliminaire, les fonctionnalités telles que la navigation sur le web pour obtenir des informations ou le téléchargement de fichiers et d’images ne sont pas encore disponibles.
La start-up conclut sa présentation ainsi :
“Ces capacités de raisonnement améliorées peuvent être particulièrement utiles si vous vous attaquez à des problèmes complexes en sciences, en codage, en mathématiques et dans des domaines similaires. Par exemple, o1 peut être utilisé par les chercheurs du secteur de la santé pour annoter les données de séquençage cellulaire, par les physiciens pour générer des formules mathématiques complexes nécessaires à l’optique quantique et par les développeurs de tous les domaines pour créer et exécuter des flux de travail en plusieurs étapes.”
La génération de données structurées à partir d’entrée non structurée est l’un des principaux cas d’utilisation de l’IA dans les applications. Cependant, garantir que les modèles d’IA génèrent des sorties conformes à des formats stricts, comme les schémas JSON, a toujours été un défi. Pour répondre à cette problématique, OpenAI a récemment introduit “Structured Outputs” dans son API, une nouvelle fonctionnalité conçue pour que les réponses générées par le modèle respectent exactement les schémas
La génération de données structurées à partir d’entrée non structurée est l’un des principaux cas d’utilisation de l’IA dans les applications. Cependant, garantir que les modèles d’IA génèrent des sorties conformes à des formats stricts, comme les schémas JSON, a toujours été un défi. Pour répondre à cette problématique, OpenAI a récemment introduit “Structured Outputs” dans son API, une nouvelle fonctionnalité conçue pour que les réponses générées par le modèle respectent exactement les schémas JSON fournis par les développeurs.
Les développeurs ont longtemps été confrontés à la difficulté de s’assurer que les LLMs produisent des sorties JSON conformes aux attentes. Bien que des améliorations comme le mode JSON, introduit l’an passé par OpenAI, aient permis de produire des sorties plus fiables, ces modèles ne pouvaient pas toujours garantir une correspondance exacte avec des schémas complexes. Une incertitude qui obligeait les développeurs à recourir à des solutions de contournement, comme l’utilisation d’outils open source ou la répétition de requêtes, pour ajuster manuellement les sorties du modèle.
La solution : Structured Outputs
Les sorties structurées introduites par OpenAI changent la donne en offrant une solution claire à ce problème. L’une de leurs principales forces est leur capacité à améliorer la fiabilité des modèles d’IA dans des cas d’utilisation critiques, tels que l’extraction de données structurées, la saisie de données ou encore la gestion de flux de travail complexes. En éliminant le besoin d’interventions manuelles, les sorties structurées permettent aux développeurs de se concentrer sur la création d’applications plus sophistiquées et plus robustes.
Lors d’évaluations internes de schémas JSON complexes réalisées par OpenAI, le modèle gpt-4o-2024-08-06 utilisant cette nouvelle fonctionnalité a atteint une fiabilité de 100%, surpassant largement les versions précédentes, notamment gpt-4-0613, qui avait obtenu un score inférieur à 40 %.
Deux approches pour une flexibilité maximale
OpenAI a introduit les sorties structurées sous deux formes dans son API, offrant ainsi une flexibilité optimale pour les développeurs :
Via l’appel de fonction : les développeurs peuvent activer les sorties structurées en les définissant dans la définition de fonction utilisée, par exemple en utilisant strict: true dans les paramètres de l’outil. Cette méthode est compatible avec tous les modèles prenant en charge les outils, et garantit que les résultats générés par le modèle sont conformes aux spécifications de l’outil défini. Cette approche est idéale pour les scénarios où le modèle doit interagir avec des systèmes complexes via des appels d’API ;
Via le paramètre “response_format” : pour les cas où le modèle répond directement à l’utilisateur sans appel d’outil, OpenAI a introduit le paramètre response_format. Cette nouvelle option permet de fournir un schéma JSON que le modèle doit suivre pour générer sa réponse. Disponible avec les nouveaux modèles GPT-4o, cette approche assure que la sortie du modèle est strictement conforme au schéma fourni, même sans utilisation d’un outil externe.
Respect des politiques de sécurité
Les sorties structurées respectent les politiques de sécurité existantes d’OpenAI : même avec cette nouvelle fonctionnalité, le modèle conserve la capacité de refuser de répondre à une demande qu’il considère comme non sécurisée.
Pour faciliter le travail des développeurs, OpenAI a introduit une nouvelle valeur de chaîne dans les réponses de l’API qui permet de détecter par programmation si le modèle a refusé de répondre à une demande plutôt que de produire une sortie conforme au schéma fourni.
OpenAI a également mis à jour ses SDK Python et Node pour qu’ils prennent en charge nativement les sorties structurées, afin de faciliter l’intégration de cette nouvelle fonctionnalité dans leurs applications.
Structured Outputs, la réponse d'OpenAI aux défis des schémas JSON
“Permettre aux entreprises de concilier innovation et respect des droits des personnes” : tel est l’objectif que la CNIL (Commission Nationale de l’Informatique et des Libertés) poursuit avec ses recommandations. Après avoir soumis une première série de fiches pratiques à consultation publique en 2023, à l’issue de laquelle elle a publié le 8 avril dernier ses premières recommandations sur l’application du RGPD au développement des systèmes d’IA, elle lance une nouvelle consultation publique por
“Permettre aux entreprises de concilier innovation et respect des droits des personnes” : tel est l’objectif que la CNIL (Commission Nationale de l’Informatique et des Libertés) poursuit avec ses recommandations. Après avoir soumis une première série de fiches pratiques à consultation publique en 2023, à l’issue de laquelle elle a publié le 8 avril dernier ses premières recommandations sur l’application du RGPD au développement des systèmes d’IA, elle lance une nouvelle consultation publique portant sur une deuxième série de fiches pratiques et un questionnaire consacré à l’encadrement du développement des systèmes d’IA.
Pour la CNIL, le RGPD a vocation à s’appliquer à l’ensemble des traitements de données personnelles, à la fois dans le secteur public et le secteur privé, à l’exception toutefois des traitements relevant du régime spécifique aux secteurs “police-justice” ou du régime intéressant la défense nationale ou la sûreté de l’État.
Les principaux acteurs français de l’IA, qu’il s’agisse d’entreprises, de laboratoires ou encore des pouvoirs publics, rencontrés par la CNIL, ont fait remonter un fort besoin de sécurité juridique mais aussi des inquiétudes liées au RGPD : selon certains, ses principes de finalité, de minimisation, de conservation limitée et de réutilisation restreinte freineraient voire empêcheraient certaines recherches ou applications de l’intelligence artificielle. Les 7 premières fiches ont donc abordé ces problèmes et ont également clarifié certaines règles applicables à la recherche scientifique, à la réutilisation de bases de données ou à la réalisation d’analyse d’impact sur la protection des données (AIPD).
Dans la continuité de ces travaux et afin d’apporter des réponses complémentaires aux interrogations partagées par les professionnels, les 7 fiches de cette seconde consultation traitent plusieurs questions majeures d’innovation et de protection :
L’encadrement du web scraping : le développement des systèmes d’IA nécessite souvent l’accès à des bases de données volumineuses, collectées en ligne. Le web scraping, largement utilisé pour cette collecte, doit être rigoureusement encadré pour respecter les droits des personnes dont les données sont utilisées. La CNIL propose de centraliser un registre volontaire pour améliorer l’information des personnes concernées et faciliter l’exercice de leurs droits ;
Open source, transparence et collaboration : la publication de modèles d’IA en open source est bénéfique pour la transparence et la collaboration au sein de l’écosystème IA. Elle permet la vérification par les pairs et l’amélioration continue des modèles. Toutefois, cette pratique doit être accompagnée de garanties pour prévenir les utilisations malveillantes et assurer la sécurité des données. La CNIL insiste sur la nécessité de suivre les modèles et leurs évolutions pour permettre une information et un exercice des droits effectifs ;
Base légale d’intérêt légitime : l’intérêt légitime est souvent mobilisé comme base légale pour le traitement des données personnelles dans le développement de l’IA. Cette base exige une évaluation rigoureuse des risques pour les personnes et la mise en œuvre de conditions spécifiques pour protéger leurs données. La CNIL fournit des éléments concrets pour aider les responsables de traitement à respecter ces exigences, notamment lors de l’utilisation de techniques de web scraping ou de la publication de modèles en open source ;
Information et exercice du droit des personnes : la CNIL souligne l’importance de placer l’information et l’exercice des droits des individus au cœur des systèmes d’IA qui utilisent des données personnelles. Pour être en conformité, les développeurs doivent informer clairement les personnes concernées sur l’utilisation de leurs données et permettre l’exercice effectif de leurs droits, comme le droit à l’information, à la rectification et à la suppression. La CNIL fournit des directives pour aider à respecter ces obligations et précise les situations où des dérogations sont possibles. Elle aborde aussi les défis posés par les droits individuels face à la nature statistique des IA, en offrant des solutions pour le droit de rectification et de suppression.
Applicabilité du RGPD aux modèles d’IA
La question de l’application du RGPD aux modèles d’IA eux-mêmes se pose, notamment en ce qui concerne la sécurisation des modèles et la protection contre la mémorisation et l’extraction des informations issues de l’entraînement. La CNIL sollicite les avis des professionnels via un questionnaire dédié de cette consultation publique.
Pour la CNIL :
“Le développement de systèmes d’IA est conciliable avec les enjeux de protection de la vie privée. Plus encore, la prise en compte de cet impératif permettra de faire émerger des dispositifs, outils et applications éthiques respectueux des droits et libertés fondamentaux. C’est à cette condition que les citoyens feront confiance à ces technologies”.
Si vous désirez contribuer à ses travaux, la consultation publique est ouverte jusqu’au 1er septembre prochain. Vous pouvez retrouver les 7 fiches soumises à consultation ici et retrouver le formulaire de participation via ce lien.
En mai 2023, SAS, pionnier dans les solutions d’IA et de données, s’engageait à investir 1 milliard de dollars d’ici 2026 afin de poursuivre le développement de solutions analytiques avancées, ciblées sur les besoins spécifiques de certaines industries. Aujourd’hui, à l’occasion de SAS Innovate, son évènement phare à destination des chefs d’entreprise, des utilisateurs techniques et de ses partenaires, la société a dévoilé un ensemble de modèles d’IA légers qui viennent compléter les solutions e
En mai 2023, SAS, pionnier dans les solutions d’IA et de données, s’engageait à investir 1 milliard de dollars d’ici 2026 afin de poursuivre le développement de solutions analytiques avancées, ciblées sur les besoins spécifiques de certaines industries. Aujourd’hui, à l’occasion de SAS Innovate, son évènement phare à destination des chefs d’entreprise, des utilisateurs techniques et de ses partenaires, la société a dévoilé un ensemble de modèles d’IA légers qui viennent compléter les solutions existantes de la plateforme SAS Viya.
L’annonce de l’investissement s’inscrivait dans la lignée de la démocratisation de l’analyse des données, engagement majeur de SAS. Les salariés peuvent d’ailleurs participer au processus analytique de leur entreprise quel que soit leur niveau de compétence, grâce aux options low code / no code, fournies par les solutions fonctionnant sur sa plateforme analytique d’IA et cloud native, SAS Viya.
Pour rester compétitives, de plus en plus d’entreprise se tournent désormais vers l’IA mais se trouvent confrontées à un défi de taille : la pénurie de compétences en IA, notamment de spécialistes en data science.
Fort de son expertise dans le domaine, SAS capitalise sur des décennies d’expérience dans le déploiement de modèles d’IA évolutifs et fiables pour divers secteurs tels que la finance, la santé et l’industrie ou les institutions gouvernementales. Avant cet investissement de mai dernier, SAS proposait déjà un large éventail de solutions sectorielles, elle élargit son portefeuille avec des modèles d’IA légers et prêts à l’emploi, facilement adaptables aux besoins spécifiques des entreprises, allant de la détection de fraudes à l’optimisation de la chaîne d’approvisionnement, en passant par la gestion des entités et la vérification de la conformité des paiements des frais de santé.
Démocratiser l’IA
Les premiers modèles SAS qui devraient être disponibles cette année seront eux aussi accessibles indépendamment du niveau de compétence. La société, qui vise désormais à démocratiser l’IA générative, a développé un assistant IA pour l’optimisation des entrepôts qui pourra être adapté pour d’autres cas d’utilisation.
Udo Sglavo, Vice-Président de l’IA et de l’analytique chez SAS, affirme :
“Les modèles SAS fournissent aux organisations une IA flexible, précise et accessible qui s’aligne aux défis de chaque secteur. Que vous débutiez votre parcours dans l’IA ou que vous cherchiez à accélérer l’expansion de l’IA dans votre entreprise, SAS répond aux besoins uniques de votre entreprise avec une acuité et une ampleur inégalées”.
Viya Workbench, un environnement de développement flexible et évolutif
SAS a également annoncé la prochaine disponibilité de SAS Viya Workbench, offrant un libre accès à un environnement de calcul dans le cloud, idéal pour la préparation des données, l’analyse exploratoire et le développement de modèles analytiques et d’apprentissage automatique.
SAS Viya Workbench permet aux utilisateurs de travailler dans le langage de leur choix, initialement SAS et Python, avec l’intégration prévue du langage R à l’avenir. Cette flexibilité est soutenue par une interface intuitive offrant deux options d’environnement de développement : Jupyter Notebook/JupyterLab et Visual Studio Code.
Grâce à l’utilisation des procédures analytiques de SAS (PROCs) et des API Python natives, les développeurs peuvent accélérer le développement de modèles performants d’IA. De plus, des bibliothèques Python personnalisées uniques à Viya Workbench permettent d’augmenter la vitesse et les performances des modèles avec peu d’efforts.
L’environnement de développement Viya Workbench est conçu pour être évolutif et disponible sur demande, avec une gestion automatique des ressources et une puissance de calcul CPU/GPU personnalisable pour répondre aux besoins des projets. Les modèles et les résultats obtenus peuvent ensuite être intégrés dans la plateforme SAS Viya pour une gestion optimale des données, une gouvernance renforcée et un déploiement opérationnel efficace.
Cette annonce répond à une série de défis rencontrés par les développeurs d’IA, notamment la nécessité de travailler avec des outils modernes et des capacités de calcul avancées, tout en gérant les coûts et en recherchant des infrastructures pré-construites et évolutives.
Jared Peterson, Senior Vice President chez Engineering, SAS, explique :
“Les multiples défis auxquels les développeurs font face ne sont pas à prendre à la légère. Au contraire, ce sont des obstacles qui les empêchent de répondre aux questions importantes et d’accomplir leurs tâches. Viya Workbench offre une flexibilité maximale et des résultats optimaux en permettant aux développeurs d’utiliser le langage et l’environnement de développement intégré (IDE) de leur choix, d’ajuster la puissance de calcul à la hausse comme à la baisse selon les besoins du projet, et, in fine, d’améliorer leur productivité et leur efficacité. Ils peuvent travailler plus rapidement, être plus créatifs et prendre plus de risques – ce qui, soyons honnêtes, est non seulement attendu, mais rend également le travail plus agréable.”
Viya Workbench sera initialement disponible sur Amazon AWS Marketplace au deuxième trimestre. D’autres fournisseurs de cloud seront progressivement pris en charge, ainsi que des projets liés à une option de déploiement en SaaS.
SAS renforce son offre avec des modèles d'IA prêts à l'emploi