L'encyclopédie en ligne Wikipédia n'ignore pas l'explosion des textes produits par les systèmes d'IA générative. Pour l'essentiel, leur usage pour écrire des articles est prohibé. Mais à la marge, il y a quelques exceptions tolérées.
Révélée le 11 décembre 2025, la « Person of the Year » du célèbre TIME Magazine distingue « les architectes de l’IA ». Parmi les huit personnalités en image de Une, figurent deux femmes : Lisa Su et Fei-Fei Li.
Une simulation assistée par une intelligence artificielle a dévoilé une nouvelle carte de la Voie lactée, plus précise que jamais. Le résultat contient 100 milliards d'étoiles et leur évolution sur 100 000 ans.
Google aussi rêve d'espace. Littéralement. L'entreprise américaine a dévoilé début novembre 2025 le projet Suncatcher. L'idée ? Lancer des data centers dédiés à l'IA en orbite autour de la Terre. Malgré les défis, la société américaine y croit et ne voit pas d'obstacle absolu.
Le débat autour d'une conscience potentielle qui finirait par émerger dans un système d'intelligence artificielle a repris de la vigueur avec les récents développements du secteur. Mais pour le patron de l'IA chez Microsoft, c'est une question mal posée. Il assure qu'il y a une limite fondamentale qui empêchera l'IA d'être consciente.
Que faire quand il n'existe pas un « YouTube pour les robots » sur lequel s'appuyer pour entraîner des robots ? Il faut en construire un. C'est l'approche suivie par la société de robotique Figure, qui va utiliser des caméras en vue subjective (POV).
Emmanuel Macron a présenté l'Inde comme un partenaire central de la France dans l'intelligence artificielle. Une alliance entre Paris et New Delhi nécessaire pour échapper à la rivalité et à la domination de la Chine et des États-Unis. Mais ce rapprochement s'inscrit aussi dans une perspective géostratégique entre la France et l'Inde.
Lancé par ServiceNow, AgentLab est un framework open source visant à faciliter le développement et l’évaluation d’agents Web. Son objectif principal est de soutenir les expériences d’automatisation des tâches sur les plateformes Web, en permettant aux chercheurs et développeurs de simuler des interactions complexes à travers divers benchmarks de BrowserGym.
AgentLab a été développé pour gérer des défis dynamiques et variés liés au Web. Il permet de tester et évaluer un agent Web dans des environnements simulés complexes afin d’affiner ses capacités et garantir sa fiabilité dans des applications réelles.
Le framework exploite l’outil de parallélisation Ray, spécifiquement conçu pour les applications de machine learning et les programmes écrits en Python, pour mener des expériences à grande échelle, ce qui permet d’évaluer les performances des agents dans plusieurs scénarios et configurations.
Le framework fournit des blocs de construction pour BrowserGym, un environnement Gym conçu pour l’automatisation des tâches web. Il permet de concevoir, tester et évaluer des agents web sur divers benchmarks établis tels que :
WebArena : teste les agents sur des interactions web complexes, comme la navigation et l’extraction de données ;
WorkArena : simule des tâches spécifiques liées à des flux de travail professionnels, tels que commander des produits ou gérer des tableaux de bord ;
AssistantBench : évalue les capacités conversationnelles des agents intégrés à des modèles linguistiques.
AgentLab propose une API unifiée pour intégrer des modèles avancés, tels que les LLMs d’OpenAI, Azure, OpenRouteur et des modèles auto-hébergés. Cette flexibilité permet aux développeurs de tester des technologies de pointe dans des simulations réalistes. Il inclut des mécanismes intégrés pour suivre les configurations, les versions logicielles et les benchmarks utilisés dans les expériences. Ces fonctionnalités garantissent que les résultats peuvent être reproduits de manière fiable.
Comment fonctionne AgentLab ?
L’utilisation d’AgentLab implique généralement les étapes suivantes :
Configuration initiale : Installation des packages et benchmarks nécessaires via l’outil Python pip. Par exemple, les chercheurs peuvent utiliser browsergym-core pour les fonctionnalités de base ou browsergym-webarena pour des tâches spécifiques à WebArena.
Définir l’environnement : Les utilisateurs spécifient l’environnement de la tâche, tel qu’une URL de départ ou un scénario de benchmark prédéfini.
Implémentation de l’agent : Les développeurs conçoivent des agents en mettant en œuvre les API et actions requises. Par exemple, un agent pourrait être programmé pour naviguer dans un formulaire web ou récupérer des données spécifiques d’une page web.
Boucle d’évaluation : Les agents interagissent avec l’environnement dans une boucle, recevant des observations et effectuant des actions jusqu’à ce que la tâche soit terminée ou interrompue.
Analyse des résultats : Les résultats sont enregistrés et visualisés pour évaluer les performances des agents. Les fonctionnalités de reproductibilité permettent aux chercheurs de répéter les expériences avec les mêmes paramètres pour valider les conclusions.
AgentLab continue d’évoluer, ses développeurs travaillent à étendre ses benchmarks et ses fonctionnalités pour prendre en charge un éventail encore plus large de cas d’utilisation.
AgentLab, un framework open source pour le développement et l’évaluation des agents Web
OpenAI se prépare à lancer un agent d'intelligence artificielle autonome capable de contrôler des ordinateurs et d'effectuer des tâches de manière indépendante
Comme il l’avait annoncé en septembre dernier à l’occasion de sa levée de fonds de 5,5 millions d’euros, Probabl, l’opérateur officiel de la bibliothèque open source incontournable pour le ML, scikit-learn, a lancé le 31 octobre dernier, en partenariat avec Inria et Artefact, le premier programme de certification officiel scikit-learn.
Fondée en septembre 2023, issue d’un projet confié à Inria par le secrétariat général pour l’investissement dans le cadre de France 2030, la start-up Probabl propose des solutions et des services basés sur la bibliothèque open-source d’apprentissage statistique en Python “scikit-learn”, l’une des plus utilisées dans le monde avec PyTorch et TensorFlow,“afin de pérenniser son existence et d’assurer son rayonnement”.
Scikit-learn : une bibliothèque open-source au cœur de l’écosystème du machine learning
Avec plus de 80 millions de téléchargements par mois, scikit-learn est devenue incontournable pour les data scientists et les chercheurs. En tant que bibliothèque open source, elle favorise une approche transparente et collaborative de la technologie, loin des solutions propriétaires qui limitent la flexibilité. Elle permet ainsi aux entreprises et aux chercheurs de concevoir des solutions sans les contraintes imposées par certains fournisseurs, un point particulièrement apprécié par la communauté technologique européenne.
Probabl souligne dans son communiqué :
“Scikit-learn est un composant essentiel pour d’innombrables projets, jouant un rôle fondamental dans près d’un million de projets et plus de 15 000 packages structurés. Elle est une pièce maîtresse de l’écosystème plus large qui stimule l’innovation en machine learning et en science des données”.
Avec la première certification officielle de scikit-learn, Probabl entend établir une nouvelle référence pour la formation de base en IA.
Une certification pour soutenir la montée en compétence en machine learning
Probabl a conçu ce programme en collaboration avec des membres clés de l’équipe scikit-learn, des experts de l’industrie et des formateurs renommés. Ce programme de certification vise à répondre aux attentes croissantes des employeurs pour des compétences vérifiables dans la data science, tout en renforçant l’utilisation éthique et responsable de l’IA.
Yann Lechelle, co-fondateur et PDG de Probabl, souligne l’importance d’une telle reconnaissance :
“Offrir un programme de certification mondial aux utilisateurs et formateurs de scikit-learn est essentiel pour reconnaître et valider les centaines, voire les milliers d’heures que les data scientists du monde entier ont consacrées à la maîtrise de ce framework. Cela établira une norme d’excellence pour maximiser leur capacité à générer de la valeur commerciale dans le machine learning et l’IA”.
Un parcours en trois niveaux pour répondre aux besoins de tous les professionnels
Le programme est structuré en trois niveaux : Associé, Professionnel et Expert, correspondant à des étapes spécifiques d’évolution dans une carrière en data science. L’objectif est de fournir une montée en compétence progressive, allant des fondamentaux pour les novices jusqu’aux applications complexes pour les experts du secteur. Ce parcours est accessible à tous, quelle que soit l’étape de carrière ou les origines des candidats.
Probabl souhaite ainsi répondre aux besoins des candidats en reconversion professionnelle, des débutants en data science, ainsi que des professionnels confirmés souhaitant renforcer leur expertise. Cette approche inclusive est soutenue par la plateforme sécurisée Webassessor de Kryterion, qui permet aux candidats de passer leurs examens en ligne, où qu’ils se trouvent. Ces examens évaluent rigoureusement leur capacité à appliquer les connaissances théoriques dans des scénarios réels. En cas de succès, un badge numérique délivré par Credly certifie les compétences acquises, que les candidats peuvent partager sur LinkedIn et d’autres plateformes professionnelles.
Inria et Artefact, des partenaires de premier plan pour un programme de qualité
Inria, institut français de recherche en sciences du numérique, joue un rôle clé dans le soutien à scikit-learn depuis sa création. Sa participation garantit que les certifications scikit-learn resteront alignées sur les dernières avancées académiques.
Artefact, expert en applications industrielles du machine learning, apporte sa vision pratique et son savoir-faire en entreprise, contribuant ainsi à un programme de certification qui répond aux réalités des usages en entreprise. Ce partenariat assure que la certification scikit-learn, soutenue par la rigueur académique et l’expertise pratique, bénéficiera autant aux chercheurs qu’aux entreprises.
En unissant des valeurs académiques, des exigences éthiques et des compétences industrielles, ce programme aspire à établir un nouveau standard pour la communauté des data scientists, où la maîtrise technique se conjugue à la responsabilité.
Probabl lance le premier programme de certification Scikit-learn
Le prix Nobel de physique 2024 a été décerné à John Hopfield et Geoffrey Hinton pour leurs travaux fondateurs sur les réseaux de neurones artificiels. Aujourd'hui, les chercheurs poursuivent dans cette voie en explorant les défis actuels, notamment en combinant des briques logicielles et matérielles pour émuler le cerveau.
Teradata a annoncé hier la nomination de Thomas Schröder en tant que vice-président Europe. A ce poste stratégique, Schröder sera en charge de superviser les opérations de Teradata dans toute l’Europe, y compris des marchés majeurs comme l’Europe centrale, l’ouest, le sud et l’est, le Royaume-Uni, l’Irlande, la Scandinavie, et Israël.
Un leader expérimenté pour diriger la stratégie européenne
Thomas Schröder, qui possède plus de deux décennies d’expérience dans la vente et le management, a rejoint Teradata en octobre 2022 en tant que vice-président pour l’Europe centrale, un poste incluant la France et le Benelux. Il avait auparavant fait ses preuves en tant que leader au sein d’entreprises technologiques mondiales, notamment Vodafone Enterprise, le groupe d’entreprises et de partenaires de Microsoft Allemagne, Oracle Hardware Sales, Sun Microsystems, ou encore Philips Business Communications Allemagne.
En tant que vice-président Europe, Thomas Schröder sera responsable du développement et de la mise en œuvre de la stratégie Go-To-Market, tout en supervisant les ventes et les opérations de l’entreprise dans la région. Son principal objectif sera d’accompagner les clients de Teradata dans la maximisation du potentiel de l’IA et du Machine Learning afin d’optimiser leur retour sur investissement et de renforcer leur compétitivité sur le marché, en tirant parti de la plateforme VantageCloud de Teradata.
Richard Petley, CRO de Teradata, souligne l’importance de cette nomination :
“Nous sommes ravis d’accueillir un dirigeant aussi talentueux que Thomas Schröder à ce poste clé. Son expertise et sa connaissance approfondie du marché européen sont des atouts précieux pour notre entreprise. Sa nomination représente une étape naturelle dans sa carrière, et je suis convaincu qu’il continuera à renforcer notre présence et à stimuler notre croissance en Europe”.
Un engagement envers une IA éthique et responsable
Thomas Schröder a exprimé son enthousiasme à l’idée de relever ce nouveau défi :
“Je suis honoré de prendre la direction de la région Europe pour Teradata. Avec le soutien d’une équipe d’experts chevronnés, je suis convaincu que nous pouvons démontrer chaque jour la valeur ajoutée de notre technologie à nos clients et partenaires. Grâce à notre plateforme VantageCloud Lake et ClearScape Analytics, nous sommes idéalement positionnés pour aider les entreprises à obtenir des résultats rapides et durables à partir de leurs initiatives IA/ML, tout en veillant à une utilisation éthique et responsable de l’IA”.
Sous la direction de Thomas Schröder, Teradata entend renforcer son rôle de leader dans le domaine des données et de l’analytique en Europe, en aidant les entreprises à transformer leurs données en avantages concurrentiels grâce à l’IA.
Thomas Schröder nommé vice-président Europe chez Teradata pour accélérer l'innovation en IAML
OVHcloud, le géant européen du cloud, annonce un partenariat stratégique avec Valohai, une plateforme leader dans le domaine des MLOps (Machine Learning Operations). Cette collaboration s’inscrit dans le cadre du programme Open Trusted Cloud d’OVHcloud et vise à permettre aux entreprises de toutes tailles d’optimiser leurs workflows d’IA et de ML.
Le programme Open Trusted Cloud d’OVHcloud s’adresse aux éditeurs de logiciels (ISV) ainsi qu’aux fournisseurs de solutions SaaS et PaaS. Son ambition est de co-construire un écosystème de services SaaS et PaaS, hébergé dans le cloud ouvert, réversible et fiable d’OVHcloud, afin de proposer une plateforme commune de solutions compétitives, dans le respect des valeurs européennes de confiance et de souveraineté. Ce partenariat stratégique avec Valohai s’inscrit parfaitement dans la vision du programme et dans l’engagement d’OVHcloud pour la démocratisation de l’IA.
Une collaboration pour transformer le développement de l’IA
En combinant l’infrastructure robuste et évolutive d’OVHcloud avec la plateforme MLOps avancée de Valohai, ce partenariat offre aux entreprises un environnement optimal pour le développement de l’IA. OVHcloud, reconnu pour ses solutions cloud sécurisées et conformes aux réglementations européennes, met à disposition ses GPUs haute performance, ce qui permet aux utilisateurs de Valohai d’automatiser et de gérer leurs projets de machine learning avec une efficacité accrue.
Conçue pour supporter l’intégration et la livraison continues (CI/CD) pour les projets de ML, Valohai offre une traçabilité et une reproductibilité complète. Sa plateforme peut gérer des environnements cloud, multicloud et hybrides, ainsi que des environnements sur site et isolés (“air-gap”), en faisant une solution polyvalente pour divers besoins de développement d’IA. Les fonctionnalités de Valohai simplifient la collaboration, le versionning et la conformité réglementaire, permettant aux équipes de se concentrer sur l’innovation et l’efficacité.
L’intégration avec OVHcloud permet de gérer aisément l’intégralité du cycle de vie des projets IA, de l’ingestion des données jusqu’au déploiement des modèles sur ces environnements cloud variés.
Des avantages décisifs pour les entreprises
Ce partenariat présente plusieurs avantages majeurs pour les entreprises :
Performances optimisées et scalabilité : L’association de l’infrastructure évolutive d’OVHcloud avec la gestion des pipelines ML de Valohai assure des performances de pointe et une adaptabilité aux besoins spécifiques des entreprises ;
Souveraineté des données : Les entreprises peuvent bénéficier d’un cloud de confiance, conforme au RGPD, garantissant la sécurité et la confidentialité des données, un aspect crucial dans le contexte actuel de régulation stricte en Europe ;
Maîtrise des coûts : Grâce à la tarification compétitive d’OVHcloud et aux outils de gestion de ressources proposés par Valohai, les entreprises peuvent contrôler leurs dépenses tout en maximisant l’efficacité de leurs opérations IA.
Toni Perämäki, COO de Valohai, commente :
“L’association de la plateforme MLOps de pointe de Valohai à l’infrastructure sécurisée et évolutive d’OVHcloud crée une proposition de valeur unique pour les entreprises souhaitant optimiser leurs processus de développement de l’IA. Nous sommes ravis de travailler avec OVHcloud pour faire progresser l’innovation et soutenir les organisations dans leur parcours d’IA”.
Yaniv Fdida, Chief Product and Technology Officer d’OVHcloud, conclut :
“Notre collaboration avec Valohai s’aligne parfaitement avec la mission d’OVHcloud de démocratiser l’IA et de la rendre accessible et abordable pour les entreprises de toutes tailles. Ensemble, nous proposons une solution de bout en bout qui permet aux organisations d’accélérer leurs initiatives en matière d’IA avec confiance et efficacité”.
OVHcloud s'alllie à Valohai pour renforcer les workflows d'IA et de ML
La langue peut révéler beaucoup sur notre santé : sa forme, sa texture, le fait qu’elle soit humide ou sèche et surtout sa couleur sont autant d’informations sur des maladies potentielles. Des chercheurs de l’Université Technique du Moyen-Orient en Irak, et de l’Université d’Australie du Sud (UniSA) ont utilisé le machine learning pour analyser les couleurs de la langue afin de prédire les maladies associées. Le système d’imagerie proposé dans leur étude a atteint une précision de 96,6 %.
Lorsqu’une personne est en bonne santé, sa langue est généralement de couleur rose avec un léger revêtement blanc. Diverses maladies peuvent modifier ces caractéristiques, par exemple :
Une couche jaune sur la langue peut être signe de diabète. En cas de diabète de type 2, la langue peut devenir bleue avec un revêtement jaune ;
Une langue violette avec un revêtement épais peut être un signe de cancer ;
Lors des phases aiguës d’accident vasculaire cérébral (AVC), les patients peuvent présenter une langue rouge avec une forme inhabituelle ;
Une langue blanche peut indiquer une anémie ou carence en fer ;
Une langue jaune peut signaler une augmentation de la chaleur corporelle ou une maladie des organes hépatiques et biliaires ;
Une langue de couleur indigo ou violette peut être signe de problèmes vasculaires ou gastro-intestinaux ;
La langue peut apparaître rougeâtre avec des marques blanches lors d’une infection à helicobacter pylori ;
Des modifications visibles peuvent apparaître à la surface de la langue en cas d’appendicite.
L’infection par le virus COVID-19 peut également influencer la couleur de la langue, la faisant apparaître légèrement rose dans les cas bénins, cramoisi dans les infections modérées, et rouge foncé (bordeaux) dans les cas graves, souvent accompagnée d’inflammation et d’ulcérations.
Grâce aux avancées des systèmes de vision par ordinateur et de l’IA, il est désormais possible de développer des systèmes automatisés pour analyser ces caractéristiques de manière plus précise et reproductible. Cette étude présente un nouveau système d’imagerie capable d’analyser et d’extraire les caractéristiques de couleur de la langue sous différentes conditions d’éclairage et de saturations de couleurs, permettant ainsi un diagnostic en temps réel des maladies associées.
Les chercheurs ont utilisé cinq modèles d’espace colorimétrique (RGB, YcbCr, HSV, LAB et YIQ) et six algorithmes d’apprentissage automatique pour prédire la couleur de la langue et, par extension, les maladies associées : Naïve Bayes (NB), Support Vector Machine (SVM), k-plus proches voisins (KNN), arbres de décision (DT), forêt aléatoire (RF) et Extreme Gradient Boost (XGBoost).
Collecte des données
Pour leur étude, les chercheurs ont tout d’abord utilisé un premier ensemble de données comprenant 5260 images de langue classées en sept catégories de couleurs (rouge, jaune, vert, bleu, gris, blanc, rose). Ces images ont été extraites dans différentes conditions de saturation et d’éclairage, 80% ont été utilisées pour l’entraînement des algorithmes d’apprentissage automatique et les 20% restants à des fins de test.
Le deuxième groupe de données comprenait 60 images anormales de la langue qui ont été collectées à l’hôpital universitaire Al-Hussein de Dhi Qar, en Irak, et à l’hôpital général de Mossoul à Mossoul de janvier 2022 à décembre 2023 pour tester le système d’imagerie proposé en temps réel. Ces images de la langue comprenaient des patients atteints de diverses affections, notamment le diabète, l’infection mycosique, l’asthme, le COVID-19, les papilles fongiformes et l’anémie.
Configuration expérimentale
Le système d’imagerie proposé se compose d’une webcam USB haute résolution connectée à un ordinateur portable exécutant MATLAB. Le patient s’assoit à 20 cm de la caméra, le système capture une image de la langue qui est analysée en temps réel. Une interface graphique (GUI), développée avec MATLAB App Designer, facilite cette analyse en affichant les valeurs de chaque teinte, la couleur identifiée, l’histogramme des couleurs, et les maladies potentielles associées.
Analyse d’images et algorithmes d’apprentissage
Après la capture de l’image, une méthode de segmentation a été utilisée pour isoler la région d’intérêt (ROI) de la langue, éliminant les éléments non pertinents comme les lèvres ou les dents. Les images sont ensuite converties des couleurs RGB vers les espaces YCbCr, HSV, LAB, et YIQ pour une analyse approfondie. Les données ainsi obtenues sont enregistrées en format CSV et ont servi de base pour l’entraînement des algorithmes d’apprentissage automatique.
Résultats
L’évaluation des différents algorithmes a montré que l’algorithme XGBoost offrait la meilleure précision, atteignant 98,71 %, suivi par les autres méthodes avec des précisions légèrement inférieures. Le Naive Bayes, bien qu’efficace, a montré la précision la plus faible à 91,43 %.
En se basant sur ces résultats, les chercheurs ont sélectionné l’algorithme XGBoost comme le classificateur principal du système d’imagerie et l’ont intégré à l’interface utilisateur graphique qui permet de prédire la couleur de la langue et les maladies correspondantes en temps réel.
Le système d’imagerie en temps réel utilisant XGBoost a donné des résultats positifs lors du déploiement avec une précision de diagnostic de 96,6 %.
Les chercheurs concluent :
“Ces résultats confirment la praticité des systèmes d’intelligence artificielle pour la détection de la langue dans les applications médicales, démontrant que cette méthode est sécurisée, efficace, conviviale, agréable et rentable”.
Ils notent toutefois que les réflexions de la caméra peuvent entraîner des différences dans les couleurs observées, affectant ainsi le diagnostic. Selon eux, les études futures devraient prendre en compte les réflexions de la caméra et utiliser de puissants processeurs d’image, des filtres et des approches d’apprentissage profond pour augmenter la précision. Cette méthode ouvre la voie à un diagnostic prolongé de la langue dans les futurs systèmes de santé au point de service.
Ali Raad Hassoon 1,2, Ali Al-Naji 1, Ghaidaa A. Khalid 1, Javaan Chahl 3
1 Electrical Engineering Technical College, Middle Technical University, Baghdad 10022, Irak
2 Al Hussein Teaching Hospital, Nasiriyah 64001, Irak
3 School of Engineering, University of South Australia, Mawson Lakes, SA 5095, Australie
Diagnostic des maladies par la couleur de la langue l’IA atteint une précision de 96,6 %
La Finlande a lancé sa stratégie en matière d’IA en 2017 pour stimuler la recherche et l’éducation dans le domaine. Avec ses 5,5 millions d’habitants, le pays des Mille Lacs vise à devenir un pays leader en matière d’IA. Il se place en deuxième position parmi les pays européens, comptant le plus grand nombre d’experts en IA par habitant (LinkedIn Economic Graph 2019). Focus donc sur la Finlande qui mise sur un niveau élevé de formation et de coopération active entre les acteurs afin de créer un environnement de recherche et d’innovation dynamique et attractif.
Une stratégie avant-gardiste
L’intérêt de la Finlande pour les nouvelles technologies ne date pas d’hier, bien au contraire. Nokia a été durant de nombreuses années l’image de marque du pays, sans compter le dynamique tissu académique et entrepreneurial.
Considérée comme avant-gardiste en matière de révolution numérique et d’innovation, notamment grâce à des initiatives et politiques ambitieuses autour du numérique, la Finlande a su mobiliser sa population, son administration et ses entreprises autour de la diffusion des technologies numériques, via l’accès aux données publiques ou l’attention particulière portée au système éducatif.
La transformation numérique et le développement des technologies d’IA ont permis la mise en place d’initiatives et de programmes comme AuroraAI, lancé par le ministère finlandais des Finances, et qui vise à aider les citoyens et les entreprises en leur proposant des services axés sur leurs besoins. Cet intérêt pour l’IA répond au potentiel économique important du domaine. Plusieurs études indiquaient en effet dès 2017 que l’IA pourrait permettre à la Finlande de doubler son taux de croissance économique d’ici 2035 (Accenture et Frontier Economics 2017).
Le pays serait en effet la deuxième économie mondiale ayant potentiellement le plus à gagner du développement de l’IA, derrière les États-Unis.
Pour que ces analyses deviennent réalité, le gouvernement finlandais a donc mis en place dès 2017 un plan d’action en trois volets :
un groupe d’experts, d’acteurs et de personnalités académiques, scientifiques et économiques, sous l’égide du ministère de l’Économie et de l’Emploi, chargé de proposer des recommandations pour le développement de l’IA en Finlande ;
un programme IA ;
une enveloppe de 200 millions d’euros sur la période 2018-2021, inscrite au budget de Business Finland.
Business Finland est l’organisation gouvernementale finlandaise pour le financement de l’innovation et la promotion du commerce, des voyages et des investissements. Cette agence publique est au cœur de la stratégie de développement finlandais. Cette organisation gouvernementale est chargée notamment du financement de l’innovation et des startups dans le domaine de l’IA. Le programme AI Business dirigé par Outi Keski-Äijö est l’une des initiatives lancées par le programme national d’intelligence artificielle de 2017. Prévu de 2018 à fin 2021, il a à ce jour aidé plus de 300 entreprises d’IA, ce qui représente environ 200 millions d’euros de financement. Ce programme vise à soutenir les startups et à augmenter l’attractivité du pays pour la recherche et le développement de l’IA.
La formation comme priorité
Quand on évoque la recherche en IA en Finlande, on ne peut ignorer Teuvo Kohonen, académicien, chercheur et professeur émérite à l’Académie de Finlande. Spécialiste des réseaux neuronaux artificiels, il a travaillé sur l’algorithme du Learning Vector Quantization basé sur la quantification vectorielle ou encore sur la théorie fondamentale sur la mémoire. Il a également présenté la carte autoadaptative dite « carte de Kohonen » dans les années 1980, qui a marqué l’histoire de la recherche sur les réseaux de neurones et la reconnaissance de formes en Finlande.
Ces dernières années, plus de 6300 étudiants suivaient au moins un cours d’IA dans le cadre de leur formation. Les grandes universités finlandaises proposent près de 250 cours individuels d’IA et plus de 40 formations de niveau master, 19 programmes de niveau licence et 3 programmes de doctorat. Il faut ajouter à celles-ci les 26 formations dispensées par les grandes écoles spécialisées et le Centre de recherche technique VTT de Finlande.
À l’heure actuelle, plusieurs universités finlandaises proposent un enseignement de haut niveau sur l’IA. Elles misent notamment sur des opportunités d’apprentissage accessibles et sur l’attrait des citoyens pour le numérique, grâce notamment à des cours publics gratuits en ligne comme Elements of AI.
Sensibiliser la population aux enjeux de l’intelligence artificielle est l’objectif de la Finlande pour développer la recherche et le développement d’activités et de solutions sur un secteur économique en plein essor et au potentiel élevé.
C’est un sujet sur lequel l’Académie de Finlande s’est positionnée via son programme ICT 2023 pour la R&D et l’innovation et pour renforcer les connaissances et les applications en machine learning, internet industriel, technologies et services de santé innovants centrés sur l’utilisateur. Des centres de recherches comme l’Institut d’informatique d’Helsinki (HIIT), se sont rapidement développés pour accueillir les chercheurs et les entreprises.
Elements of AI
Lancée début 2018 par l’université d’Helsinki, Elements of AI est une série de MOOCs conçue en collaboration avec la société Reaktor. Elle a été classée no 1 mondial par le portail de cours en ligne Class Central et Forbes et a remporté le grand prix Inclusive Innovation Challenge du MIT. Les cours peuvent être suivis au rythme de chacun et combinent théorie et exercices pratiques.
Le premier volet, Introduction to AI, permet de se familiariser avec le machine learning, les réseaux de neurones, la résolution de problèmes grâce à l’IA ou encore la philosophie de l’IA. Plus de 1 % de la population finlandaise a été formée aux bases de l’IA grâce à ce cours en ligne gratuit. À l’occasion de la présidence finlandaise du Conseil de l’Union européenne en 2019, le MOOC a été traduit dans de nombreuses langues pour permettre aux citoyens européens de se former eux aussi aux bases de l’IA. Pour sa version française, le partenaire de cette initiative a été Sorbonne-Université.
L’an dernier, Elements of AI a partagé son nouveau MOOC, Building AI, qui permet de découvrir les algorithmes servant à créer des méthodes d’IA. Certaines compétences de base en programmation Python sont recommandées pour tirer le meilleur parti du cours. Depuis son lancement, Elements of AI a formé près de 620 000 personnes, et diplômé des étudiants de plus de 170 pays. À noter que 40 % des participants aux cours sont des femmes, soit plus du double de la moyenne des cours d’informatique.
Le MOOC Ethics of AI lancé par l’université d’Helsinki fin 2020 s’intéresse quant à lui à l’éthique de l’intelligence artificielle et propose des textes, des exercices et un grand nombre de cas réels illustrant différents points de vue éthiques.
Faciliter l’accès aux supercalculateurs
Le CSC (IT Center for Science), basé à Kajaani, se présente comme l’un des plus grands acteurs mondiaux dans le domaine du calcul haute performance. Cette entreprise publique à but non lucratif abrite le système national de calcul et de gestion des données de la Finlande et a été choisie pour accueillir l’un des trois supercalculateurs pré-exascale de l’initiative EuroHPC.
Un projet de 200 millions d’euros financé à 50 % par la Commission européenne et à 50 % par les dix pays participants. Le supercalculateur LUMI, installé en 2021, disposera d’une puissance de calcul crête de 552 petaflops, soit 552 millions de milliards d’opérations en virgule flottante par seconde.
Le CSC, qui fournit déjà aux startups finlandaises des ressources informatiques gratuites pour leurs projets de recherche grâce à la subvention informatique de Business Finland, réservera 20 % de la capacité de calcul de LUMI aux industriels et PME-PMI.
Le Centre finlandais pour l’intelligence artificielle (FCAI)
Le FCAI est l’un des programmes phare de l’Académie de Finlande. Il rassemble des experts académiques, industriels et venant du secteur public, travaillant notamment sur l’Agile probabilistic AI, la Simulator-based inference, le Next-generation data-efficient deep learning, la Privacy-preserving and secure AI, l’IA interactive, l’IA autonome et l’IA dans la société.
Le centre dispose d’un budget de 250 millions d’euros pour 2019-2026, il est devenu l’un des pôles d’innovation numérique de la Commission européenne (AI DIH) formé par une communauté d’experts de l’université Aalto, de l’université d’Helsinki et de VTT.
Le FCAI, le Tampere AI Hub et l’Académie AI de l’université de Turku, entre autres, ainsi que des initiatives régionales et d’autres accélérateurs ont également pour objectif de transférer efficacement les compétences aux startups et entreprises afin de stimuler la commercialisation de l’IA et accélérer son déploie-ment.
Un écosystème entrepreneurial innovant et dynamique
La Finlande compte plus de 300 startups IA dans différents domaines commerciaux. Les liens avec la recherche acadé-mique, les organismes de recherche et les acteurs publics sont particulièrement renforcés pour que les jeunes pousses puissent accéder à toutes les clés pour s’inscrire dans les marchés et créer de nouveaux secteurs porteurs. La région d’Helsinki a notamment été reconnue comme l’un des plus importants écosystèmes de démarrage d’IA en Europe.
Les entreprises peuvent compter sur de larges bases de données mises à disposition des entreprises afin de susciter une plus grande et plus rapide adoption de l’IA dans le pays.
Les startups finlandaises essaient de capitaliser sur les traditions de recherche, en reconnaissance des formes, en TAL ou en vision industrielle par exemple, et sur les coopérations entre secteurs. La société de radiodiffusion nationale finlandaise (YLE) a lancé l’an dernier une campagne de collecte du finnois parlé dans tout le pays afin que les algorithmes puissent apprendre à comprendre et à reconnaître les spécificités langagières.
En matière de collaboration, les exemples ne manquent pas. La société Bilot a développé un modèle pour YIT, la plus grande entreprise de construction de Finlande, afin d’optimiser les procédures de maintenance sur les routes et les rues grâce au machine learning. Top Data Science a développé une solution d’analyse vidéo pour aider les sites japonais à gérer la distanciation sociale en cette période de pandémie.
De son côté, en collaboration avec la Banque mondiale, Headai a réalisé une analyse du marché du travail et une évaluation des lacunes dans les curriculum vitæ à l’aide de mégadonnées analysées par IA en Afrique, ce qui a permis de trouver des points d’action importants pour faire évoluer les formations universitaires et gagner en pertinence dans la vie professionnelle.
La startup Solita s’est appuyée sur son expertise en orthopédie et en IA pour développer avec Coxa Hospital for Joint Replacement le premier logiciel médical CE évaluant les risques d’une chirurgie articulaire pour un patient spécifique. Parallèlement, Silo AI a collaboré d’une part avec Philips pour le développement d’une solution de vision par ordinateur pour l’analyse des images IRM et d’autre part avec IDS, filiale d’Allianz, pour améliorer les flux de travail financiers, la prévisibilité et l’évaluation des risques.
Dans un secteur totalement différent, la startup Fourkind a créé en coopération avec la distillerie de whisky suédoise Mackmyra le premier whisky au monde entièrement développé par apprentissage automatique.
Focus sur deux start-ups
Awake.AI
La startup Awake.AI, créée en octobre 2018 et co-fondée par Karno Tenovuo, propose des solutions et des plateformes de données collaboratives et ouvertes pour faciliter la création d’écosystèmes pour les ports intelligents et l’évolution de la navigation autonome, augmenter l’efficacité opérationnelle et créer de nouveaux services numériques pour tous les acteurs de l’écosystème portuaire.
Partant du constat que plus de 90 % des exportations finlandaises transitent par les ports, Awake.AI s’est développée pour proposer le port intelligent et la plateforme d’expédition autonome les plus fiables au monde et un orchestrateur d’écosystème mondial d’ici 2025.
Silo AI
Silo AI, présenté comme étant le plus grand laboratoire privé de solutions d’IA des pays nordiques, s’est spécialisé dans la création d’une IA centrée sur l’humain en tant que service et cherchant à accélérer la coopération homme-machine pour l’intelligence collective.
L’origine de Silo AI remonte à la crise financière mondiale de 2009 lorsque Peter Sarlin (P.-D.G.) et son groupe de recherche ont conçu une solution d’IA permettant de préserver la stabilité financière de la Banque centrale européenne. En 2017, Tero Ojanperä, Ville Hulkko, Kaj-Mikael Björk, Juha Hulkko et Johan Kronberg se sont unis à Peter Sarlin pour former Silo AI.
Avec ses quelque 90 experts en IA, 50 doctorants et 100 projets en IA, le laboratoire a déployé ses solutions en Finlande et se développe à l’international en proposant une expertise et des outils de pointe, en particulier de vision par ordinateur, de traitement du langage naturel et d’apprentissage automatique.
Avec son projet Growth Engine, l’entreprise cherche à développer un écosystème rassemblant des experts en IA et des partenaires technologiques pour générer de nouvelles opportunités commerciales et mettre en avant l’expertise finlandaise, notamment sur les marchés internationaux.
Trois questions à Outi Keski-Äijö
Responsable du programme AI Business au sein de Business Finland
Quels secteurs de l’économie finlandaise pourraient bénéficier le plus des technologies basées sur l’IA ?
Notre stratégie étant d’être un leader mondial dans l’application de l’IA, nous visons une large adoption de l’IA à la fois dans les secteurs privé et public. Bien entendu, nos secteurs d’exportation sont les plus importants : les TIC, les machines intelligentes, les technologies propres (cleantech), les technologies de la santé et le transport maritime.
Les TIC et les technologies de la santé sont actuellement les domaines les plus avancés car plus de données sont disponibles. De nouveaux secteurs tels que celui des véhicules autonomes font également leur apparition.
La coopération entre le monde académique et l’entreprise semble particulièrement forte en Finlande, comme se traduit-elle concrètement ?
Nous avons une longue tradition de coopération étroite entre les universitaires et les entreprises en Finlande. Nous promouvons également cette coopération par le biais de nos instruments de financement de Business Finland. En outre, nous avons encouragé les universités à créer des centres d’IA afin de transférer efficacement les connaissances et les résultats de la recherche sur l’IA aux entreprises. Ces centres proposent aux entreprises des formations, des ateliers et des conseils en IA. De plus, de nombreux chercheurs en IA se lancent dans les affaires, en particulier en fondant de nouvelles startups.
Quelle est la dernière entreprise ou projet finlandais d’IA qui vous a personnellement étonné ?
J’en citerai deux : le résultat significatif d’un projet de recherche de la FCAI et une entreprise finlandaise de technologie de la santé qui a réussi à combiner l’IA avec d’autres résultats de recherche. Twinify est l’une des réussites de la FCAI. Les chercheurs ont développé une méthode basée sur l’apprentissage automatique qui crée un jumeau de données synthétiques d’un ensemble de données d’origine en conservant toutes les propriétés statistiques de l’ensemble de données d’origine. Cela permet le partage de données sans compromettre la confidentialité. Ceci est particulièrement important dans la recherche en santé, et il peut être appliqué à tous les secteurs.
Deep Sensing Algorithms est une société finlandaise qui a développé grâce à l’IA un dispositif de poche d’analyse de l’haleine pour participer à la lutte contre le Covid-19. Destiné à sa détection par les professionnels de santé et en particulier aux dépistages rapides pour de grandes foules, il est capable de tester une personne toutes les deux minutes.
Focus pays Finlande le pari de l’éducation et de la coopération
Frédéric Bardolle, à la tête de l’incubateur numérique du ministère des Armées, considère que « la qualité des intervenants est incroyable, et les sujets évoqués sont très variés et toujours passionnants. »
Mehdi Benhabri, haut fonctionnaire spécialiste des questions scientifiques et technologiques, résume sa participation en ces termes : « Le Paris Machine Learning est rapidement devenu l’un des plus grands rassemblements de France sur les thématiques de l’intelligence artificielle en général et du machine learning en particulier. Le dynamisme de ses animateurs a permis de mobiliser des compétences de haut niveau dans un cadre original et peu formel afin d’échanger de manière libre et approfondie, sans les rigidités et les contraintes du monde académique. »
Dans le cadre des jeux olympiques 2024, nous vous offrons chaque jour un article issu du magazine ActuIA n°4, dont le dossier principal est “Le sport à l’ère de l’IA”. Afin de découvrir le magazine ActuIA, nous vous invitons à vous rendre sur notre boutique. Tout nouvel abonnement d’un an vous donne droit à l’ensemble des archives au format numérique.
Une identité et une charte
Au cours des réunions suivantes, nous peaufinons les valeurs de notre groupe et esquissons notre charte. À savoir une structure plate, sans cooptation. Son but est de donner aux membres le point de vue des chercheurs les plus prometteurs du domaine, d’éviter les discours de vendeurs de solutions techniques, de couper les pitchs et les présentations éclair à la mode dans les startups numériques. Mais également de filtrer et de rejeter sans ambiguïté les tentatives d’exploitation douteuses des algorithmes, parmi lesquelles : les algorithmes de détection d’orientation sexuelle, la recherche des traits du visage caractéristiques des criminels, ou encore la façon de dessiner un visage à partir de la voix.
L’Eurovision du machine learning chez Google
Un an plus tard, forts de nos mille premiers membres, Google nous ouvre les portes de son immense salle de conférence parisienne et met toute son infrastructure à disposition pour une soirée. Le défi ? Retransmettre les interventions des spécialistes IA en direct à Paris, Londres, Berlin et Zurich.
Le point d’orgue de la soirée est Andrew Ng, cofondateur de Google Brain, professeur à Stanford et star mondial de l’IA. Son credo ? « L’IA est une nouvelle électricité. Elle s’immisce dans tous les objets comme l’électricité l’a fait au début du siècle. »
Après cette première saison, le ton est donné. S’enchaînent au fil des sept saisons différents formats et déclinaisons, présentations à distance avec des chercheurs à l’autre bout du monde, hackathons, concours de code et hors-série thématiques : data journalism par le responsable data du New York Times, attaques adverses, finance algorithmique, automatic machine learning, robotique et IA, calcul haute performance.
Andrew Ng, professeur à Stanford, cofondateur de Google Brain (division de recherche fondamentale IA de Google) a très largement contribué à populariser les méthodes et les techniques de l’intelligence artificielle, particulièrement à travers son célèbre cours en ligne Coursera, passage obligé pour tous les codeurs d’IA.
Partage d’expertise
Cas d’usage d’entreprises et algorithmes data
En France et dans le monde, des communautés d’experts data et IA se constituent. Toulouse, Marseille, Nantes. Amsterdam, Stockholm, New York, Boston, San Francisco. Aucune ville n’est en reste. Pour quelle raison ? Parce que l’accélération prodigieuse du rythme d’apparition de technologies déstabilisantes provoque un besoin de formation et une soif de compréhension immédiate, peu en adéquation avec le rythme des formations longues.
En effet, ce que désirent les ingénieurs, les programmeurs et les entrepreneurs est de comprendre immédiatement ce qui est en train de se jouer et qui chamboule l’économie. Comment appliquer les algorithmes à leur métier ?
Quant à l’offre d’expertise, elle est tout aussi abondante.
Facteur H, l’humain dans la boucle
Au-delà d’une soif de connaissances techniques, le plaisir des rencontres informelles et du réseautage est un élément important. Gautier Marti, un Français spécialiste des algorithmes machine learning travaillant à Abou Dabi pour un fonds souverain nous confiait que « les rencontres du Paris Machine Learning sont une source de veille technologique. Elles permettent de découvrir de nouveaux outils et de confronter ses idées à la réalité ou à l’expérience d’autres experts. »
Lors de ces rencontres, des fondateurs d’entreprise se sont rencontrés et ont créé leur entreprise. Nicolas Gaude, cofondateur de la startup Prevision.io, fait part de son expérience en ces termes : « Ce fut pour moi un vrai déclic. Avec l’aide de Franck Bardol, d’Igor Carron et les conseils des experts présents, j’ai pu vraiment progresser techniquement et donner corps à mon projet. »
Jacques-Henri Gagnon, directeur adjoint des services culturels et chef des relations universitaires à l’ambassade du Canada à Paris, ajoute : « Le Paris Machine Learning m’a donné accès à ce large réseau et a aussi été le point de départ d’échanges franco-canadiens ce qui, dans mon sec-teur d’activité, est le cœur de métier. » Le groupe a fait office de facilitateur pour nombre de ses membres, des ingénieurs y ont été recrutés, des sociétés ont initié des partenariats et des rachats.
Pour conclure, cette phrase de Théodore Levitt, le père fondateur du marketing s’adressant à ses étudiants, résume bien l’esprit de cette communauté : « Le client ne veut pas une mèche de perceuse. Il veut un trou dans le mur. »
Jürgen Schmidhuber, découvreur des LSTM au début des années 2000, a rendu cet apprentissage possible grâce à des données temporelles, ordonnées et horodatées. Ses réseaux récurrents temporels LSTM analysent désormais les données de capteurs des chaînes de production d’usines et permettent de prédire les valeurs futures. On lui doit le traitement efficace des motifs temporels à l’aide de réseaux de neurones spécialisés. Il était revenu sur la genèse de sa découverte dans une réunion et avait partagé les voies d’amélioration de ses méthodes. L’avenir lui a donné raison. Depuis lors, les architectures transformers ont révolutionné la traduction automatique et tout le traitement du langage par des algorithmes.
Gaël Varoquaux, Alexandre Gramfort et Olivier Grisel : ce trio d’ingénieurs et scientifiques français est la tête pensante de la librairie machine learning la plus utilisée au monde, dont les statistiques sont impressionnantes.
C’est la seconde librairie la plus téléchargée au monde derrière la célèbre TensorFlow de Google, avec 700 000 utilisateurs et 42 millions de visites sur le site internet. Son nom ? Scikit-learn. Tous les codeurs du machine learning ne jurent que par elle. Son mérite est de mettre à disposition de n’importe quel programmeur des millions de lignes de code optimisées, pensées et calibrées par les plus grands spécialistes de l’ingénierie. Son prix ? Inestimable. Elle est gratuite et en open source. Elle représente la plus grande réussite de démocratisation du machine learning.
De nombreuses années en arrière, ces trois chercheurs étaient venus initier les membres du Paris Machine Learning au fonctionnement de leur outil Scikit-learn dès la première réunion.
Alexandre Gramfort nous confiait que « cela a été pour moi une belle opportunité de présenter ma recherche. » Depuis, Alexandre, Gaël et Olivier ont été récompensés par le prix Inria – Académie des sciences.
François Chollet, malgré son jeune âge, est une star de l’IA. Et pour cause, ce Français, chercheur chez Google Brain, a écrit la librairie de deep learning nommée Keras. L’avantage de cette librairie est de simplifier et masquer la complexité du deep learning. Le même esprit que Scikit-learn en somme. La reconnaissance ne s’est pas fait attendre. Désormais, Keras est livrée par Google en même temps que les autres programmes deep learning de cette société. Nous l’avions reçu dans une réunion hors-série qui lui était consacrée. François Chollet est également l’auteur d’un ouvrage de référence sur le deep learning. Jacqueline Forien a traduit cet ouvrage en français¹ et poursuit ainsi la démocratisation des algorithmes IA.
Yoshua Bengio, un des co-découvreurs du deep learning, avait évoqué dans une réunion les difficultés d’apprentissage ainsi que les solutions envisagées.
À cette période, le deep learning était encore balbutiant. Ce n’est désormais plus le cas et nous le devons en grande partie à ses travaux.
Les algorithmes de ces découvreurs fonctionnent au quotidien et inspirent les logiciels IA d’entreprises. Leur passage par le Paris Machine Learning a été une source profonde d’inspiration.
Les algorithmes d’apprentissage ont révolutionné des pans entiers de l’ingénierie et rendu possible ce qui tenait jusqu’alors du domaine du rêve des ingénieurs.
La robotique dans tous ses états
La robotique figure en bonne position dans ce chamboulement. Pierre Sermanet, jeune chercheur français dans le groupe robotique de Google² y avait consacré plusieurs conférences. « Mes recherches explorent l’intersection du langage³ et du jeu et mobilisent de multiples mécanismes pour l’apprentissage robotique ». Interrogé sur l’avenir de sa discipline, il répond : « Les avancées récentes autour de l’apprentissage sur des données massives de langage non labellisées (notamment les modèles GPT d’OpenAI) sont impressionnantes et prometteuses, le même type d’approche appliquée à la vidéo et à la robotique me paraît très prometteur ».
Le coup de force du deep learning
S’il est un domaine qui a connu une véritable révolution, c’est bien l’analyse d’images.
Impossible de ne pas évoquer l’apport du machine learning dans l’analyse et la compréhension des images. Le point de bascule a lieu au moment de la fondation du Paris Machine Learning. Grâce à sa nouvelle méthode de réseaux de convolution, Geoffrey Hinton réalise un tour de force dans la compétition ImageNet. Il écrase les méthodes traditionnelles d’analyse d’images et y impose les techniques de deep learning comme nouveau standard.
Dominique Cardon, directeur du Médialab de Sciences Po et auteur d’un des ouvrages de référence⁴ sur le sujet, était venu nous en faire un récit épique au cours de la centième réunion du groupe tenue dans les locaux inspirants de la startup Scaleway. Voici quelques morceaux choisis de son récit publié depuis dans un article intitulé La revanche des neurones⁵.
« L’épisode est en passe de devenir légendaire dans l’histoire de l’informatique ». Un chercheur interrogé par Dominique Cardon se souvient : « En 2012, Hinton débarque dans la compétition ImageNet et crée un véritable séisme !
Il ne connaît rien au domaine de la vision par ordinateur et il embauche deux petits gars pour tout faire sauter !
À l’époque, les ingénieurs de computer vision s’excitent sur ImageNet depuis deux ou trois ans. Le meilleur d’entre eux était à 27 % d’erreurs. Hinton, lui, marque dix points à tout le monde ! Ce jeune geek arrive et annonce le résultat devant une salle bondée. Un ado qui ne comprend rien à ce domaine, enfermé dans ses algorithmes !
Tous les grands manitous du computer vision essaient de réagir : En fait c’est pas possible, ça va pas marcher… Au final, les mecs étaient tous abasourdis parce que grosso modo cela foutait en l’air dix ans d’intelligence, de tuning et de sophistication. »
Ce récit savoureux nous fait vivre de l’intérieur la révolution initiée par les algorithmes d’apprentissage. Les méthodes d’expertise manuelle fine sont balayées par la science “à la Google” qui allie big data et algorithmes IA.
Du laboratoire à la startup
Depuis, les ingénieurs et docteurs en IA ont transformé ces algorithmes encore balbutiants en produits finis redoutables d’efficacité. Des exemples ? LightOn, startup technologique cofondée par Igor Carron, révolutionne l’informatique grâce à sa puce optique. Le résultat ? Des calculs à la vitesse de la lumière et une empreinte énergétique minime grâce à sa technologie de rupture. Le meilleur des mondes en somme.
Meero, une autre pépite technologique, automatise la retouche photo grâce à ses algorithmes AI entraînés sur des millions de photographies. Jean-François Goudou, son directeur R&D nous avait décrit l’algorithme machine learning de restauration et d’amélioration automatique d’images lors d’une réunion au siège de Samsung. « Les premiers retours clients sont très très positifs. » nous confia-t-il.
Tony Pinville, fondateur, aux côtés de Charles Ollion, de Heuritech, une startup spécialiste de ces mêmes algorithmes IA d’analyse d’images, avait ouvert pour nous le capot de ses algorithmes. Il nous confie : « Le meetup Paris Machine Learning a été un mouvement précurseur de l’IA que Heuritech a eu la chance de rejoindre au tout début. », et ajoute : « Pour notre part, nous utilisons une technologie de reconnaissance visuelle qui analyse chaque jour plusieurs millions d’images de consommateurs et d’influenceurs sur les réseaux sociaux et les traduit en informations riches et pertinentes pour les marques de mode et de luxe.
Pour mieux créer leurs collections, ces marques ont besoin d’informations sur la prévision de tendances et de ventes. Heuritech souhaite combiner ces deux types de prédictions pour mieux les accompagner. » Depuis, la récompense est venue naturellement. Heuritech a reçu le prix LVMH de l’innovation des mains de Bernard Arnault.
Déplacement de l’expertise
Malgré ces succès et avancées spectaculaires, la fabrication des programmes de machine learning demeure artisanale et reste une affaire de spécialistes et d’experts. Les data scientists procèdent le plus souvent par tâtonnements et essais-erreurs lorsqu’ils élaborent un algorithme de machine learning.
C’est à ce déplacement de l’expertise auquel nous assistons depuis dix ans. Auparavant, le cœur de la création de valeur dans les entreprises était la production de règles métiers par les experts. Désormais, ces règles émergent des données grâce aux algorithmes auto-apprenants.
L’expertise des ingénieurs IA qui les conçoivent consiste à choisir l’algorithme le plus approprié pour un jeu de données particulier, puis à l’étalonner et à le dimensionner à la bonne puissance. Pour les entreprises qui mobilisent des technologies IA, la sélection d’algorithmes et d’architectures matérielles et logicielles s’est substituée à la conception des règles métiers traditionnelles.
Les programmes d’IA proposent une mécanisation de l’intuition et de la connaissance métier de l’expert humain. Nous en sommes au premier stade. Un courant de recherche visant à automatiser tout ou partie de la chaîne de fabrication des programmes d’IA s’est mis en place. Il s’agit du second stade, celui qui consiste à « automatiser l’automatisation ». En effet, en induisant la production automatique des règles par un programme d’ordinateur, le machine learning représente une automatisation de la pensée d’experts. Cette voie se nomme AutoML, pour Automatic Machine Learning.
L’AutoML, futur du machine learning ?
Le Paris Machine Learning a participé à l’organisation de concours et de hackathons AutoML. Ce fut le cas du concours RAMP du Paris-Saclay Center for Data dirigé par Balázs Kégl, intervenant lors d’une rencontre consacrée à l’apport du machine learning pour la physique théorique au laboratoire européen du Cern, la data au service des particules atomiques. Ou encore du concours ChaLearn organisé par Isabelle Guyon et du défi européen See.4C assorti d’un prix de deux millions d’euros pour les gagnants. Le laboratoire d’innovation ouverte La Paillasse hébergeait ces rencontres grâce au soutien énergique d’un de ces dirigeants, Sébastien Treguer.
Isabelle Guyon confie que le Paris Machine Learning « a facilité l’organisation de hackathons et la diffusion des challenges en machine learning. »
L’histoire ne s’arrête pas là. « La série de challenges AutoML a permis la création d’Auto-Sklearn⁶ ». En ce qui concerne le deep learning, « la série de challenges AutoDL a abouti à un self-service de deep learning automatisé. »
Pour nous, l’AutoML constitue un axe de développement majeur pour les années à venir. Tous les acteurs importants sont désormais entrés dans la course. Parmi les avancées récentes, citons les méthodes Neural Architecture Search (NAS), en particulier Neural Network Intelligence (NNI) de Microsoft, ou encore Evolved Transformer de Google.
Dans un futur proche, l’expertise technique du data scientist ne sera donc plus nécessaire pour construire des programmes auto-apprenants. Le programme de recherche intitulé Automatic statistician et conduit par Zoubin Ghahramani de l’université de Cambridge, en collaboration avec le MIT, illustre parfaitement cette vision. Ghahramani nous en avait partagé les méthodes et les enjeux.
À terme, seule sera nécessaire une équipe restreinte de data scientists chargés d’améliorer les procédés automatiques de découvertes de règles. Tous les autres redeviendront des programmeurs traditionnels. Ils fourniront des données d’entraînement et obtiendront en retour, sans aucune expertise en la matière, le meilleur programme IA imaginable.
Parmi ceux qui mettent au point ce type de service automatisé de haut niveau, Nicolas Gaude, précédemment cité, nous décrit son activité en ces termes : « Mon métier consiste avant tout à démocratiser l’usage de l’A en apportant aux entreprises à la fois les innovations techniques et la capacité de les mettre en production. Ce qui nous préoccupe, et de loin, est de rendre accessible et opérable le machine learning sur le long terme. »
Quand les algorithmes deviennent un sujet de société
Les algorithmes de machine learning interprètent le monde avec un filtre statistique afin de nous guider dans nos choix.
Ce faisant, ils agissent sur la société et en transforment les pratiques et les usages. Ainsi, lorsqu’un algorithme de GPS suggère aux automobilistes pressés un itinéraire secondaire moins encombré, il peut créer simultanément un problème d’aménagement du territoire, l’itinéraire secondaire n’étant pas dimensionné, par nature, à subir cette augmentation de trafic. De plus, les nuisances sonores et la pollution engendrées par ce dernier touchent les riverains. L’algorithme crée donc également un problème de santé publique.
Dominique Cardon résumait ces points en 2017 lors d’une conférence consacrée aux biais des algorithmes à l’institut Henri Poincaré. Selon lui, « les algorithmes deviennent un sujet de société. » Ajoutons qu’ils deviennent un sujet politique. Un exemple frappant ? Le Zimbabwe a vendu une base de données contenant les visages de ses citoyens à la Chine.
Son but ? Entraîner les algorithmes de reconnaissance faciale sur des visages noirs. En échange de cette masse de données, le Zimbabwe sera bientôt équipé de caméras à reconnaissance faciale dernier cri…
Lors de cette conférence, Cédric Villani proposait une réflexion sur l’apport des algorithmes prédictifs dans l’entreprise. Il notait avec pertinence que les algorithmes devaient au préalable être acceptés avant d’être utilisés. En effet, un algorithme sans accompagnement ne sert à rien, un travail doit être effectué en amont. Cédric Villani nous rapportait une expérience réussie au cours de laquelle des salariés valident les décisions du programme IA et gardent ainsi la main sur la machine. Dans le cas contraire ? Il n’est pas rare de voir les salariés entrer en lutte “souterraine” contre ces programmes en les nourrissant, par exemple, de fausses données.
En somme, c’est l’illustration du fossé qui sépare l’IA capacitante de l’IA substitutive. Pour l’une, il s’agit de remplacer le salarié, pour l’autre il s’agit de le renforcer.
Franck Bardol pour sa part prolongeait cette réflexion autour de l’IA de confiance et précisait les points-clés de transparence et de loyauté des algorithmes. Depuis, ces thèmes émergent dans l’actualité du secteur et sont devenus un sujet d’inquiétude.
Pour Pierre Saurel, professeur associé à la Sorbonne, intervenant dans cette conférence, le domaine de l’éducation est également concerné par cette transformation numérique. De plus, les biais algorithmiques y sont tout aussi présents. Il ajoute que « L’analyse de ces biais est un point particulièrement important. Elle permet d’accompagner les enseignants pour identifier, par exemple, des spécificités dans les documents qu’ils peuvent utiliser en classe. »
Dans les coulisses de la conférence NeurIPS
Les grandes conférences scientifiques internationales sont des opportunités d’échanges intenses pour la communauté, mais aussi de moments, qui comme des œuvres d’art, sont révélateurs de tendances fortes.
Le Paris Machine Learning s’est associé avec la conférence NeurIPS afin de mettre à l’honneur quelques-uns des chercheurs francophones sélectionnés pour cette grand-messe. La forme ? Un panel quotidien de cinq intervenants durant la semaine de conférence. Des présentations éclair dans des visioconférences de dix minutes. Du concentré d’état de l’art. Ce qui émerge de cette sélection de chercheurs ? Beaucoup d’efforts consacrés à l’amélioration des méthodes d’apprentissage mais aussi des tentatives d’explorer des pistes totalement inédites.
Les neurosciences et l’explicabilité des algorithmes figurent aussi en bonne place. En somme, une dense semaine de mathématiques et d’algorithmique de haut niveau par des chercheurs de l’INRIA, l’École normale, Telecom Paris, Criteo, Google Brain et Facebook. Mais aussi venant des startups technologiques les plus avancées en recherche, parmi lesquelles LightOn, Hugging Face et Prophesee.
Des groupes de data scientists de Strasbourg, Timisoara en Roumanie et du Cameroun participaient également à cette semaine de mise en valeur de la recherche francophone. Robert Maria, organisateur du groupe de Strasbourg et de Timisoara, ainsi qu’Alain Nkongweni, organisateur du groupe du Cameroun, ont rejoint Jacqueline Forien et Claude Falguière dans l’organisation. Jacqueline est par ailleurs Meetup Chair à NeurIPS.
L’IA en lutte contre la Covid-19
Dès les premiers signes de la pandémie de Covid-19, la recherche scientifique s’est mobilisée. Le machine learning fait partie de l’arsenal mis en œuvre. C’était pour nous une évidence qui s’est traduite par une série d’interventions exclusives sur ce thème durant l’année 2020.
La recherche d’un remède définitif contre la Covid-19 complète la politique sanitaire du Tester – Alerter – Protéger. Chacun de ces éléments est décliné à base de machine learning, depuis les applications de traçage aux tests en masse, en passant par le suivi personnalisé de centaines de milliers de patients, la prévision du nombre de cas, l’estimation de la dangerosité du virus (le fameux R0) ou encore l’équilibre confinement – détection des cas, sans oublier la conception de molécules médicamenteuses.
Ces différents aspects ont été évoqués par Lenka Zdeborová, professeur à l’EPFL, Maximilien Levesque, fondateur de la startup Aqemia, Alexandre Gramfort de l’INRIA, Dror Baron de l’université de North Carolina et Arthur Charpentier de l’UQAM.
Avant de conclure, rappelons des points fondamentaux. Un algorithme ne remplace pas une infirmière. Un robot désinfectant ne se substitue pas à un accueil des patients à l’hôpital. Une application de traçage ne protège de rien. Aucune technique, méthode ou algorithme ne peut se substituer à l’action politique. Franck Bardol avait insisté sur ce point dans une intervention lors de la sortie de l’application de traçage nommée Stop Covid. Tous les éléments pour un fiasco étaient réunis. On connaît la suite. L’IA n’est pas de la magie qui résout tout. Aucune personne sérieuse n’y croit plus. Evgeny Morozov et son ouvrage de référence sur le techno-solutionnisme est passé par là et a balayé ce mythe.
Quel message retenir du Paris Machine Learning ?
Pour conclure, prêtons-nous à un exercice de synthèse difficile. Tentons de prendre du recul sur plusieurs centaines d’heures de prises de parole.
En premier lieu, ce qui frappe est la vitesse d’adoption des algorithmes IA. Yann LeCun, précurseur du domaine, relevait ce point dans sa leçon inaugurale du Collège de France consacrée aux algorithmes IA. Les ingénieurs ont adopté les méthodes du deep learning à une vitesse stupéfiante. Le décalage du cycle innovation-production n’existe pour ainsi dire plus !
Les avancées spectaculaires du deep learning en ce qui concerne le traitement des images et du langage ont très fortement facilité l’adoption du machine learning dans le tissu économique et dans les entreprises.
Au-delà de l’efficacité pure des algorithmes, d’autres préoccupations émergent. Notamment pour tout ce qui concerne le fonctionnement de ces algorithmes. Quelles sont les ressources nécessaires en données, en énergie, en matériel informatique pour entraîner ces algorithmes ? Hormis ces questions liées à la parcimonie des algorithmes, les mathématiciens s’interrogent toujours : « Pourquoi ces algorithmes fonctionnent-ils aussi bien ? » La recette est désormais connue de tous et a fait ses preuves mais la question de pourquoi elle fonctionne si bien reste entière.
Parallèlement à ces enjeux de recherche pure, le grand public, les ingénieurs, les décideurs politiques s’inquiètent du retentissement considérable de ces algorithmes sur nos sociétés. Les data scientists qui en écrivent le code informatique ne peuvent désormais plus se contenter d’être de purs techniciens, pour reprendre les termes de Cathy O’Neil, célèbre mathématicienne data scientist. Les algorithmes sont devenus un objet politique, l’éthique n’est plus une option mais un devoir.
Cet article est extrait du magazine ActuIA. Afin de ne rien manquer de l’actualité de l’intelligence artificielle, procurez vous ActuIA n°16, actuellement en kiosque et sur abonnement :
Docteur en informatique à l’UPMC (Sorbonne Université) et habilitée à diriger les recherches, le parcours professionnel de Marie-Aude Aufaure est jalonné d’expériences multiples en entreprise, dans le secteur académique et en entrepreneuriat. Elle commence sa carrière dans le secteur des télécommunications, puis rejoint l’enseignement supérieur et la recherche dans différents établissements, dont CentraleSupelec, où elle est titulaire d’une chaire sur la Business Intelligence, et l’INRIA.
Passionnée de technologies, elle se lance dans l’entrepreneuriat et fonde Datarvest en 2016, jeune entreprise innovante spécialisée dans l’exploitation et la valorisation des données – big data et intelligence artificielle. Ses domaines d’intervention couvrent le développement d’algorithmes innovants, le conseil aux entreprises et la formation. Elle a conçu et piloté la formation certifiante « Big data pour l’entreprise numérique » pour CentraleSupe-lec Exed.
Poursuivant sa volonté d’entreprendre, elle cofonde en 2019 SyncData Partners, cabinet de conseil en stratégie et innovation data. Elle est membre actif du Hub France IA et du think tank « la villa numéris ».
Dans le cadre des jeux olympiques 2024, nous vous offrons chaque jour un article issu du magazine ActuIA n°4, dont le dossier principal est “Le sport à l’ère de l’IA”. Afin de découvrir le magazine ActuIA, nous vous invitons à vous rendre sur notre boutique. Tout nouvel abonnement d’un an vous donne droit à l’ensemble des archives au format numérique.
Vous êtes spécialisée dans les graphes, quel est l’éventail de leurs usages possibles, et identifiez-vous des usages émergents ?
Durant la dernière décennie passée dans des laboratoires de recherche, je me suis intéressée à la construction automatique d’ontologies et à la modélisation et l’analyse de graphes complexes, convaincue du potentiel de ces technologies pour les entreprises. Datarvest (Data Harvesting) a été créée dans l’idée de croiser et d’analyser des masses de données hétérogènes et de proposer une solution d’analyse de données complexes intégrant un algorithme de clustering agnostique des données. Celui-ci permettrait d’extraire des classes en une seule passe à partir de tout type de données, numériques, catégorielles, sous forme de graphes ou de séries temporelles, définies par des intervalles de valeurs, etc.
Les graphes permettent de représenter les liens entre différentes entités, et les applications potentielles sont nombreuses. Citons les usages suivants, qui ne sont pas exhaustifs :
la détection de comportements anormaux appliqués à la détection de fraudes, la lutte anti-blanchiment, la cybersécurité ou encore le renseignement ;
l’analyse de graphes pour les ressources humaines pour identifier des talents, constituer des équipes cohésives ou encore prédire des évolutions de parcours de carrière et recommander des formations ;
la santé et la sécurité, en étudiant par exemple les interactions sociales dans le contexte de la crise sanitaire ;
la mobilité pour de l’aide à la décision ;
la supply chain pour propager des informations et alertes à l’ensemble de la chaîne de production.
Parmi les usages émergents, outre ceux présentés ci-dessus, les graphes peuvent être utiles pour gérer la gouvernance des données, une problématique majeure actuellement dans les entreprises : le data lineage peut être modélisé à l’aide d’un graphe permettant de tracer les données et de propager des modifications, les graphes de connaissances peuvent être utilisés pour représenter le modèle de données de l’entreprise et il est possible de prédire des liens. L’analyse de l’usage et des interactions clients se prête également très bien à ce type de représentation.
Vous venez de renforcer votre pôle R&D. Quels sont vos objectifs ?
La vocation de Datarvest est de développer des technologies de pointe intégrant les résultats récents issus du monde de la recherche, en concevant et mettant en œuvre des méthodes et algorithmes innovants en collaboration avec le monde académique.
Les travaux de R&D initiés depuis la création de l’entreprise ont donné des résultats prometteurs, applicables à de nombreux usages, et il était naturel de renforcer notre R&D. Un jeune docteur spécialisé dans les graphes, Mehdi Djellabi, a été recruté en mars dernier. Ses travaux ont porté sur des mesures d’interactions locales dans des graphes complexes, et une extension de ces travaux, prenant en compte des éléments de contenu comme des pondérations de relations, peut compléter la solution de Datarvest.
Par ailleurs, notre solution peut harmonieusement être combinée avec des algorithmes de machine learning ou de deep learning existants, pour faire de la prédiction de liens ou de nœuds, ou de manière plus classique en intégrant les résultats analytiques comme données d’apprentissage. Le renforcement du pôle R&D permet d’ouvrir un champ des usages potentiels conséquent et de rester à l’état de l’art.
Cet article est extrait du magazine ActuIA. Afin de ne rien manquer de l’actualité de l’intelligence artificielle, procurez vous ActuIA n°16, actuellement en kiosque et sur abonnement :
À l’instar de l’Intelligence humaine qui revêt plusieurs aspects et différentes formes, l’Intelligence Artificielle a expérimenté de nombreuses approches pour la simuler. Ainsi, du perceptron au dernier algorithme de Google (Switch-C) en passant par les systèmes experts et la programmation par contraintes, l’imagination des chercheurs a exploité, au fil du temps, toute la puissance des outils et les combinaisons les plus complexes pour approcher au mieux la perception et le raisonnement des humains. Cependant, schématiquement, toutes ces technologies peuvent se classer en deux grandes catégories : L’Intelligence Artificielle Numérique et l’Intelligence Artificielle Symbolique. ActuIA vous propose de découvrir ce que recouvrent ces deux approches et, parce que le monde est complexe et non binaire, suggère une perspective de rapprochement entre elles pour une IA encore plus efficace, plus compréhensible et plus conforme à son modèle humain.
Dans le cadre des jeux olympiques 2024, nous vous offrons chaque jour un article issu du magazine ActuIA n°4, dont le dossier principal est “Le sport à l’ère de l’IA”. Afin de découvrir le magazine ActuIA, nous vous invitons à vous rendre sur notre boutique. Tout nouvel abonnement d’un an vous donne droit à l’ensemble des archives au format numérique.
L’Intelligence Artificielle numérique : Apprendre des données du monde
Article rédigé par Françoise Soulié, conseiller scientifique du Hub France IA
L’Intelligence Artificielle numérique, dont les méthodes connexionnistes font partie, ne s’appelait pas du tout IA à l’origine ! Cette appellation était réservée à l’IA symbolique. Comment s’est-elle retrouvée affublée de ce nom d’« IA » ?
L’IA connexionniste a pour source l’idée que l’intelligence de la machine devrait s’inspirer de l’intelligence humaine. C’est d’abord la cybernétique : Wiener trouve l’inspiration des machines dans le système nerveux, il est rejoint au MIT par Pitts, qui travaille avec McCulloch pour réaliser une machine de Turing avec un réseau de neurones. Leur article¹ contient le modèle du neurone artificiel encore utilisé aujourd’hui dans les réseaux de neurones artificiels et autres modèles de deep learning. Puis Rosenblatt propose le perceptron², un réseau de neurones capable d’apprentissage et qui bénéficie d’une énorme publicité. Mais l’ouvrage de Minsky et Papert³ montre bientôt les limitations du perceptron qui ne peut pas résoudre des problèmes (complexes ?) comme la connectivité des spirales imbriquées de la couverture des ré-éditions de 1987 et 2017 du livre. Mais comme, de plus, aucune application industrielle du perceptron n’émerge, les financements se tarissent et le premier hiver des méthodes connexionnistes s’installe.
Premier rebond
À partir du début des années 1980, le travail sur les réseaux connexionnistes repart. Les chercheurs du domaine se retrouvent lors de la conférence NIPS (créée en 1987, devenue NeurIPS en 2018⁴) avec son prequel à Snowbird, des conférences d’INNS et ENNS (International / European Neural Network Societies) et aussi de plusieurs conférences OTAN en France. De nombreuses équipes, partout dans le monde, avancent en parallèle.
Aux États-Unis, David Rumelhart (Parallel Distributed Processing group à San Diego) publie l’article fondateur sur la rétro-propagation⁵ que Yann Le Cun avait également développé dans sa thèse en France en 1987⁶. Larry Jackel crée une équipe aux Bell labs avec Le Cun, Bengio, Bottou, Vapnik. Ils exploitent l’algorithme de rétro-propagation du gradient et commencent à travailler sur les réseaux multi-couches convolutionnels (Time
Delay Neural Networks, à l’époque). Ils proposent en 1989⁷ un réseau à trois couches cachées de filtres convolutionnels pour la reconnaissance de caractères. Geoffrey Hinton, à Carnegie Mellon, puis à l’université de Toronto, est sans doute l’un des plus prolifiques contributeurs à l’IA connexionniste : il a travaillé sur les réseaux de neurones, les machines de Boltzmann, les réseaux deep belief, les réseaux convolutionnels… Yoshua Bengio, à l’université de Montréal, se spécialise dans les réseaux convolutionnels, les graph transformer networks⁸ (le modèle de lecture automatique des codes postaux décrit sera déployé à l’U.S. Postal Service et traitera environ 10 % des chèques aux États-Unis au début des années 2000). D’autres équipes en France ont travaillé sur ces sujets. L’équipe de Françoise Soulié-Fogelman et Patrick Gallinari (d’où sont issus Le Cun et Bottou), a travaillé sur des modèles de réseaux convolutionnels (avec 3 à 5 couches de filtres convolutionnels) pour la reconnaissance de la parole (Bottou⁹) ou de visages (Viennet¹⁰) par exemple.
Ces nouvelles techniques sont testées sur les premières applications (lecture de chèques, compréhension de la parole, identification de visages…) et les résultats sont comparables ou supérieurs aux meilleures techniques conventionnelles de l’époque : les limites du perceptron sont complètement dépassées grâce à l’introduction des couches cachées des réseaux multi-couches. Mais des limites apparaissent rapidement : les ensembles de données sont de tailles très limitées et difficiles à assembler, par ailleurs les temps de calcul sur les machines existantes explosent ; l’industrialisation ne démarre pas. Et, à partir de 1995, sans soutien de l’industrie, c’est le deuxième hiver des méthodes connexionnistes.
2012, le tournant
Dans les quinze années qui suivent, l’IA Numérique va se développer fortement, avec des applications nombreuses dans l’industrie (banque, télécommunications, distribution notamment) et une ouverture de la statistique classique à ces méthodes.
Progressivement, cette branche de l’IA est alors considérée comme équivalente au terme Machine Learning. Les manuels de Vapnik¹¹ , Friedman, Hastie, Tibshirani¹² posent les bases théoriques du Machine Learning et dans un article¹³ retentissant de 2001, Leo Breiman, l’inventeur des arbres de décision, des forêts aléatoires et des techniques de bagging, incite les statisticiens à s’intéresser au Machine Learning. D’autres techniques sont développées : logique floue, algorithmes génétiques… Au Canada, le Cifar (Canadian Institute For Advanced Research) finance un programme « Calcul neuronal et perception adaptative » qui permet au trio Le Cun (NYU), Hinton (Toronto) et Bengio (Montréal) de maintenir l’activité sur les réseaux de neurones. Cependant, durant ces quinze ans, trois événements vont complètement changer la donne : d’abord, le web et les mobiles suscitent la révolution du big data, les volumes des données et leur variété explosent ; ensuite, les performances des moyens de calcul – dont les GPU, et les moyens de stockage, croissent exponentiellement ; enfin, en 2012, se produit l’événement qui va lancer la « révolution de l’IA ».
Chaque année a lieu la compétition de référence en vision artificielle, Image-Net Large Scale Visual Recognition Challenge (ILSVRC). Jusqu’en 2011 les meilleures performances obtenues ont un taux d’erreur de classification top-5 de 25 %. D’une année sur l’autre les taux d’erreur baissent d’1 ou 2 %. Mais le 30 septembre 2012, le réseau de convolution AlexNet¹⁴ gagne la compétition avec un taux d’erreur de 15,3 %, un gain de 10,8 % par rapport au second. Et pourtant aucun des auteurs (Hinton avec ses étudiants) n’est un spécialiste de vision artificielle ! AlexNet est un modèle très lourd, dont toutes les techniques utilisées sont pourtant bien connues à l’époque, mais combinées avec une maîtrise technologique remarquable. Les années suivantes, tous les candidats à ILSVRC utiliseront des réseaux convolutionnels et les taux d’erreur continueront de descendre jusqu’à atteindre quelques % (mieux que l’être humain). Fin 2012, Hinton publie avec Microsoft Research, Google et IBM Research un article de synthèse¹⁵ établissant la supériorité pour la reconnaissance de la parole des réseaux convolutionnels profonds i.e. avec beaucoup de couches, et apprentissage ou deep learning.
Il y a donc bien un avant et un après-2012 : le monde entier se lance alors dans la « révolution de l’IA » et c’est le printemps de l’IA connexionniste. Le trio Hinton, Le Cun et Bengio publie un article¹⁶ dans Nature où ils décrivent en 9 petites pages (dont 2 de références) les techniques qui ont battu les meilleurs spécialistes mondiaux en vision et en parole. En 2019, le trio reçoit le prix Turing, le Nobel de l’informatique, doté de 1M$. Leur ouvrage¹⁷ devient la bible du domaine.
Près de dix ans après, les techniques de l’IA numérique (dont l’IA connexionniste) ont de multiples applications industrielles et font même parfois mieux que les humains. Aujourd’hui le terme IA se réfère généralement à ces techniques. On trouve des algorithmes d’IA dans tous les systèmes de perception (reconnaissance d’objets pour le véhicule autonome, de visages pour le comptage des foules ou l’identification de personnes en Chine, d’images médicales ou satellite ; reconnaissance de la parole avec les chatbots ou les assistants personnels – Apple Siri, Amazon Alexa, OK Google ; l’analyse de textes – NLP avec les algorithmes de transformers – BERT et successeurs) ; dans de nombreuses applications marketing ou service client (campagnes ; recommandations de produits, octroi de crédit, détection de fraudes…) ; les jeux où les techniques d’IA ont battu les champions humains (pour le jeu de go par exemple, où DeepMind¹⁸ utilise deep learning et reinforcement learning, avec l’IA qui joue contre elle-même) ; pour des applications en droit (analyse de contrats juridiques, prévision de récidive par exemple) ; l’industrie (maintenance prédictive, fonctions d’assistance au conducteur pour les automobiles) ; la génération automatique d’images ou vidéos pour les media (deep fakes), voire la création d’œuvres d’art ou de théories scientifiques, etc.
Les futurs enjeux ne sont pas (que) techniques
L’essor des applications industrielles de l’IA semble donc sans limite. Pourtant de nombreuses questions restent posées, dont celles-ci, pour ne citer que les principales : si l’IA est meilleure que l’humain dans certaines tâches, elle n’a aucune compréhension de la tâche et est incapable de passer d’une tâche à une autre, pourtant très voisine (on dit que l’IA est « étroite ») et encore moins de résoudre n’importe quelle tâche (l’IA dite « générale »), ce que les humains font couramment. De plus, l’IA apprend à partir des données qui lui sont fournies : si ces données sont « biaisées », l’IA en résultant le sera également (une application¹⁹ de reconnaissance du sexe à partir de photos contenant beaucoup d’hommes blancs fait 1 % d’erreurs sur les hommes blancs et 35 % sur les femmes à peau sombre).
L’éthique de l’IA est donc un problème très significatif. Ou encore, l’IA ne peut pas toujours « expliquer » ses résultats, ce qui peut nuire à la confiance de l’utilisateur ou poser problème si on veut auditer l’application. Puis, les fakes, créés par des GAN (Generative Adversarial Networks : deux réseaux profonds entraînés l’un contre l’autre) peuvent causer de réels problèmes quant à la véracité des sources, un sujet épineux pour les media ou la sécurité (robustesse et cybersécurité). Enfin, Minsky et Papert avaient déjà discuté de la difficulté à comprendre pourquoi l’IA fonctionne : les grands systèmes récents avec des milliards de paramètres (175 pour le récent modèle de langage GPT-3) deviennent quasiment impossibles à analyser. Il faut donc davantage de résultats théoriques et sans doute encore beaucoup de travail pour apporter la réponse à la simple question posée par Léon Bottou dans le prologue à la réédition de 1988 de Perceptrons : “Are there inherent incompatibilities between those connectionist and symbolic views ?”
1. Warren McCulloch and Walter Pitts. A Logical Calculus of Ideas Immanent in Nervous Activity. Bulletin of Mathematical Biophysics vol.5, pp. 115–133. 1943.
2. Frank Rosenblatt. Principles of neurodynamics. perceptrons and the theory of brain mechanisms. Cornell Aeronautical Lab Inc Buffalo NY, 1961.
3. Marvin Minsky, Seymour Papert. Perceptrons. Cambridge, MA : MIT Press. 1969.
4. https://proceedings.neurips.cc//
5. David E. Rumelhart, Geoffrey E. Hinton, Ronald J. Williams. Learning representations by back-propagating errors. Nature 323.6088 : pp. 533-536. 1986.
6. Yann Le Cun : Modèles connexionnistes de l’apprentissage. Thèse. Juin 1987.
7. Yann LeCun, Bernhard Boser, John S. Denker, Donnie Henderson, Richard E. Howard, Wayne Hubbard, Lawrence D. Jackel. Backpropagation applied to handwritten zip code recognition.Neural Computation 1, no. 4 : pp. 541-551. 1989.
8. Yann LeCun, Léon Bottou, Yoshua Bengio, Patrick Haffner. Gradient-based learning applied to document recognition. Proceedings of the IEEE 86, no. 11 : pp. 2278-2324. 1998.
9. Léon Bottou, Françoise Fogelman-Soulié, Pascal Blanchet, Jean-Sylvain Lienard. Experiments with time delay networks and dynamic time warping for speaker independent isolated digits recognition, Proceedings of Eurospeech-1989, Paris, France, pp. 2537-2540. 1989.
10. Emmanuel Viennet, Françoise Fogelman-Soulié. Connectionist methods for human face processing, In “Face Recognition : from theory to applications”, H. Weschler, J. Phillips , F. Fogelman-Soulié and T.S. Huang, eds. NATO ASI Series F, Computer and Systems Sciences, Vol. 163, Springer-Verlag, 124-156. 1998
11. Vladimir Vapnik. The nature of statistical learning theory. Springer science & ; business media, 2013.
12. Jerome Friedman, Trevor Hastie, Robert Tibshirani. The elements of statistical learning. Vol. 1, no. 10. New York : Springer series in statistics, 2001. https://web.stanford.edu/~hastie/Papers/ESLII.pdf
13. Leo Breiman. Statistical modeling : The two cultures (with comments and a rejoinder by the author). Statistical science 16, no. 3 : pp. 199-231. 2001.
14. Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. Advances in neural information processing systems 25 : pp. 1097-1105. 2012.
15. Geoffrey Hinton, Li Deng, Dong Yu, George E. Dahl, Abdel-rahman Mohamed, Navdeep Jaitly, Andrew Senior et al. Deep neural networks for acoustic modeling in speech recognition : The shared views of four research groups. IEEE Signal processing magazine 29, no.6 : pp. 82-97. 2012.
16. Yann LeCun, Yoshua Bengio, Geoffrey E. Hinton. Deep Learning. Nature, Vol. 521, pp 436-444. 2015.
17. Ian Goodfellow, Yoshua Bengio, Aaron Courville. Deep Learning. MIT Press. 2016.
18. Silver, David, Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert et al. " ;Mastering the game of go without human knowledge." ; nature 550, no. 7676 : pp. 354-359. 2017.
19. Joy Buolamwini, Gebru Timnit. Gender shades : Intersectional accuracy disparities in commercial gender classification. Conference on Fairness, Accountability, and Transparency. Proceedings of Machine Learning Research 81 : 1-15, pp. 77-91, 2018
L’Intelligence Artificielle symbolique : Utiliser l’abstraction du raisonnement
Article rédigé par Juliette Mattioli, docteur en mathématiques appliquées, Senior Expert Thales, Laurent Cervoni, docteur en sciences appliquées, directeur recherche Talan, Francis Rousseaux, docteur en informatique, recteur adjoint de l’université Galatasaray
Toutes les « branches » de l’intelligence artificielle (IA) ont pour même ambition de modéliser le raisonnement humain. Dans le domaine de l’intelligence artificielle symbolique, ce sont la capacité d’abstraction de l’être humain et l’utilisation de concepts, les relations entre des objets et les corrélations entre des situations qui sont privilégiées.
Plus discrète que l’intelligence artificielle connexionniste incarnée par l’apprentissage automatique avec l’apprentissage profond, l’IA symbolique aujourd’hui souvent appelée “GOFAI” pour Good Old Fashion AI reste active et adaptée à toute une catégorie de problèmes. En outre, elle peut venir compléter ou s’appuyer sur l’IA Numérique comme l’explique l’article Réconcilier les intelligences dans ce numéro. Nicholas Asher, chercheur CNRS à l’Institut de recherche en informatique de Toulouse (IRIT) et directeur scientifique du projet ANITI, définit cette branche comme une discipline qui « utilise le raisonnement formel et la logique ; c’est une approche cartésienne de l’intelligence, où les connaissances sont encodées à partir d’axiomes desquels on déduit des conséquences. La prédiction doit être juste même si l’on ne dispose pas de données exhaustives». Ce paradigme exploite la manipulation de connaissances sous formes de symboles et de propositions logiques couplée à un mécanisme d’inférence imitant le raisonnement humain dans la résolution de problèmes complexes, comme notamment les problèmes d’optimisation combinatoire, de planification, de décision multicritères. Sa force réside donc dans sa représentation des connaissances et dans son raisonnement par la logique donnant lieu dès le début des années 1970 aux systèmes experts¹ ou aux systèmes à base de connaissances. L’industrie financière utilise aussi la technologie CEP (Complex Event Processing) à base de règles spatio-temporelles dans les systèmes de trading.
Représenter les connaissances
Reposant sur l’idée que « l’intelligence est surtout liée à la connaissance plus qu’à un problème de raisonnement », Edward Feigenbaum, père du premier système expert DENDRAL définit en 1977 l’ingénierie des connaissances (IC) (Knowledge Engineering) comme « l’art d’acquérir, de modéliser et de représenter la connaissance en vue de son utilisation par un ordinateur ». Pour cela, on peut s’appuyer sur :
Des représentations logiques construites selon une syntaxe précise. Ainsi, une base de connaissances est un ensemble de formules décrivant le domaine sur lequel s’appliquent des règles de raisonnement, comme dans le langage PROLOG².
Des réseaux sémantiques, des graphes conceptuels³ bénéficiant de mécanismes de raisonnement induits par les opérations de graphes comme l’homomorphisme de graphes.
Des ontologies qui constituent en soi un modèle de données représentatif d’un ensemble de concepts dans un domaine, ainsi que des relations entre ces concepts.
Les ontologies sont aujourd’hui utilisées pour modéliser et partager un ensemble de connaissances dans un domaine donné, comme par exemple dans le web sémantique ou en génie logiciel. L’inférence, ou le raisonnement, repose sur des opérations de déduction à partir d’informations implicites. Ainsi, ce mécanisme permet de créer des liens entre les informations afin d’en tirer une assertion, une conclusion ou une hypothèse. Par exemple, l’inférence bayésienne est un raisonnement permettant de déduire la probabilité de survenance ou non d’un événement. On distingue cependant trois catégories d’inférence, basées sur la manière dont les problèmes sont résolus :
les moteurs dits à « chaînage avant » qui partent des faits et règles de la base de connaissances et tentent de s’approcher des faits recherchés par le problème. Les règles sont utilisées dans le sens conditions vers conclusion ;
les moteurs dits à « chaînage arrière » qui partent des faits recherchés par le problème et tentent par l’intermédiaire des règles, de remonter à des faits connus. Les règles sont utilisées dans le sens conclusion vers conditions ;
les moteurs dits à « chaînage mixte » qui utilisent une combinaison de ces deux approches chaînage avant et chaînage arrière.
Les méthodes de raisonnement par cas (Case-based Reasoning), introduites au début des années 1980 par Roger Schank reposent sur « l’idée » que l’on raisonne parfois en utilisant des analogies. Ces approches connaissent un regain car elles ont le bon goût d’être plus facilement explicables. Enfin, il faut noter que l’apprentissage machine s’est développé aussi dès les années 1980. Afin d’opérer des généralisations/particularisations de concepts, les systèmes symboliques apprentis combinent des stratégies de :
détection de similarités ;
recherche d’analogies ;
extraction d’explications.
À la frontière entre programmation mathématique et IA, la programmation par contraintes (PPC) est apparue à la fin des années 1980, pour la résolution de problèmes combinatoires complexes tels que les problèmes de planification, d’ordonnancement et d’allocation de ressources. Cette technologie repose sur le paradigme de séparation de la modélisation du problème avec sa résolution. Eugene Freuder dit : « En informatique, de toutes les approches en programmation, la programmation par contraintes se rapproche le plus de l’idéal : l’utilisateur décrit le problème, l’ordinateur le résout. ».
La modélisation du problème peut inclure la connaissance métier et se fait par le biais d’un ensemble de relations logiques : les contraintes. Des mécanismes de propagation des contraintes dans un arbre de branchement permettent la réduction du domaine de décisions. Le solveur de contraintes calcule alors une solution en instanciant chacune des variables à une valeur satisfaisant simultanément toutes les contraintes. Aujourd’hui, de nombreuses applications de la PPC sont déployées, comme dans la grande distribution qui optimise depuis longtemps sa logistique et sa gestion des stocks. Parmi les outils actuellement disponibles en programmation par contraintes, citons OPL et CPLEX d’IBM (issu du rachat d’ILOG), au sein de Python la librairie Python-Constraint (qui offre la gestion de contraintes basiques sur les domaines finis), SWI-PRolog (Prolog Open Source enrichi d’un module de gestion de contraintes) ou encore OR-Tools de Google.
Terrains de jeux de l’IA symbolique
Outre les cas déjà évoqués, l’IA symbolique est souvent utilisée pour concevoir des systèmes d’aide à la décision. En effet, un problème de décision consiste en un choix, ou un classement, entre plusieurs hypothèses mutuellement exclusives résultant d’un processus tenant compte des connaissances que l’on a sur l’état du monde, des préférences et/ou de l’objectif à atteindre. Ces connaissances peuvent être empreintes d’incertitude et les préférences sont par nature nuancées. Un outil simple pouvant être mis en œuvre est alors l’arbre de décision, qui représente un ensemble de choix sous la forme graphique d’un arbre. Les différentes alternatives sont alors les feuilles de l’arbre et sont atteintes en fonction de décisions prises à chaque étape. Cependant, la définition et l’utilisation d’un ou plusieurs critères de sélection sont nécessaires. Contrairement à la situation monocritère qui peut être résolue assez facilement, la décision multicritères nécessite des méthodes plus élaborées. Parmi les techniques utilisées, citons la méthode du What-if ou l’agrégation multicritères. Cette dernière consiste à évaluer globalement les différents candidats ou solutions proposées, à partir de la fusion des appréciations partielles. Reposant sur ce type d’approche, la startup américaine Psibernetix est devenue célèbre en 2016 pour avoir développé une IA à base d’arbres de décision, de logique floue et d’algorithmes génétiques (Genetic Fuzzy Tree) qui a régulièrement battu, lors de simulations de combats aériens, les pilotes les plus chevronnés.
Perspectives
Aptes à fournir des explications intelligibles, à développer des connaissances et à apprendre (machine learning symbolique), les systèmes conçus via l’IA symbolique s’insèrent très bien dans l’épistémologie scientifique traditionnelle car les théories sous-jacentes sont réfutables et interprétables. En revanche, ils pâtissent du fait que les représentations humaines se laissent rarement formaliser sans réductions et sans biais, et qu’elles tendent à évoluer rapidement. La théorie des systèmes d’IA symbolique semblait si naturelle aux scientifiques qu’ils n’ont pas vraiment eu à l’expliciter pour la déployer. C’est pourquoi les mises en garde et les critiques n’ont pas été entendues, et c’est aussi pourquoi les explications sont toujours venues bien après les réalisations de systèmes. Ainsi, pour David Sadek, VP Recherche Technologies et Innovation chez Thales « l’IA connexioniste est l’IA des sens, et l’IA symbolique est celle du sens ». C’est pourquoi, pour couvrir l’ensemble des capacités cognitives, l’avenir est dans l’hybridation de ces deux paradigmes de l’IA souvent mis en opposition. En effet, la principale difficulté de l’approche symbolique est la modélisation des connaissances, là où l’apprentissage peut servir à identifier des modèles présents dans les données. De plus, l’IA symbolique offre des capacités de raisonnement nécessaire pour expliquer, de façon intelligible pour l’usager, les raisons des décisions induites par l’algorithme même si celui-ci manipule des notions ou concepts qui échappent à la compréhension humaine. Ainsi, si l’IA Symbolique est aujourd’hui moins en vue que l’IA Numérique, elle a permis de résoudre des problèmes industriels importants (gestion de haut fourneaux avec SACHEM, dépannage automobile, etc.) et a montré sa capacité à offrir des solutions satisfaisantes quand peu de données sont disponibles ou qu’un raisonnement est modélisable (suivi médical, octroi de crédit, aide à la gestion de carrière). Dans tous les cas, elle est potentiellement complémentaire d’autres approches.
1. Citons les deux premiers systèmes experts : DENDRAL, spécialisé dans la chimie moléculaire créé en 1965 et MYCIN, spécialisé dans le diagnostic de maladies infectieuses du sang (méningites) et la proposition de thérapies associées développé en 1972.
2. Alain Colmerauer et Philippe Roussel développent à Marseille en 1972 le langage PROLOG (Programmation Logique), au départ pour traiter le langage. Un programme PROLOG est une suite de clauses de Horn sur lesquelles opère un mécanisme de raisonnement utilisant le principe de résolution. Comme LISP, Prolog utilise massivement la structure de liste et il est naturellement récursif.
3. Les graphes conceptuels sont introduits par John F. Sowa (chercheur à IBM) en 1984 pour formaliser la différence entre les concepts individuels (instances), les concepts génériques, et les classes (types).
Réconcilier les intelligences (artificielles)
Article rédigé par Laurent Cervoni, docteur en sciences appliquées, directeur recherche Talan, Éric de La Clergerie, docteur en informatique, chercheur à l’INRIA, Francis Rousseaux, docteur en informatique, recteur adjoint de l’université Galatasaray
Souvent les deux approches de l’intelligence artificielle, numérique (dont l’approche connexionniste)et symbolique, présentées dans les précédentes pages, sont opposées l’une à l’autre voire même parfois annoncées comme irréconciliables. L’opposition entre les deux démarches est liée à différentes visions ou explications du cerveau humain que l’IA essaie de modéliser… Pourtant, depuis de longues années, des chercheurs tentent de déterminer une voie pour associer les deux approches.
La vision symbolique traditionnelle présentée dans l’article qui lui est dédié coïncide avec une vision classique conceptuelle du monde et le traitement discret rendu possible par l’informatique. Concepts et relations entre concepts permettent une excellente compression de l’information essentiellement sous la forme très générale de graphes, ceux-ci (en extension ou en intension) pouvant traduire des structures plus ou moins compliquées sur lesquelles mener des raisonnements.
Néanmoins, ces concepts platoniciens reflètent rarement la réalité. Même un concept simple comme « chaise » traduit une grande diversité de formes, textures et même fonctions qui ne gênent cependant pas un humain pour reconnaître une chaise quand il en voit une ! L’ap- proche connexionniste, en particulier sur les aspects images, se révèle bien mieux adaptée pour capturer la nature floue et probabiliste du monde qui nous entoure et que nous conceptualisons.
Ainsi, tout naturellement, l’approche numérique (dont le connexionnisme en est le représentant le plus marquant) est apparue plus adaptée à des problèmes « continus » tels que le traitement du signal, des sons, de la parole, des images (dont l’écriture manuscrite) quand le symbolique s’attaquait au raisonnement et aux mondes discrets.
Cependant, l’intelligence humaine est vraisemblablement une combinaison de ces deux univers, avec plutôt du connexionnisme pour les phases de perception et plutôt du symbolique pour les phases de raisonnement. Aussi, dès les années 1990, de nombreux travaux ont cherché à démontrer l’intérêt de l’articulation entre la démarche connexionniste et la symbolique.
Si ces deux visions du cerveau et de ses mécanismes d’apprentissage expliquent succinctement les différences d’approche entre les deux intelligences artificielles, il n’en reste pas moins que des chercheurs ont pensé qu’il était efficace de tirer parti d’une modélisation symbolique enrichie par une approche neuronale et réciproquement.
Sens de la quête
Vouloir rapprocher les deux visions de l’intelligence artificielle n’est donc pas une lubie de chercheurs mais tente d’apporter de nouvelles solutions aux problèmes que pose la modélisation du raisonnement humain.
Une telle démarche d’hybridation trouve d’ailleurs tout son sens lors du démarrage d’un projet où certains concepts doivent être expérimentés et surtout dans tous les domaines où peu de données sont disponibles. Il faut noter qu’il existe des situations en entreprise où des projets concrets sont repoussés ou abandonnés faute de données alors même qu’il existe une expertise humaine. Initier un projet sur la base de cette expertise, appuyé par des outils symboliques, est alors une approche très efficace. Par exemple, FRMG, conçu par l’INRIA, initialement sur une base Prolog, a débuté par un modèle purement symbolique autour d’un « cœur » en Prolog (cf. article sur l’IA symbolique). Cependant, confronté à la richesse de la langue et à la nécessité de résoudre les ambiguïtés de certaines tournures, une partie heuristique est venue compléter l’approche symbolique afin de lever ces ambiguïtés.
Ces heuristiques, initialement exprimées sous forme logique en tant que contraintes pondérées manuellement, ont vu les poids ensuite appris automatiquement à partir de corpus annotés syntaxiquement via une forme de perceptron une fois de tels corpus disponibles.
Le schéma derrière FRMG est finalement typique d’un démarrage rapide sous forme symbolique par manque de données alors qu’il existe une expertise humaine.
Dans ces cas, l’apport de données, éventuellement issues de l’outil symbolique, permet ensuite un couplage avec des approches probabilistes et avec appren- tissage. Ainsi, le Prolog maison utilisé par FRMG a aussi été couplé avec une librairie de réseaux de neurones (DyNet), permettant de combiner raisonnement logique et apprentissage/inférence neuronal(e).
D’autres situations justifieraient une telle démarche d’hybridation itérative comme dans certains domaines de suivis thérapeutiques où il existe peu de données et le corps médical s’appuie sur des règles de consensus. La mise en œuvre de ces règles correspond bien à une modélisation symbolique qui peut alors contribuer à la génération de données exploitables par de « classiques » réseaux de neurones permettant ainsi de valider l’efficacité des règles initiales, de remettre en question, de valider ces règles voire d’en créer de nouvelles.
De manière plus systématique, divers travaux cherchent à formaliser et implanter le couplage de la logique avec probabilités et apprentissage. On peut ainsi citer les travaux de Pedro Domingos sur Markov Logic, qui associent la logique du premier ordre avec une démarche probabiliste, implantés en Open Source dans Alchemy http://alchemy.cs.washington.edu/ et illustrés dans son ouvrage The Master Algorithm : How the Quest for the Ulti- mate Learning Machine Will Remake Our World.
Néanmoins, il est également intéressant d’observer que le symbolique n’est pas nécessairement une surcouche de réseaux neuronaux. Ainsi, il existe de nombreuses bases de connaissances symboliques (bases de données, ontologies, réseaux sémantiques…) en général exprimables sous forme de graphes (Resource Description Framework par exemple). Divers travaux cherchent à s’appuyer sur des réseaux neuronaux pour exploiter de telles ressources symboliques.
Cela passe par exemple par de nouvelles architectures neuronales comme les Graph Convolution Networks et les Multihop Attention Networks… permettant le plongement des nœuds dans des espaces multidimensionnels (embeddings), des promenades au sein des graphes ou des rebonds d’information à information.
Enfin, les approches les plus ambitieuses seraient de faire émerger les concepts au sein des réseaux neuronaux sous des formes identifiables et manipulables via du raisonnement. Cela contribuerait à fournir une meilleure explicabilité de ces réseaux mais aussi un point de départ pour ensuite travailler sur ces représentations symboliques comme le font les humains. Un faisceau d’indices comme l’hypothèse du ticket de loterie (Frankle & Carbin 2019) tend en effet à suggérer que les modèles neuronaux actuels avec leurs gigantesques quantités de paramètres (jusqu’à mille milliards de paramètres) cachent en leur sein des modèles beaucoup plus petits et quasiment aussi bons.
Cette capacité à généraliser tout en compressant l’information est peut-être une voie vers des réseaux plus conceptuels. Notons aussi les approches cherchant à instaurer des structures dehiérarchie au sein des réseaux, telles les capsules neural network de Hitton : une capsule étant un groupe réduit de neurones permettant la détection d’un certain élément (comme un œil ou un nez) et l’activation d’autres capsules à un niveau hiérarchique plus élevé (par exemple pour vérifier des contraintes topologiques entre nez et yeux).
Perspectives
La voie qui consiste à ingérer d’immenses volumes de documents ou à manipuler simultanément d’importants de jeux de paramètres (à l’image de GPT-3 ou de Switch-C) est particulière- ment impressionnante car ces réseaux parviennent à un niveau de mimétisme humain particulièrement performant, sur un domaine donné. Mais elle exige une importante puissance de calcul brute (dans sa phase d’apprentissage). Parallèlement, il existe des gisements de connaissances symboliques sous-utilisées qui pourraient être mieux exploitées afin d’optimiser les phases d’apprentissages ou de bénéficier de leur pouvoir d’explication.
Simultanément, il existe de nombreuses situations concrètes où l’expertise humaine est plus aisée à représenter avant de l’enrichir par des modèles probabilistes ou connexionnistes afin de passer d’un modèle discret à un monde continu, ou plus proche de la réalité du monde. Réconcilier les deux intelligences artificielles pourrait aussi faciliter l’explicabilité des algorithmes et, partant, améliorer leur appropriation par les utilisateurs.
Dans son ouvrage, Pedro Domingos suggère d’ailleurs que la clé d’un système « intelligent » se construit sans doute à l’intersection de plusieurs approches (connexionniste, symbolique, bayésienne, etc.).
Les fondateurs de l’intelligence artificielle avaient conjecturé en 1956 que tout aspect de l’apprentissage (ou autre caractéristique de l’intelligence) pourrait peu à peu être décrit assez précisément pour qu’une machine puisse le simuler. L’approche était résolument pragmatique, guidée par une ingénierie logicielle, et les critiques (telles celles formulées par Dreyfus, Winograd ou encore Varela, souvent inspirées des thèses de la phénoménologie husserlienne), ont été suspendues au profit de l’expérimentation. Mais rien n’empêche, à l’heure de nouvelles faisabilités techniques et de meilleures articulations transdisciplinaires, de faire retour sur le projet initial pour en élargir les considérations théoriques.
Pour aller plus loin
Les références bibliographiques sont classées par ordre de dates décroissantes. Cette liste, non exhaustive, confirme le foisonnement d’idées et d’approches pour tenter d’associer connexionnisme et symbolique. La voie est toujours ouverte…
Honghua Dong, Jiayuan Mao, Tian Lin, Chong Wang, Lihong Li, Denny Zhou, Neural Logic Machines, 2019, https://openreview.net/pdf ?id=B1xY-hRctX
Richard Evans, Ed Grefenstette, Differentiable Inductive Logic Programming, 2018, https://uclnlp.github.io/nampi/talk_slides/evans-nampi-v2.pdf
Chunyang Xiao, Neural-Symbolic Learning for Semantic Parsing, thèse de 2017.
Pedro Domingos, The Master Algorithm : How the Quest for the Ultimate Learning Machine Will Remake Our World, 2015, Basic Books (pages 246 et suivantes).
Alex Graves, Greg Wayne, Ivo Danihelka, Neural Turing Machine, 2014 https://arxiv.org/pdf/1410.5401.pdf
Fernando Santos Osório, INSS un système hybride neuro-symbolique pour l’apprentissage automatique constructif, Thèse de 1998.
René Natowicz, Apprentissage symbolique automatique en reconnaissance d’images, 1987.
Cet article est extrait du magazine ActuIA. Afin de ne rien manquer de l’actualité de l’intelligence artificielle, procurez vous ActuIA n°16, actuellement en kiosque et sur abonnement :
Depuis septembre 2019, Liva Ralaivola dirige le département de la Recherche au sein du Criteo AI Lab, le laboratoire d’Intelligence Artificielle de Criteo, qu’il a rejoint en septembre 2018 comme chercheur à temps partiel, partageant alors son activité avec l’université d’Aix-Marseille (AMU).
Ancien chargé de mission IA pour cet établissement en 2018 et membre junior de l’Institut universitaire de France de 2016 à 2019, aujourd’hui en détachement de son poste de professeur à l’AMU, il nous présente le Criteo AI Lab, créé en juin 2018, composé d’une trentaine de chercheurs et d’une soixantaine d’ingénieurs qui travaillent à développer les capacités en machine learning (ML).
Liva Ralaivola nous parle de son expérience de recherche chez Criteo, leader mondial de la publicité en ligne et acteur-clé de l’écosystème Commerce Media, et la met en regard de son expérience dans le milieu académique.
Dans le cadre des jeux olympiques 2024, nous vous offrons chaque jour un article issu du magazine ActuIA n°4, dont le dossier principal est “Le sport à l’ère de l’IA”. Afin de découvrir le magazine ActuIA, nous vous invitons à vous rendre sur notre boutique. Tout nouvel abonnement d’un an vous donne droit à l’ensemble des archives au format numérique.
En France, le fossé séparant l’univers académique du milieu industriel semble évoluer vers une intense collaboration entre ces deux mondes. Quel type de passerelles établissez-vous chez Criteo pour relever le défi de la recherche dans le milieu industriel ?
Chaque écosystème a ses spécificités qu’il faut appréhender comme un tout et la capacité à s’y épanouir dépend d’un ensemble insécable de facteurs (expérience, envies, personnalité). Pour ma part, je suis très heureux de mon expérience chez Criteo, qui me pose le défi passionnant de maintenir l’équilibre entre des sujets de recherche fondamentale à visée long terme et d’autres de recherche appliquée, plus mouvants, dont les avancées doivent aider à déverrouiller à plus court terme des problématiques métiers. Un cercle vertueux est à entretenir là où les besoins métier alimentent la recherche fondamentale ou appliquée en nouveaux questionnements, dont les réponses doivent garantir en retour à notre infrastructure technologique de rester à la pointe et de bénéficier d’une assise scientifique robuste.
Le milieu académique est quant à lui le poumon de la recherche, c’est là que se développent les travaux les plus prospectifs et en rupture, lesquels bénéficient du dynamisme d’étudiants très bien formés. Les collaborations avec ce monde nous sont donc fondamentales, en ce qu’elles nous permettent d’élargir notre vision du ML pour moi, et pour le Criteo AI Lab en général, il y a une réelle complémentarité à travailler entre la recherche académique et la recherche industrielle.
Parmi les nombreuses passerelles mises en place, citons des co-encadrements de thèses, des postes à temps partiel Université/ Criteo, des postes de chercheurs invités, des enseignements en master, l’organisation de conférences ou workshops scientifiques (e.g. Machine Learning in the Real World, Workshops à NeurIPS, KDD, ICML) ou encore des hackathons ouverts au public sur nos données.
La structure du Criteo AI Lab est-elle semblable à celle des laboratoires universitaires que vous connaissez ?
Le Criteo AI Lab regroupe une trentaine de chercheurs (le groupe dont je suis responsable) en machine learning (ML), dont dix doctorants, et plus d’une soixantaine d’ingénieurs qui, pour la grande majorité, sont aussi spécialistes du ML – les compétences ML sont d’ailleurs loin d’être concentrées au Lab, des experts en ML opèrent également dans d’autres départements de Criteo. Dans les laboratoires universitaires de mathématiques et d’informatique que j’ai connus, la variété des domaines de recherche était plus grande et la proportion chercheurs/ingénieurs inversée.
Le laboratoire d’Informatique fondamentale de Marseille (aujourd’hui intégré au laboratoire Informatique et Systèmes) que j’ai dirigé comptait par exemple une centaine de scientifiques répartis en sept équipes de recherche (algorithmique, algorithmique distribuée, vérification, calcul naturel, bases de données, ML, traitement automatique de la langue). Les quatre ingénieurs du laboratoire venaient en appui de ces sept équipes qui, de fait, concentraient leurs efforts sur leurs deux missions, incontournables, à savoir la production scientifique et la formation.
Le ratio chercheurs/ingénieurs du Criteo AI Lab nous dote d’un continuum de compétences ML depuis la recherche fondamentale (et la vingtaine de publications associées aux plus grandes conférences ML : ICML, NeurIPS, COLT, AISTATS, KDD…) jusqu’au déploiement logiciel, un savoir-faire essentiel pour Criteo, dont l’avantage compétitif repose sur sa capacité à innover (et donc à transférer la recherche vers les besoins métier et inversement) et à faire fonctionner au quotidien des modèles de ML sur des téraoctets de données.
Cet article est extrait du magazine ActuIA. Afin de ne rien manquer de l’actualité de l’intelligence artificielle, procurez vous ActuIA n°16, actuellement en kiosque et sur abonnement :
Portrait de Liva Ralaivola Une collaboration entre l'univers académique et le milieu industriel
La demande des entreprises en matière d’intelligence artificielle ne cesse de croître. Le réseau social professionnel LinkedIn a constaté une augmentation des recrutements dans le domaine en France de 40 % sur l’année 2020, le positionnant dans la liste des 15 secteurs d’avenir (Rapport métiers d’avenir 2021). L’ensemble des métiers de l’IA est actuellement sous tension, mais le paysage va évoluer.
Dans le cadre des jeux olympiques 2024, nous vous offrons chaque jour un article issu du magazine ActuIA n°4, dont le dossier principal est “Le sport à l’ère de l’IA”. Afin de découvrir le magazine ActuIA, nous vous invitons à vous rendre sur notre boutique. Tout nouvel abonnement d’un an vous donne droit à l’ensemble des archives au format numérique.
Le data scientist, souvent vu comme l’alchimiste des temps modernes…
Qui aurait imaginé que le métier de statisticien, traditionnellement perçu comme une activité austère, puisse un jour être considéré comme « sexy » ? Les progrès de l’intelligence artificielle, puis son ascension au sommet de la courbe du Hype de Gartner, ont braqué les projecteurs sur ceux dont le rôle est aujourd’hui de « faire parler la donnée », les data scientists. Au point que leur métier a été présenté en 2012 comme le “sexiest job of the 21st century” par le Harvard Business Review ! Presque dix ans plus tard, Guillaume Rozier, data scientist français âgé de 25 ans, fait la tournée des talk shows français et The New York Times lui consacre un article. Son action au sein de CovidTracker révèle aux yeux de tous, gouvernements comme grand public, le pouvoir que détiennent ceux qui savent exploiter les données.
Avec <ViteMaDose>, la petite poignée de contributeurs bénévoles qu’il a fédérés pourrait bien frapper encore plus fort en contribuant à l’inflexion de la courbe de vaccination, et donc agir directement sur l’évolution de la pandémie en France. Simplement en facilitant l’accès aux centres de vaccination et la prise de rendez-vous. L’équipe de Guillaume Rozier a su se rendre précieuse alors qu’à la base elle n’a fait qu’exploiter des données publiquement accessibles (n’y voyons rien de péjoratif, bien au contraire).
Cette aventure permet de mettre fin à cette croyance populaire selon laquelle la force d’une entreprise réside dans la possession d’une grande quantité de données, alors qu’elle réside plutôt dans sa capacité à exploiter les données (internes comme externes). Celles-ci, souvent considérees à tort comme de l’or noir, encombrent inutilement nos disques durs lorsqu’elles ne sont pas correctement exploitées. Le rôle-clé du data scientist est de les transformer en source de valeur (encore faut-il qu’elles permettent de satisfaire les attentes).
…ne serait-il pas l’arbre qui cache la forêt ?
Le terme data scientist est souvent utilisé comme fourre-tout pour désigner le spécialiste intervenant dans la conception, l’implémentation ou le déploiement d’intelligence artificielle. Selon cette conception, toute personne travaillant de près ou de loin avec l’IA serait data scientist. Ce phénomène est assez naturel dans un domaine qui n’en est qu’à ses balbutiements¹.
Dans la réalité, si le rôle du data scientist est crucial, l’IA repose en fait sur une grande diversité de compétences et de savoir-faire, et de nouvelles spécialités continuent d’éclore au fil du tissage du lien entre entreprises et IA.
À ce jour, il n’existe pas de nomenclature ou d’identification officielle des métiers liés à l’IA. Pôle emploi ne propose par exemple pas de codes ROME permettant de se référer aux annonces correspondant à ce métier. La manière la plus simple pour les recenser est encore d’utiliser des mots-clés ou de s’appuyer sur des faisceaux de marqueurs plus ou moins distinctifs, comme la référence au langage de programmation Python dans les annonces.
Cette confusion n’est pas que sémantique, les rôles et périmètres de missions varient grandement selon la taille des équipes, leurs objectifs et l’organisation de l’entreprise. Le périmètre d’action d’un data scientist freelance ou évoluant au sein d’une petite équipe sera naturellement plus large que celui d’un data scientist travaillant au sein d’une grande équipe: il devra porter tour à tour la casquette de consultant, de data analyst, de data engineer, de machine learning engineer, de chef de projet…
1 : Ceci rappelle fortement l’emploi du terme “webmaster” au début des années 2000.
Collecte et analyse de données au plus près de l’entreprise sont des valeurs sûres
Selon une étude Eurostat, seulement 6 % des entreprises françaises et 7 % des entreprises européennes utiliseraient de l’intelligence artificielle en interne². Un chiffre voué à progresser rapidement au cours des dix prochaines années.
Pour tirer parti de l’IA sur des fonctions stratégiques de l’entreprise, ces dernières vont devoir collecter et analyser leurs données.
Or, si une tâche n’est pas centralisable, c’est bien celle-ci : qu’elle soit réalisée en interne ou par un prestataire externe (société de conseil, freelance, etc.), la phase de collecte et d’analyse nécessite une grande compréhension de l’activité de l’entreprise en demande. Deux sociétés concurrentes n’auront pas les mêmes données. Les tâches de collecte et de recueil d’informations auprès des experts métier, puis de préparation et d’exploitation des données sont et resteront primordiales.
2 : L’étude se concentre sur 4 cas d’usage : l’analyse big data reposant sur le Machine Learning, les chatbots, les robots de service et l’analyse big data en langage naturel.
Ce tableau ne fera pas l’objet d’un consensus, comme évoqué dans cet article, le profil de ces postes varie énormément d’une société à l’autre. Il illustre cependant la forte intrication entre les compétences des différents métiers.
Les profils de data engineer et de machine learning engineer sont promis à un développement rapide
L’évolution de l’IA des laboratoires de recherche vers les entreprises, et désormais la nécessité de son passage du stade de preuve de concept (POC – Proof Of Concept) au déploiement massif, crée de nouveaux besoins d’opérationnalisation à grande échelle des algorithmes. Les pratiques de DataOps et MLOps destinées à garantir l’industrialisation de l’IA sont amenées à monter en puissance.
Deux profils semblent se généraliser :
Le data engineer, qui a pour mission de créer l’infrastructure et d’assurer l’approvisionnement en données. Il est en quelque sorte l’administrateur système de l’IA. Il gère les bases de données et pipelines, rendant cette dernière possible.
L’industrialisation de l’IA s’appuie en grande partie sur l’emploi de plateformes telles que celle de Dataiku, qui facilite grandement la création de pipelines complètes, et peut tout autant répondre aux besoins d’un data scientist freelance qu’à ceux d’une équipe entière. Dans une grande équipe, le rôle de data engineer reste cependant incontournable.
Le machine learning engineer, qui a pour mission de déployer les modèles d’IA dans des applications logicielles.
Une partie de ces profils pourra naturellement provenir du vivier actuel de développeurs. Force est de constater que dans les faits, bon nombre de développeurs ignorent encore comment fonctionne l’IA, souvent parce qu’ils se heurtent à des croyances limitantes. L’IA se décloisonnera progressivement en se rapprochant du domaine du développement logiciel standard. D’autant qu’elle peut tout à fait être proposée sous forme d’API. La plupart des développeurs seront alors amenés à manipuler de l’IA, en faisant probablement une simple spécialisation du développement logiciel, au même titre qu’un développeur peut se spécialiser dans l’interfaçage avec les solutions de paiement en ligne.
Selon Antoine Barck, head hunter, data specialist chez Data Recrutement :
« Nos clients cherchent avant tout à lancer leur politique data-driven. Pour se faire, on remarque un fort intérêt pour les postes de data engineer / architect afin de structurer leur accès à la donnée. Clairement, ces postes sont les plus demandés, ils deviennent pénuriques et s’arrachent à prix d’or. Nous pensons que cette tendance devrait s’atténuer avec l’arrivée de toute une nouvelle génération de data worker. En effet, les écoles se sont adaptées au cours de ces dernières années et forment de nombreux profils. De plus, les entreprises structurent de mieux en mieux leurs pipelines de données, et pourront se concentrer sur son exploitation, ainsi les ML engineers, AI engineers, NLP engineers, et autres métiers issus de l’exploitation de la donnée vont à leur tour inonder le marché. » Cette opérationnalisation ne peut se dérouler sans recourir à de nouvelles compétences dans l’ensemble de la chaîne de production. Pour Laurent Guinard, responsable de l’Usine IA chez Pôle Emploi : « les product owners et product managers doivent transformer leurs pratiques. La clef du succès de l’IA réside aussi dans la capacité des porteurs produits à appréhender les spécificités d’un produit d’IA ».
L’offre de formation aux métiers de l’intelligence artificielle s’étoffe
L’étude « Formations et compétences sur l’Intelligence Artificielle en France », réalisée par l’OPIEEC en 2019 pour le Syntec Numérique estimait que 21 170 professionnels de l’intelligence artificielle et des data sciences pourraient être recherchés en 2023, contre 11 200 en 2019, soit une progression de 59 %. De nouvelles formations se créent pour répondre à la demande. La France est particulièrement réputée pour la qualité de ses cursus. Les diplômés des universités et des grandes écoles françaises s’exportent sans difficulté à l’international. Les formations évoluent afin de répondre de plus en plus concrètement aux besoins des entreprises : de la formation courte au Master of Science (MSc), les cursus en IA ont le vent en poupe. Les écoles “IA Microsoft” dont la formation est dispensée par Simplon ont pour mission de répondre directement aux besoins métiers des entreprises, en créant des cursus “développeur DATA IA” pouvant déboucher sur un contrat de professionnalisation au sein de l’une des entreprises-partenaires.
Python, R, Spark, TensorFlow, Scikit-learn, AWS, Hadoop, Scala et SQL se situent actuellement au sommet des classements des compétences recherchées. Mais pour combien de temps encore ? Face aux technologies qui se renouvellent sans cesse, Yann LeCun donnait le conseil suivant dans le premier numéro d’ActuIA : « Étudiez la physique, les maths, les statistiques, plus que les technologies dont la durée de vie est faible et qui vont disparaître d’ici quelques années. Si vous voulez vous lancer dans ce domaine, apprenez les méthodes sous-jacentes, parce que la science qui est derrière va évoluer, mais les maths de base, et la physique (très utile), ou encore le traitement de signal, la théorie des filtres, sont les bases réelles de l’IA, du machine learning et du deep learning ».
Le métier de data scientist requiert curiosité et sens de l’observation. Il consiste à appliquer ses compétences à l’étude d’un phénomène. Or, l’expertise d’un phénomène se construit avec l’expérience. Les data scientists se spécialisent généralement dans l’étude d’un phénomène, tel que le traitement du langage, la vision artificielle, l’apprentissage par renforcement ou dans un domaine d’application tel que la détection de fraude, la robotique, le marketing.
Une prise de conscience croissante de l’impact
Ces nouvelles formations pourraient accélérer l’inclusion et la progression de la diversité parmi les professionnels de l’IA, mais gare aux effets en trompe l’œil : le profil des ingénieurs évoluera-t-il réellement autant que celui des techniciens ? Dans son rapport mondial 2019 sur les talents en IA, Element AI a recensé seulement 18 % de femmes parmi les auteurs publiés à l’occasion de conférences d’importance. Un chiffre supérieur aux 12 % recensées l’année précédente³.
LinkedIn France a pour sa part enregistré 23 % de femmes parmi les recrutements de l’année 2020. Premiers signes d’encouragement, particularité géographique ou déficit de représentativité des femmes dans les conférences ? L’écart provient probablement d’une conjonction de facteurs, mais le constat reste simple : la parité est encore loin.
Une diversité que se propose d’accélérer la Charte Internationale pour une Intelligence Artificielle Inclusive, lancée par Arborus, destinée à promouvoir l’inclu- sion dans les métiers de l’IA.
À l’occasion de la célébration en avril du premier anniversaire de la charte à Bercy, Cristina Lunghi, présidente et fondatrice d’Arborus affirmait : « L’absence de mixité dans les métiers de l’IA pourrait avoir pour conséquence de ne pas générer de vision commune et partagée entre les femmes et les hommes et que les femmes ratent le tournant du XXIe siècle. »
Il en va bien évidemment de même pour la diversité sociale, la diversité des origines, de l’inclusion des personnes en situation de handicap ou encore de la concentration géographique des postes autour de quelques grandes villes (Paris, Toulouse, Nice, Le Havre…). Delphine Pouponneau, directrice de la Diversité et inclusion chez Orange, société signataire de la charte, rappelle : « N’oublions pas que l’intelligence artificielle est un formidable levier de développement. Elle porte également en elle une véritable opportunité pour réduire les inégalités. Pour les individus, elle est une promesse de carrière et d’émancipation, dont aucun pan de la société, et notamment les femmes, ne doit être exclu. » Une prise de conscience progressive de l’impact à venir de l’IA est en cours et nous voyons naître des écoles préparant l’évolution vers la société de demain, telles Aivancity, dont le postulat est que technologie, business et éthique sont indissociables. « Un secteur fait l’unanimité auprès des candidats à l’emploi, celui de la Tech for Good, les gens ressentent de plus en plus le besoin de mettre à profit leur savoir-faire au profit d’une cause sociétale. La prochaine décennie sera clairement celle de la Green Tech et autres objectifs de développement durable ! ». Antoine Barck, Data Recrutement
3 : Element AI explique sur son blog que cette différence peut être liée à l’élargissement du nombre de conférences analysées.
Une émergence des métiers non techniques
S’il est vrai que la discipline a éclos grâce à l’informatique et aux mathématiques, résumer l’intelligence artificielle à la sphère technique serait réducteur. C’est aujourd’hui bel et bien un sujet central dans nos sociétés. Nous assisterons au cours des prochaines années à l’émergence de nouveaux métiers.
Le métier de consultant en IA est bien sûr l’un des métiers appelés à se développer fortement. Outre sa mission de recueil des besoins, il doit être force de proposition et donc avoir une très bonne connaissance du domaine. Il sera le garant de l’adoption massive de l’IA en entreprise.
Dans Les métiers de l’intelligence artificielle, (192 p., L’étudiant éditions), Fabrice Mateo recense des dizaines de métiers liés de près ou de loin à l’intelligence artificielle. Certains existent d’ores et déjà, tel que celui de scénariste en IA, dont la mission est de fluidifier l’interaction homme-machine, d’autres sont promis à un bel avenir de par leur nécessité, à l’image de l’éthicien en IA. D’autres encore sont des descriptions plus insolites de métiers futurs, qui, s’ils peuvent prêter à sourire aujourd’hui, pourraient bien devenir réalité.
L’interdisciplinarité sera au coeur de la création d’emplois : des professionnels de tous horizons seront appelés à construire une passerelle entre leur spécialité et l’IA. Nous voyons d’ores et déjà naître des formations transversales, à l’image du DU Intelligence Artificielle Santé proposé par l’université de Bourgogne. La santé est l’un des secteurs dans lesquels les promesses de l’IA sont les plus enthousiasmantes.
L’OPIEEC identifie 4 autres secteurs porteurs :
les services financiers ;
l’industrie ;
le retail ;
les services professionnels.
Il identifie par ailleurs vingt enjeux pour la branche au niveau de la stratégie, de la formation et de l’emploi, parmi lesquels :
la formation du management de la branche ;
le développement de la pluridisciplinarité dans l’offre initiale et professionnelle ;
l’accompagnement des mobilités de professionnels en poste vers la data science ;
le positionnement des prestations vers plus de pluridisciplinarité et de stratégie IA ;
une meilleure définition des besoins RH liés aux profils de spécialistes en IA.
Quid des autres métiers ?
Certains s’inquiètent de possibles suppressions d’emplois dues à l’irruption de l’IA. Tout comme la mécanisation a permis d’automatiser des tâches manuelles répétitives, l’IA peut être vue comme le volet intellectuel de l’industrialisation, en permettant d’automatiser des tâches intellectuelles répétitives et peu épanouissantes. Elle est en ce sens un réel progrès pour le travailleur.
La disparition de certains métiers ne peut cependant pas être exclue, même s’il faut avant tout s’attendre à une évolution des activités, vers un recentrage sur des tâches à plus forte valeur ajoutée. À titre d’exemple, la saisie manuelle en comptabilité n’a plus lieu d’être. Un gérant d’entreprise témoigne : « Nous sommes en 2021 et mon cabinet d’expertise comptable imprime encore systématiquement factures et relevés de comptes pour les re-saisir au clavier dans le livre de comptes de mon entreprise. Des services permettent d’importer les opérations et de les catégoriser automatiquement mais il y est réfractaire. Je préfèrerais largement que mon comptable consacre son temps à me conseiller dans la gestion de mon activité qu’à effectuer cette saisie manuelle qui n’apporte rien et qui est source d’erreurs. » C’est effectivement sur le contact humain que vont progressivement se recentrer les métiers qui ne seront pas en lien direct avec l’IA. Serveurs et vendeurs en magasin ont de très beaux jours devant eux contrairement à ce que pourrait laisser présager le développement des caisses automatiques. Les professionnels non spécialistes ne seront pas pour autant tenus à distance de l’intelligence artificielle, mais profiteront de la capacité de l’IA à effacer la complexité technologique pour bénéficier des interactions les plus fluides possibles et s’y appuyer sans compétences techniques poussées.
Ces trente dernières années ont en fait très probablement été les plus éprouvantes pour les personnes peu à l’aise avec l’informatique. Le degré de connaissance ne sera plus un prérequis conditionnant l’accès à la technologie, mais la condition au regard critique permettant de prendre ses distances face aux résultats fournis. C’est la raison pour laquelle une acculturation à l’IA est et restera capitale. Au fil du temps, la nécessité n’est plus tant de comprendre son potentiel que d’en cerner les limites.
Cet article est extrait du magazine ActuIA. Afin de ne rien manquer de l’actualité de l’intelligence artificielle, procurez vous ActuIA n°16, actuellement en kiosque et sur abonnement :
Intelligence artificielle, machine learning… Ces “buzzwords” sont devenus des incontournables du vocabulaire technologique, mais combien de personnes comprennent réellement leur signification profonde ? Avant de nous aventurer plus loin dans cet article pour comprendre comment ces technologies peuvent être mises au service du e-commerce, prenons le temps de dissiper le mystère qui les entoure.
L’intelligence artificielle (IA) se caractérise par la création d’algorithmes informatiques capables d’accomplir des tâches avec une “certaine” intelligence. Ce domaine est très vaste et regroupe des dizaines de champs d’études comme par exemple les systèmes distribués (systèmes multi-agents), la résolution de problèmes d’optimisation (métaheuristique), la construction de systèmes experts, la satisfaction de contraintes ou encore la planification.
Le machine learning est l’un de ces champs d’étude de l’IA. Les algorithmes de machine learning ont la capacité d’apprendre de la donnée et d’en extraire de l’information pertinente grâce à l’application de règles statistiques qui définissent un modèle d’apprentissage. Avec le machine learning, le développeur ne code plus directement le moyen de résoudre un problème mais le moyen d’apprendre à résoudre le problème sur la base de données.
L’apprentissage automatique se décompose généralement en deux phases fondamentales : l’apprentissage et la prédiction. Durant la phase d’entraînement, l’algorithme ajuste ses paramètres en utilisant un ensemble de données, apprenant ainsi les modèles et relations sous-jacents présents dans les données. Une fois le modèle entraîné, il peut être déployé pour effectuer des prédictions ou prendre des décisions sur de nouvelles données au cours de la phase d’inférence.
Lorsque l’on sait qu’un site e-commerce gère une large gamme de produits, attire de nombreux utilisateurs effectuant diverses actions (navigation, expression d’un intérêt pour les produits, achats) et que tout cela génère une quantité considérable de données… On réalise immédiatement le potentiel significatif des algorithmes de machine learning dans la compréhension du comportement du visiteur et, par conséquent, dans l’amélioration directe de l’expérience client et l’optimisation des ventes.
Pour garantir l’efficacité de ces algorithmes, deux ingrédients sont nécessaires : des données de qualité et des contextes d’utilisation spécifiques. En voici quelques exemples concrets.
Le machine learning pour optimiser la recherche de produits
En matière de search, le machine learning peut être employé de différentes manières :
– Pour optimiser la compréhension automatique du sens sémantique d’une requête. Illustrons cela avec une recherche vocale. Lorsqu’un visiteur exprime “Je voudrais un canapé gris s’il te plaît”, le moteur de recherche, basé sur le machine learning, peut discerner que les termes importants sont “canapé gris” et que “gris” correspond à une couleur, en mettant de côté le reste de la phrase. Grâce à des technologies issues du NLP (Natural Language Processing) ou plus récemment grâce aux LLMs (Large Language Models), le moteur de recherche a la capacité de comprendre sémantiquement l’utilisateur, même si la phrase est formulée en langage naturel, de manière complexe.
– Pour proposer des produits en cas d’expression de recherche inconnue. En cas d’expression de recherche inconnue, il est envisageable d’utiliser un algorithme de réouverture. Celui-ci permet de présenter des articles pertinents même s’ils sont désignés avec des termes différents. Par exemple, si un visiteur saisit “sombrero”, le site marchand pourra proposer des bonnets en hiver ou des chapeaux de paille en été. Cette capacité résulte du fait que le machine learning comprend sémantiquement que “sombrero” est proche de “bonnet” ou de “chapeau”.
Un autre aspect de l’application de ces algorithmes consiste à personnaliser le parcours client.
Les algorithmes de machine learning ouvrent des perspectives en matière de personnalisation
Celle-ci peut se faire notamment au niveau du ranking de produits et se manifeste dans divers contextes :
– la saisonnalité : le ranking peut varier en accord avec les saisons. Par exemple, si les visiteurs cherchent des pulls en été, le système privilégiera des articles plus légers, tandis qu’en hiver, il mettra en avant des pulls plus épais et chauds.
– l’appétence utilisateur : lorsque ce dernier effectue des recherches de produits pour hommes puis saisit le terme “chaussures”, les résultats de recherche pourront être orientés vers les chaussures destinées aux hommes.
– le profil utilisateur : il est possible d’apprendre à classifier les clients et définir des profils types qui serviront ensuite à personnaliser les réponses du moteur de recherche ou des algorithmes de recommandation, voire à créer des listings de produits personnalisés sur la page d’accueil par exemple.
– les mots clés tapés : lorsque l’utilisateur saisit “jean”, le moteur de recherche comprend qu’il cherche principalement des pantalons plutôt que des vestes en jean, une déduction tirée de son apprentissage des attentes des utilisateurs. En ajustant le ranking en fonction des mots clés, le machine learning organise les produits de manière pertinente, en intégrant par exemple des notions de best-sellers.
La personnalisation peut également s’étendre à d’autres aspects, comme par exemple dans:
– les fiches produits : des suggestions peuvent être faites pour des produits populaires qui se marient bien avec celui que l’utilisateur visualise. Cette fonctionnalité repose sur des algorithmes de type cross-sell, identifiant les produits fréquemment achetés ensemble. De plus, il est possible d’afficher les choix d’autres clients qui ont acheté le même produit, offrant ainsi des suggestions complémentaires pour un panier. Une autre possibilité serait de suggérer des articles similaires, mais dans une gamme de prix supérieure (up sell).
– la page d’accueil : des produits personnalisés peuvent être proposés à l’utilisateur en fonction de son historique. Cela peut se faire de différentes manières : en ouverture pour lui faire découvrir des articles qu’il ne connaît pas encore mais qui pourraient l’intéresser, ou en fermeture pour lui suggérer des produits qu’il a déjà achetés ou qu’il acquiert fréquemment. Cette approche est particulièrement pertinente dans l’alimentaire, où la recommandation de produits réguliers facilite l’expérience d’achat.
Les scénarios d’utilisation mentionnés se concentrent sur des améliorations directes de l’expérience client. Parallèlement, le machine learning peut également contribuer à fournir aux personnes qui gèrent le site marchand des pistes d’amélioration de leurs tâches professionnelles.
Les algorithmes de machine learning : des alliés puissants pour les e-merchandiseurs
Considérons une situation où un groupe de produits semble mal ventilé au sein d’une catégorie. Les algorithmes de machine learning ont la capacité de détecter cette situation et de la signaler. Une intervention humaine serait ensuite nécessaire pour évaluer et qualifier la catégorie. De plus, les algorithmes peuvent également repérer des catégories qui manquent de pertinence, regroupant une variété de produits sans lien significatif et suggérer de la diviser en sous-catégories plus spécifiques.
Ces algorithmes offrent également aux e-merchandiseurs des suggestions de synonymes pertinents à intégrer dans le Back Office. Cette fonctionnalité repose sur l’analyse des zéro résultats des utilisateurs, permettant ainsi une optimisation fine des résultats de recherche. Par exemple, la proposition de synonymes tels que ‘applique murale’ pour ‘luminaire’, ou encore ‘chemise de nuit’ pour ‘nuisette’, démontre la capacité de ces technologies à anticiper et répondre aux attentes des clients.
En conclusion
L’expertise des algorithmes de machine learning réside dans leur aptitude à assimiler finement les comportements des utilisateurs, à identifier des tendances, à classifier et à révéler des corrélations significatives entre les produits. Cette capacité en fait des outils incontournables pour optimiser l’expérience globale des utilisateurs, en particulier dans les domaines de la recherche et de la recommandation. Ils ouvrent ainsi la voie à une expérience utilisateur plus immersive et personnalisée, contribuant de manière conséquente à maximiser le taux de conversion sur le site marchand.
À quoi ressemblera le futur de la recherche en ligne ? Il est certain qu’il ne se limitera plus aux requêtes par mots-clés telles que nous les connaissons aujourd’hui. Les évolutions récentes de l’intelligence artificielle, notamment dans le domaine de l’IA générative ; comme par exemple les LLMs (modèles de langage naturel capables de comprendre et générer du texte humain) utilisés par ChatGPT ; ouvrent la voie à de nouvelles perspectives.
Ces avancées technologiques offrent des opportunités de réinventer la manière dont nous utilisons les moteurs de recherche et pourraient évoluer vers une interaction plus directe, où la discussion avec les moteurs de recherche deviendrait aussi naturelle que celle avec un vendeur physique en magasin.
Demain, l’expérience utilisateur sur les sites web pourrait subir une transformation majeure, marquant une évolution significative par rapport à nos habitudes actuelles.
RunwayML, pionnier dans les outils de création multimédia alimentés par l’IA, a récemment annoncé la prochaine sortie de Gen-3 Alpha. Ce modèle de fondation, offrant des améliorations majeures en termes de fidélité, de cohérence et de mouvement par rapport à son prédécesseur, Gen-2, est présenté par la start-up comme le premier d’une série de modèles entraînés sur une nouvelle infrastructure conçue pour l’entraînement multimodal à grande échelle.
Gen-3 Alpha, dont le prédécesseur a été lancé en juin 2023, a été entraîné conjointement sur des vidéos et des images. Il alimentera, selon Runway, ses outils Text-to-Video, Image-to-Video et Text-to-Image, les modes de contrôle existants tels que Motion Brush, les commandes avancées de la caméra, le mode réalisateur ainsi que les outils à venir pour un contrôle plus précis de la structure, du style et du mouvement.
Une étape vers la construction de modèles généraux du monde
Gen-3 Alpha est, selon la start-up, une avancée vers ce qu’elle appelle un “General World Model”, un système d’IA qui construit une représentation interne d’un environnement et l’utilise pour simuler des événements futurs dans cet environnement. Un tel modèle sera capable de représenter et de simuler un large éventail de situations et d’interactions, comme celles rencontrées dans le monde réel.
Il devra non seulement capturer la dynamique du monde, mais aussi la dynamique de ses habitants, ce qui implique également de construire des modèles réalistes du comportement humain.
L’entraînement de Gen-3 Alpha est le fruit d’une collaboration entre une équipe interdisciplinaire de chercheurs, d’ingénieurs et d’artistes.
Gen-3 Alpha permet la génération de vidéos de 5 à 10 secondes basées sur des invites créatives complexes, comme celles-ci :
Reflets subtils d’une femme sur la fenêtre d’un train roulant à grande vitesse dans une ville japonaise ;
Travelling à l’épaule la nuit, suivant un ballon bleu sale flottant au-dessus du sol dans une vieille rue européenne abandonnée.
Il a été entraîné avec des légendes très descriptives et temporellement denses, ce qui lui permet de passer d’une scène à une autre de manière créative et fluide, tout en maintenant une narration cohérente par rapport à l’invite. Le modèle est également très bon dans la génération de personnages humains photoréalistes, expressifs et dotés d’un large éventail d’actions, de gestes et d’émotions, offrant ainsi des opportunités pour la narration immersive.
Sécurité et intégrité du contenu généré renforcées
Runway a intégré des mesures de protection robustes dans Gen-3 Alpha. La start-up a amélioré son système de modération visuelle interne pour surveiller et filtrer le contenu généré, afin de s’assurer qu’il respecte les normes éthiques et ne contienne pas de matériel inapproprié ou offensant. Elle a également adopté les normes C2PA (Coalition for Content Provenance and Authenticity) qui attestent de l’origine et de l’authenticité d’un contenu.
Des modèles Gen-3 personnalisés
Runway dit avoir établi des partenariats avec des organisations de divertissement et de médias de premier plan pour créer des versions personnalisées de Gen-3 Alpha, qui permettent d’obtenir des personnages plus cohérents et plus contrôlés sur le plan stylistique, et ciblent des exigences artistiques et narratives spécifiques, entre autres fonctionnalités.
La start-up n’a toutefois pas précisé la date de sortie du modèle.
Les technologies d’IA, de ML et d’automatisation sont en train de remodeler en profondeur les industries. Une récente enquête de Deloitte indique que 93 % des entreprises manufacturières estiment que l’IA sera une technologie clé pour stimuler la croissance et l’innovation.
L’industrie manufacturière a tout à gagner car elle s’appuie sur différents systèmes d’ingénierie qui génèrent de grandes quantités de données, lors de la curation des données, de la conception, ou encore lors de la création de modèles d’IA dans la fabrication des produits. Ces systèmes peuvent être liés à la gestion du cycle de vie des produits (PLM), la planification des ressources de l’entreprise (ERP), ou encore le pilotage de la production (MES). En outre, il existe une grande diversité de données dans l’écosystème des fournisseurs, des équipementiers, des régulateurs et d’autres parties prenantes.
D’autre part, les fusions et acquisitions courantes dans cette industrie, entraînent la nécessité d’intégrer constamment de nouveaux concepts, de nouvelles données et une nouvelle culture au sein des entreprises.
L’IA et le Machine Learning (ML) au service des résultats de l’entreprise
Au cours des dernières années, l’IA et l’automatisation ont eu un impact significatif sur l’industrie manufacturière en offrant la possibilité d’examiner les données historiques, de les nettoyer et de les rationaliser. L’IA peut supprimer les informations en double et réduire le nombre de biais afin d’assurer la normalisation de la base de données.
Les systèmes traditionnels d’ingénierie ont permis jusqu’à aujourd’hui de traiter, conserver et réutiliser les connaissances existantes. Ces systèmes transitent vers l’IA de nouvelle génération. Ils offrent une plus grande précision et une meilleure traçabilité, qui sont des atouts importants pour la recherche et le développement de la plupart des chaînes de valeur des produits. Les grands modèles de langage permettent désormais d’apporter l’échelle nécessaire au traitement et à l’extraction des connaissances à chaque fois que cela est nécessaire.
Les algorithmes d’IA peuvent piloter des analyses prédictives de la demande et de l’offre en utilisant des modèles ML simples, des modèles de réseaux neuronaux ou des réseaux neuronaux profonds.
Intégration et centralisation des données
Les outils alimentés par l’IA peuvent collecter et intégrer des données provenant de divers systèmes d’enregistrement, tels que les logiciels de CAO/FAO, les appareils IoT, les systèmes ERP, et plus encore, et compléter les entreprises grâce à leurs capacités d’IA. Par exemple, un réseau neuronal artificiel a été utilisé pour une entreprise aérospatiale mondiale afin d’aider à équilibrer les moteurs d’avion.
Nettoyage et préparation des données
L’automatisation peut contribuer au nettoyage et à la préparation des données pour l’analyse, en réduisant les efforts manuels et le temps requis pour le nettoyage des données. Par exemple, une classification et un résumé de documents juridiques ont été fournis à une entreprise d’informatique et d’électronique grand public.
Maintenance prédictive
Les modèles de maintenance prédictive pilotés par l’IA analysent les données provenant de capteurs et d’appareils IoT pour prédire quand un équipement ou une machine est susceptible de tomber en panne. Par exemple, une société minière mondiale utilise des camions lourds de type mammouth pour transporter le minerai. Un travail a été mené avec leurs équipes pour développer les modèles de diagnostic et de pronostic pour les camions afin d’identifier et de prédire les défaillances. L’ensemble du processus a été développé dans le cadre d’un projet de retour sur investissement.
Recommandations contextuelles et optimisation des performances
L’ingénierie des connaissances peut être utilisée pour développer des systèmes de recommandation qui fournissent aux utilisateurs des contenus, des produits ou des services pertinents en fonction de leurs préférences et de leur comportement. Cela peut grandement améliorer l’expérience de l’utilisateur en rendant les interactions plus efficaces et plus satisfaisantes.
Le contrôle et l’optimisation des performances des produits par le biais de tests utilisateurs permettent d’identifier et de résoudre les problèmes qui ont une incidence sur l’expérience des utilisateurs, ce qui débouche sur des conceptions plus accessibles.
Les ingénieurs logiciels peuvent développer des solutions logicielles personnalisées et des outils d’automatisation qui rationalisent divers processus de fabrication. Cela permet de réduire le travail manuel, de minimiser les erreurs et de garantir une qualité constante des produits, ce qui améliore l’expérience des opérateurs et des utilisateurs finaux.
Maximiser le potentiel de l’IA
Il n’est pas facile pour les fabricants d’intégrer les capacités de l’IA dans leurs systèmes et infrastructures existants. Il existe une résistance culturelle, un manque de talent et l’incapacité d’absorber les nouveaux algorithmes d’IA dans les systèmes existants. Ainsi, il est essentiel de préparer l’organisation à surmonter les obstacles, à conduire le changement et à favoriser une culture de l’innovation pour que l’adoption de l’IA soit couronnée de succès. Les chefs d’entreprise doivent ainsi identifier les freins technologiques qui entravent l’adoption de l’IA, telles que l’infrastructure obsolète, le manque de talents qualifiés ou les problèmes de cybersécurité, la croissance future de l’entreprise, et y remédier par le biais d’investissements et de formations.
Les leaders du secteur doivent ainsi devenir les fers de lance de l’innovation et du changement. Il se doivent de créer des espaces et des processus qui encouragent les employés à réfléchir, à expérimenter et à proposer des idées novatrices. Aussi, ils doivent mettre en place les formations nécessaires pour leurs employés et tirer ainsi pleinement parti des nouvelles technologies pour prendre les devants sur le secteur.
Pure Storage, fournisseur de technologies et de services de stockage de données, collabore depuis plusieurs années avec NVIDIA. A l’occasion de la GTC 2024, il a annoncé une nouvelle architecture de référence validée pour les serveurs NVIDIA OVX équipés de GPU NVIDIA L40S et FlashBlade//S. Cette validation offre aux entreprises un éventail élargi de choix de serveurs GPU, ainsi qu’une infrastructure d’IA prête à l’emploi pour des charges de travail d’entraînement, d’ajustement et d’inférence de petits modèles, rapide et efficace.
En 2018, Pure Storage et NVIDIA développaient une infrastructure pour le déploiement du machine learning à grande échelle. Baptisée AIRI (pour AI-Ready Infrastructure), avec l’objectif de permettre aux organisations de transformer les données, elle associait une baie de stockage 100 % flash de type FlashBlade (boîtier 4U) avec quatre boîtiers NVIDIA GPU DGX-1 et une paire de commutateurs 100 Gb Ethernet d’Arista Networks.
En 2022, Pure Storage lançait la nouvelle génération de l’infrastructure : AIRI//S, pilotée par la boîte de stockage FlashBlade//S, les systèmes NVIDIA DGX A100 et le réseau de bout en bout, grâce aux plateformes réseau Quantum Spectrum de NVIDIA. L’architecture de référence AIRI certifiée NVIDIA DGX BasePOD a, quant à elle, été lancée fin 2023.
S’appuyant sur sa collaboration continue avec NVIDIA, outre l’architecture de référence certifiée NVIDIA OVX Server Storage, Pure Storage annonce un pipeline de génération augmentée de récupération pour l’inférence de l’IA, un développement de génération augmentée de récupération et un investissement accru dans l’écosystème de partenaires IA :
Architecture de référence certifiée NVIDIA OVX Server Storage : Pure Storage a obtenu la validation OVX Server Storage, ce qui lui permet de fournir aux entreprises des architectures de référence de stockage flexibles et validées pour des solutions matérielles et logicielles d’IA optimisées en termes de coûts et de performances. Elle complète la certification de Pure Storage pour NVIDIA DGX BasePOD annoncée l’année dernière ;
Pipeline de génération augmentée de récupération pour l’inférence de l’IA : Pure Storage a créé un pipeline exploitant les microservices NVIDIA NeMo Retriever, les GPU NVIDIA, ainsi que son propre stockage d’entreprise all-flash. Ce pipeline accélère le temps d’apprentissage en utilisant les données internes de l’entreprise pour l’entraînement à l’IA, tout en éliminant le besoin de recyclage constant pour les LLM ;
Développement de génération augmentée de récupération : Pure Storage a créé une solution de génération augmentée de récupération pour les services financiers afin de résumer et d’interroger des ensembles de données avec une précision supérieure à celle des grands modèles de langage standards. Des solutions similaires seront lancées pour le secteur de la santé et le secteur public ;
Investissement accru dans l’écosystème de partenaires IA : Pure Storage collabore avec des partenaires tels que Run.AI et Weights & Biases pour optimiser l’utilisation des GPU et gérer le cycle de vie du développement des modèles d’IA. L’entreprise travaille également avec des revendeurs et des partenaires de services axés sur l’IA pour rendre les déploiements d’IA des clients plus opérationnels.
Rob Lee, Chief Technology Officer, Pure Storage, conclut :
“Pure Storage a reconnu très tôt la demande croissante en matière d’intelligence artificielle, en proposant une plateforme efficace, fiable et performante pour les déploiements d’IA les plus avancés. Grâce à notre collaboration de longue date avec NVIDIA, les dernières architectures de référence d’Intelligence artificielle validées et les preuves de concept d’IA générative apparaissent comme des composants essentiels pour les entreprises mondiales afin de résoudre les complexités du puzzle de cette technologie”.
Apple vient de dévoiler sa propre IA multimodale, MM1, capable de comprendre et potentiellement de générer aussi bien du texte que des images. Un projet de recherche scientifique, qui pourrait toutefois devenir une nouvelle version de l'assistant Siri…
Nous vivons une époque surprenante. Longtemps réputée pour la fermeture totale de ses logiciels, Apple vient de créer une IA plus ouverte qu'OpenAI dont l'ouverture est censée être la caractéristique principale…
Les chercheurs de la Pomme viennent de partager leurs travaux sur un LLM (large modèle de langage) d'intelligence artificielle multimodale.
Les chercheurs Apple révèlent leur IA multimodale
We live in such strange times. Apple, a company famous for its secrecy, published a paper with staggering amount of details on their multimodal foundation model. Those who are supposed to be open are now wayyy less than Apple.
À travers une étude publiée en ligne le 14 mars 2024 sur le portail arXiv, Apple met en lumière la façon dont elle a entraîné un modèle sur des données textuelles et des images.
Le document ne mentionne pas directement Apple, mais la plupart des chercheurs cités sont en lien avec la division Machine Learning de l'entreprise. Tout porte donc à croire que le projet émane de la firme de Cupertino.
Les modèles multimodaux de cette famille, baptisée MM1, contiennent jusqu'à 30 milliards de paramètres. Leur architecture regroupe différents composants : des encodeurs d'image, un connecteur de vision et de langage…
Ceci a permis de donner naissance à un modèle IA capable de comprendre à la fois les prompts textuels et ceux prenant la forme d'images.
Une approche de préentraînement novatrice et prometteuse
Curated a few takeaways from the Apple MM1 paper to share:
Encoder lesson: Image resolution has the highest impact, followed by model size and training data composition.
+15% perf 336px to 1702px +3% perf 224px to 336px +1% perf ViT-L to ViT-H (doubling in parameters) +3% perf… pic.twitter.com/uzgo5nEo4j
Comment l'expliquent les chercheurs, « nous démontrons que pour le préentraînement multimodal à grande échelle, l'utilisation d'un mix d'image-légende, de textes et d'images entrelacées, et de données textuelles est cruciale pour atteindre des résultats de pointe sur de multiples benchmarks ».
Ce modèle IA est actuellement encore en phase de pré-entraînement, et n'est donc pas encore suffisamment entraîné pour générer les résultats demandés.
C'est au cours de cette étape que l'algorithme et l'architecture IA sont utilisés pour concevoir le workflow du modèle et la façon dont il traite les données.
Les chercheurs d'Apple ont été capables d'ajouter la vision par ordinateur au modèle en utilisant des encodeurs d'image et un connecteur vision langage.
Lors des tests, ils ont réalisé que les résultats étaient supérieurs aux modèles existants au même stade de développement.
Leur approche semble donc plus concluante que les autres méthodes de pré-entraînement, ce qui pourrait permettre d'importants progrès dans le domaine de l'IA.
Alors, peut-on s'attendre à ce que cette IA soit incorporée aux produits Apple dans un avenir proche ? Début février 2024, lors de l'annonce des résultats financiers, le CEO Tim Cook avait estimé que des fonctionnalités IA seraient présentées plus tard dans l'année…
Cependant, ce papier de recherche n'est pas suffisant pour déterminer les véritables projets de la Pomme dans le domaine de l'intelligence artificielle.
En parallèle, le bruit court qu'Apple serait en discussion avec Google pour intégrer l'IA Gemini à la prochaine version d'iOS pour iPhone et iPad…
Néanmoins, comme tous les géants de la tech, il est clair qu'Apple ne peut faire l'impasse sur l'IA et se doit d'investir massivement dans la recherche pour dominer cette nouvelle technologie révolutionnaire !
ElevenLabs, l'outil IA de synthèse vocale est un grand atout pour plusieurs utilisateurs. Il est capable de générer une voix naturelle pour enrichir vos contenus. Et ce n'est que sa fonctionnalité principale. L'outil réserve encore des surprises.
Oui, l'IA est désormais sur tous les plus. Elle est capable de créer des textes, des images, des vidéos, et même donner une voix à vos contenus. Cette dernière fonctionnalité est le grand atout d'ElevenLabs. En effet, cette IA générative est la référence de générer une voix dans plusieurs langues. C'est alors une aubaine pour plusieurs métiers. Développeurs, entreprises, créateurs de vidéo, ou autres. Découvrez sans tarder ElevenLabs.
ElevenLabs : définition
Un outil de synthèse vocale basée sur l'IA. Ces quelques mots résument parfaitement l'atout principal d'ElevenLabs. En effet, l'outil est capable de générer des voix en se focalisant sur des contenus textuels. Il se concentre alors sur des algorithmes avancés, ainsi que sur le Machine Learningpour atteindre son objectif.
L'utilisation d'ElevenLabs ouvre la porte à plusieurs opportunités. En effet, l'usager peut créer des contenus vocaux rapidement avec cette IA vocale. Pour les entreprises, ElevenLabs figure parmi les techniques les plus recommandées pour animer les prospections. Les professionnels du cinéma, des vidéos, ou autres contenus du genre trouveront une utilité efficace à ElevenLabs.
Et l'outil s'adapte aussi aux débutants, et aux particuliers. Ces derniers peuvent bénéficier de l'essai gratuit lors de l'inscription. C'est une opportunité pour découvrir les fonctionnalités de base.
Quelles sont les fonctionnalités phares d'ElevenLabs ?
La synthèse vocale… bien sûr
L'IA est maintenant capable d'imiter la voix humaine. Cette fonctionnalité s'illustre surtout avec ElevenLabs. Ici, l'utilisateur n'a qu'à rédiger les textes et l'IA les convertit en contenus vocaux. Et tout le monde trouvera un usage efficace à ce privilège d'ElevenLabs. De la création de voix off, aux développements d'assistants virtuels, l'outil est sur tous les fronts.
VoiceLab, pour améliorer une voix existante
Les utilisateurs peuvent personnaliser leurs propres enregistrements. Certes, cette fonctionnalité n'est pas très exploitée par le grand public. Pourtant, elle est capitale pour les entreprises high-tech. Avec VoiceLab, ces professionnels peuvent créer des voix uniques adaptées à leurs valeurs et à leurs produits. D'un autre point de vue, c'est aussi une technique pour donner des options de personnalisation sur les assistants virtuels.
Oui, ElevenLabs est aussi une IA destinée aux professionnels. Et pour rationaliser les différentes missions, l'outil dispose de fonctionnalité « Projet ». Les utilisateurs peuvent alors catégoriser les tâches selon leur importance. Il y a des emplacements spécifiques pour ces projets. Chaque membre de l'équipe aura un aperçu des missions et devra intervenir en cas de besoin.
Bibliothèque vocale
L'IA offre plusieurs modèles vocaux aux utilisateurs. C'est un gain de temps considérable, surtout pour certains professionnels. En effet, ElevenLabs permet de passer l'étape d'enregistrement audio. L'usager n'a qu'à choisir la voix qui s'adapte le plus à son projet, et l'IA fera le reste.
Le partage de contenu
ElevenLabs est un outil destiné à tous les profils. Tous les abonnés peuvent alors partager leurs contenus. C'est un moyen pour apprendre des plus expérimentés, ou d'évaluer ses capacités sur la plateforme d'ElevenLabs.
Les avantages d'ElevenLabs
Pour certains professionnels, ElevenLabs permet d'accélérer la réalisation des projets. Avec la possibilité de générer des voix naturelles, les spécialistes n'ont pas besoin de passer des heures aux studios d'enregistrement. Toutefois, l'IA ne pourra pas remplacer les acteurs de voix off humains. Il reste juste un outil.
ElevenLabs permet d'améliorer les stratégies de communication d'une entreprise. Prenons l'exemple d'une marque de vêtements pour femme. Logiquement, la prospection doit se baser sur une voix féminine. Et ElevenLabs est la clé pour atteindre cet objectif. Les utilisateurs peuvent alors personnaliser le rendu en fonction des attentes.
Par ailleurs, l'outil permet aussi de répandre ses résultats à travers la planète. Avec plus de 30 langues disponibles, ElevenLabs s'adapte à tous les profils.
Added 30+ voices to ElevenLabs' Voice library on TypingMind!
All custom voices from your https://t.co/LH3EjGAiB7's VoiceLab will be seamlessly synced with TypingMind too!
Et ce n'est pas tout. Cette IA améliore la productivité et l'efficacité des équipes. En se basant sur ce concept, l'outil sera une des clés du succès sur le long terme. Toutefois, il faut une petite connaissance du secteur de l'IA pour maîtriser ElevenLabs.
L'outil de synthèse vocale de référence affiche alors une polyvalence optimale avec tous ces avantages.
Pour qui ?
ElevenLabs est destiné à tout le monde. L'outil peut être exploité à des fins professionnelles, ou pour juste s'amuser avec la technologie.
Les créateurs de contenu
Cette catégorie comprend les rédacteurs, les podcasteurs, et les créateurs de vidéo. ElevenLabs facilite alors la transformation des contenus textuels en fichiers audio. C'est un gain de temps considérable, surtout pour les créateurs qui doivent animer leurs pages et leurs sites chaque semaine. Toutefois, il faut analyser un peu le rendu avant de le publier. La voix doit être en accord avec la valeur du créateur de contenu.
Les entreprises
ElevenLabs est aussi un atout majeur pour les entreprises. Ici, toutes les fonctionnalités peuvent être utilisées par ces équipes de professionnels. La section « projet » permet de faciliter l'analyse et le suivi des différentes tâches. L'outil de personnalisation, VoiceLab, est la clé pour générer une voix unique à l'image de l'entreprise.
Ainsi, les contenus de prospections seront uniformes, basés sur une seule et même voix. C'est la technique de communication la plus recommandée pour attirer les clients.
Les enseignants
Les professeurs de langue peuvent exploiter les différentes langues d'ElevenLabs. Ils n'ont qu'à rédiger leurs cours, et l'IA pourra les lire avec la voix choisie. C'est une technique pour diversifier les contenus. En plus d'avoir des livres, les fichiers audio facilitent aussi l'apprentissage.
Les développeurs
L'assistance vocale est devenue incontournable dans le monde de la high-tech. Les géants du milieu ont compris ce concept avec Siri ou Alexa. Et certains développeurs commencent aussi à suivre cette tendance.
Avec ElevenLabs, ces professionnels peuvent créer des voix uniques pour leurs applications et logiciels.
ElevenLabs et les entreprises
L'outil IA a déjà inscrit son nom dans le monde de la high-tech. Il figure actuellement parmi les références dans sa catégorie. Plusieurs entreprises ont été séduites par sa performance dans le domaine de la synthèse vocale. C'est le cas de Google, qui a employé ElevenLabs dans ses outils. L'utilisateur peut alors générer des contenus vocaux en quelques clics avec cette fonctionnalité de Google.
Et ce n'est pas tout. Toutes les entreprises peuvent exploiter ElevenLabs. En effet, elles peuvent cloner la voix du PDG, et des autres cadres. C'est une technique de communication efficace pour animer les annonces et les messages pour les collaborateurs.
Comment utiliser ElevenLabs ?
Même si ElevenLabs a des fonctionnalités très avancées, son utilisation est assez facile. Pas besoin d'être un développeur expérimenté pour manipuler l'outil. Vous devez connaître vos attentes pour avoir les meilleurs résultats possibles.
Commencez par vous rendre sur le site d'ElevenLabs. Il suffit de créer un compte dans la section inscription. Vous n'aurez qu'à saisir vos informations. Et n'oubliez pas que l'outil prend aussi en charge les plateformes comme Google, Facebook, ou Github durant cette étape.
Vous pourrez enfin lancer votre projet. Les contenus textuels seront votre point de départ. Choisissez ensuite la voix dans la bibliothèque vocale d'ElevenLabs. Personnalisez le tout pour avoir le meilleur rendu possible. Il ne reste plus qu'à affiner l'audio pour qu'il s'adapte avec votre valeur. Et c'est tout.
Focus sur les abonnements
L'offre gratuite
Oui, plusieurs fonctionnalités d'ElevenLabs sont accessibles gratuitement. Cette offre est destinée à tous les utilisateurs qui veulent tester les performances de l'outil. Cependant, il y a quelques limitations.
L'offre gratuite est limitée à 10 000 caractères de texte par mois. L'utilisateur ne peut pas dépasser ce seuil. Toutefois, il peut toujours créer des contenus vocaux sous différentes langues, avec la possibilité de modifier l'accent. Si ces offres ne suffisent pas, il y a des abonnements payants.
Starter
C'est la première offre payante d'ElevenLabs. Ici, la limite de caractères est à 30 000 par mois. C'est l'équivalent d'un contenu audio de 30 minutes. Toutefois, vous pourrez répartir les rendus sous plusieurs fichiers audio. Il est aussi possible de cloner votre voix. L'accès à Dugging Studio, la plateforme de doublage d'ElevenLabs est au rendez-vous. N'oubliez pas que vous aurez l'autorisation commerciale de l'outil avec cette offre.
L'abonnement coûte 4,59 euros mensuels, mais en cas de promotion, le prix peut descendre jusqu'à 0,92 euro.
Creator
L'offre donne accès à plus de 100 000 caractères, soit 2 heures d'audio. Ici, vous pourrez créer des voix réalistes pour des contenus professionnels. La qualité sera au rendez-vous, car l'audio est à 192 kbps. Et n'oubliez pas que la fonctionnalité « projet » sera aussi disponible pour vos équipes.
Le prix est de 20,21 euros mensuels. Dans certains cas, ElevenLabs peut faire une réduction de -50 % pour les nouveaux utilisateurs.
Pro
À 90,94 euros, vous aurez accès à 500 000 caractères, soit 10 heures d'audio. L'option de « suivi » figure aussi parmi les fonctionnalités de cette offre. La sortie audio est de 44,1 kHz via API.
Scale
C'est l'offre de référence pour les grandes entreprises. 40 heures d'audio, soit 2 000 000 de caractères seront au rendez-vous. L'utilisateur bénéficie aussi d'une assistance prioritaire. Le tout est à 303,12 euros par mois.
Tout est clair pour Elon Musk. D'ici 2025, l'IA va surpasser l'intelligence humaine. Cependant, cette déclaration ne fait pas l'unanimité dans le monde de high-tech. Plusieurs spécialistes, comme ce français a fourni des explications intéressantes pour réfuter l'idée du patron de X.
On le sait tous, Elon Musk est un grand adepte de l'IA. Le multimilliardaire a toujours tenté de rivaliser avec les géants du secteur avec Grok et xAI. Et il a confiance en son projet. Récemment, Musk a affirmé que l'IA sera bientôt supérieure à l'intelligence humaine. Cette situation sera réelle en 2025. Toutefois, les spécialistes du milieu ne sont pas emballés par cette idée.
Rendez-vous en 2025
Elon Musk, le multientrepreneur a réagi à un podcast d'un grand nom de l'IA. Pour lui, le rapport de force va basculer dès 2025. À partir de ce moment, l'IA sera au-dessus de l'être humain.
« L'IA sera probablement plus intelligente que n'importe quel humain l'année prochaine » extrait de la déclaration d'Elon Musk. Selon ses prévisions, les outils IA seront plus performants que l'intelligence de tous les humains sur la planète.
AI will probably be smarter than any single human next year. By 2029, AI is probably smarter than all humans combined. https://t.co/RO3g2OCk9x
Cette réaction de Musk a alors appuyé une idée similaire dans le domaine du high-tech. En effet, un autre spécialiste, Ray Kurzwell, a aussi prévu une émergence notable de l'IA. Selon lui, l'intelligence artificielle rivalisera avec l'humain en 2029.
« Nous n'y sommes pas encore tout à fait, mais nous y serons, et d'ici 2029, l'intelligence de l'IA sera la même que celle de n'importe quelle personne. Je suis en fait considéré comme un conservateur. Les gens pensent que cela arrivera l'année prochaine ou l'année suivante. » Ray Kurzwell.
À noter que ce spécialiste n'est pas un débutant dans le domaine de l'IA. Il a déjà œuvré pour le Machine Learning de Google en 2012. Il a aussi écrit plusieurs ouvrages en rapport avec sa zone d'exercice.
Yann LeCun, le spécialiste qui a réfuté l'idée d'Elon Musk
Une telle déclaration d'Elon Musk attire forcément l'attention dans le monde de l'IA. Plusieurs spécialistes ont réagi, mais les arguments d'Yann LeCunont été les plus convaincants. Pour lui, l'IA ne dépassera jamais l'humain, ni en 2025 ni en 2029.
L'expert français s'est alors appuyé sur des faits réels pour fonder son raisonnement. Il a directement remis en question les projets de Musk. Ce dernier avait tenté de concevoir une voiture entièrement autonome. Mais à ce jour, cette idée révolutionnaire n'a aucun résultat tangible. Mais Musk veut rassurer le public concernant sa réalisation.
« Nous aurions des systèmes capables d'apprendre à conduire une voiture en 20 heures de pratique comme n'importe quel jeune. Or, nous ne disposons toujours pas d'une conduite autonome totalement fiable » Yann LeCun.
No. If it were the case, we would have AI systems that could teach themselves to drive a car in 20 hours of practice, like any 17 year-old.
But we still don't have fully autonomous, reliable self-driving, even though we (you) have millions of hours of *labeled* training data.
SpaceX a aussi déçu sur plusieurs plans. Mais Yann LeCun s'est surtout focalisé sur le non-respect des délais de travail de cette entreprise. Et ce ne sont que des exemples.
À noter que Yann LeCun est un grand nom de l'IA. Ce spécialiste a déjà gagné le Prix Turing, le Nobel du high-tech. Son argumentation devrait être considérée par Elon Musk.
Récemment, une équipe de chercheurs chinois a proposé une nouvelle méthodologie prometteuse pour le machine learning. De quoi s'agit-il ? Eh bien, c'est de transformer des modèles d'IA en véritables scientifiques capables d'améliorer des expériences. Ces modèles pourront ainsi résoudre des problèmes scientifiques bien plus complexes.
Zoom sur les bases de cette innovation sur le machine learning
Cette méthode nouvellement créée repose sur l'intégration de connaissances préalables. On citera, par exemple, les lois physiques ou la logique mathématique, tout cela, dans le processus de formation des machines. Une publication récente dans la revue Nexus, reconnue pour son processus d'évaluation par les pairs, a d'ailleurs cette révolution potentielle.
En effet, les modèles d'apprentissage profond, ont déjà marqué de leur empreinte le domaine de la recherche scientifique. Ils ont même dévoilé des corrélations et des modèles cachés, ce qui a permis d'ouvrir la voie à de nouvelles découvertes. En tout cas, l'insertion d'un cadre d'apprentissage informé pourrait pousser ces capacités encore plus loin. On envisagerait, en ce sens, à doter les IA d'une compréhension préalable qui enrichit et guide leur apprentissage.
Sora IA : ce qu'il y a à savoir sur ce produit
On prendra l'exemple de Sora, le modèle textuel-vidéo développé par OpenAI. Celui-ci affiche parfaitement les progrès et les limites actuelles de l'IA. Tout d'abord, notons qu'il est salué pour sa capacité à générer des images et des vidéos d'un réalisme saisissant. Résultat, Sora marque une avancée significative dans le domaine de l'IA générative. Il est à souligner que les développeurs d'OpenAI ont conçu ce modèle pour comprendre comment les objets existent et interagissent dans le monde réel.
Néanmoins, malgré ses réussites, Sora se heurte à des difficultés lorsqu'il s'agit de simuler fidèlement certaines dynamiques du monde réel, comme le comportement du verre lorsqu'il se brise. Cela s'explique par le fait que l'outil, bien qu'entraîné sur d'immenses quantités de données visuelles, n'intègre pas de compréhension des principes physiques fondamentaux tels que la gravité.
« Sans une compréhension fondamentale du monde, un modèle reste plus proche de l'animation que de la simulation réelle », lance Chen Yuntian, professeur à l'Institut de Technologie de l'Est (EIT) et co-auteur de l'étude. Cette remarque traduit l'importance d'aller au-delà de la simple analyse de données. Après tout, il est nécessaire de construire des modèles d'IA véritablement capables de simuler et d'interagir avec le monde réel.
Un changement de cap pour le machine learning
Face à ces défis, les chercheurs de l'Université de Pékin et de l'EIT ont introduit le concept de machine learning informé. Cette approche novatrice se veut combiner la connaissance préalable avec les méthodes traditionnelles d'apprentissage basées sur les données. L'idée est de prémunir les modèles d'IA avec un lot de connaissances pouvant aider quant à l'interprétation plus précise des données.
Pourtant, intégrer efficacement cette connaissance préalable pose un défi majeur. Les chercheurs doivent sélectionner soigneusement les informations pertinentes à inclure, puisqu'une surcharge de règles et de principes peut entraîner l'effondrement des modèles. « Face à une quantité élevée de connaissances et de règles, ce qui est souvent le cas, les modèles de machine learning informé actuels ont tendance à rencontrer des difficultés, voire à échouer » explique toujours Chen. Un cadre d'évaluation est donc indispensable afin de former des modèles prédictifs plus robustes.







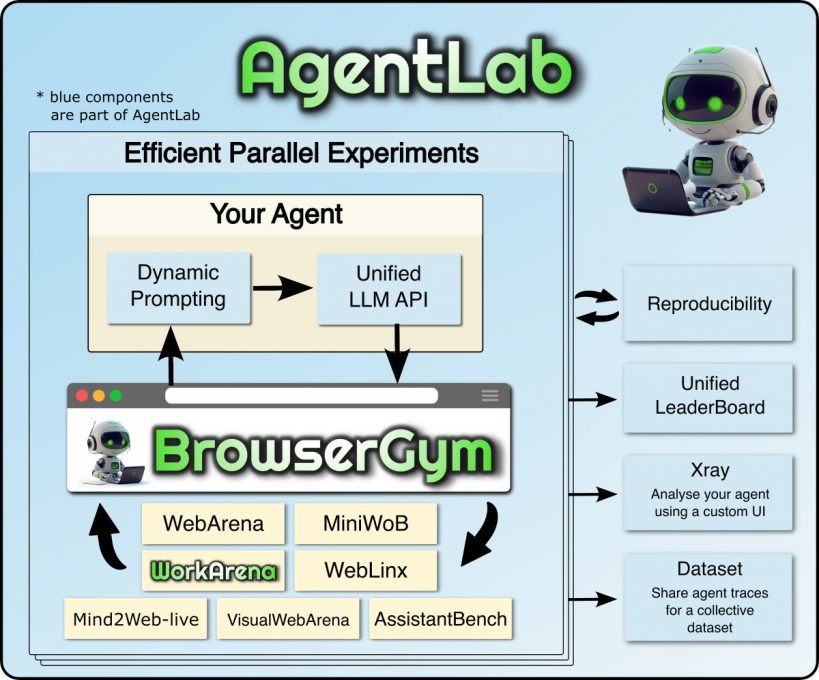









 Andrew Ng, professeur à Stanford, cofondateur de Google Brain (division de recherche fondamentale IA de Google) a très largement contribué à populariser les méthodes et les techniques de l’intelligence artificielle, particulièrement à travers son célèbre cours en ligne Coursera, passage obligé pour tous les codeurs d’IA.
Andrew Ng, professeur à Stanford, cofondateur de Google Brain (division de recherche fondamentale IA de Google) a très largement contribué à populariser les méthodes et les techniques de l’intelligence artificielle, particulièrement à travers son célèbre cours en ligne Coursera, passage obligé pour tous les codeurs d’IA.












 Added 30+ voices to ElevenLabs' Voice library on TypingMind!
Added 30+ voices to ElevenLabs' Voice library on TypingMind!
