Selon un message publié sur X le 12 janvier 2026 par l'insider zhihuipikachu, OpenAI et Jony Ive travailleraient en priorité sur un appareil audio « inédit », visant à concurrencer les AirPods. Voici ce que l'on sait.
Selon un message publié sur X le 12 janvier 2026 par l'insider zhihuipikachu, OpenAI et Jony Ive travailleraient en priorité sur un appareil audio « inédit », visant à concurrencer les AirPods. Voici ce que l'on sait.
À partir d'octobre 2025, les enceintes et écrans connectés Google Home et Google Nest recevront progressivement une mise à jour majeure, qui remplacera Google Assistant par l'assistant Gemini. Tous les anciens modèles sont éligibles, mais il y a des différences.
À partir d'octobre 2025, les enceintes et écrans connectés Google Home et Google Nest recevront progressivement une mise à jour majeure, qui remplacera Google Assistant par l'assistant Gemini. Tous les anciens modèles sont éligibles, mais il y a des différences.
Dans les prochains jours, Google commencera à remplacer Google Assistant par Gemini sur ses enceintes connectées. Le passage à une intelligence artificielle générative s'annonce révolutionnaire pour la maison connectée : les enceintes pourront réaliser des actions sophistiquées ou discuter avec leurs utilisateurs pendant plusieurs minutes. L'analyse des flux vidéo, pour les caméras de surveillance, va aussi s'améliorer.
Dans les prochains jours, Google commencera à remplacer Google Assistant par Gemini sur ses enceintes connectées. Le passage à une intelligence artificielle générative s'annonce révolutionnaire pour la maison connectée : les enceintes pourront réaliser des actions sophistiquées ou discuter avec leurs utilisateurs pendant plusieurs minutes. L'analyse des flux vidéo, pour les caméras de surveillance, va aussi s'améliorer.
Google avait gardé une surprise pour sa conférence d'annonce des Pixel 10 : Gemini, son intelligence artificielle générative, va remplacer Google Assistant. Les enceintes et les téléviseurs connectés vont enfin se moderniser.
Google avait gardé une surprise pour sa conférence d'annonce des Pixel 10 : Gemini, son intelligence artificielle générative, va remplacer Google Assistant. Les enceintes et les téléviseurs connectés vont enfin se moderniser.
OpenAI a annoncé l'arrivée d'un mode enregistrement dans ChatGPT. Disponible sur l'application macOS, ce mode est accessible aux utilisateurs payant un abonnement, depuis le 16 juillet 2025.
OpenAI a annoncé l'arrivée d'un mode enregistrement dans ChatGPT. Disponible sur l'application macOS, ce mode est accessible aux utilisateurs payant un abonnement, depuis le 16 juillet 2025.
Apple rame avec son nouveau Siri. La réglementation européenne pourrait causer un problème supplémentaire à l'entreprise américaine et à ses ambitions dans l'IA générative si la nouvelle version de son assistant vocal n'est pas au niveau.
Apple rame avec son nouveau Siri. La réglementation européenne pourrait causer un problème supplémentaire à l'entreprise américaine et à ses ambitions dans l'IA générative si la nouvelle version de son assistant vocal n'est pas au niveau.
Welcome to the 83rd episode of Decode Quantum, the quantum podcast where we like to get in depth in quantum science and technology. I was this time with Wilhelm Kaenders, the president and CTO of Toptica. Fanny is not there, again, she’s so busy, she’s like a minister, sometimes she has meetings that she can’t […]
Welcome to the 83rd episode of Decode Quantum, the quantum podcast where we like to get in depth in quantum science and technology. I was this time with Wilhelm Kaenders, the president and CTO of Toptica. Fanny is not there, again, she’s so busy, she’s like a minister, sometimes she has meetings that she can’t […]
Le mode « Voice Advanced », initialement réservé aux abonnés payants, peut désormais être utilisé par tous les utilisateurs de ChatGPT. Son raisonnement est moins poussé dans la version gratuite, mais la synthèse vocale est identique.
Le mode « Voice Advanced », initialement réservé aux abonnés payants, peut désormais être utilisé par tous les utilisateurs de ChatGPT. Son raisonnement est moins poussé dans la version gratuite, mais la synthèse vocale est identique.
Amazon a envoyé ce mercredi de mystérieuses invitations pour un événement ce 26 février à New-York. Rien d'officiel, mais tout porte à croire qu'elle présenterait un nouvel Alexa, fonctionnant avec la même technologie que ChatGPT, le LLM.
Amazon a envoyé ce mercredi de mystérieuses invitations pour un événement ce 26 février à New-York. Rien d'officiel, mais tout porte à croire qu'elle présenterait un nouvel Alexa, fonctionnant avec la même technologie que ChatGPT, le LLM.
Les modèles text-to-audio ont fait parler d’eux avant que les modèles text-to-image ne leur volent la vedette. Les recherches pour améliorer les premiers se poursuivent, NVIDIA vient ainsi de dévoiler son “couteau suisse du son” : Fugatto (Foundational Generative Audio Transformer Opus 1). Ce modèle d’IA génère ou transforme des combinaisons de musique, de voix et de sons à partir de texte et d’audio.
Entraîné sur des millions d’échantillons audio, Fugatto est un modèle de fondation qui s’appuie
Les modèles text-to-audio ont fait parler d’eux avant que les modèles text-to-image ne leur volent la vedette. Les recherches pour améliorer les premiers se poursuivent, NVIDIA vient ainsi de dévoiler son “couteau suisse du son” : Fugatto (Foundational Generative Audio Transformer Opus 1). Ce modèle d’IA génère ou transforme des combinaisons de musique, de voix et de sons à partir de texte et d’audio.
Entraîné sur des millions d’échantillons audio, Fugatto est un modèle de fondation qui s’appuie sur les travaux antérieurs de ses créateurs dans des domaines tels que la modélisation de la parole, le vocodage audio et la compréhension audio. Il est le fruit d’un an de travail de cette équipe de chercheurs internationaux, ce qui a d’ailleurs permis de renforcer ses capacités multilingues. La version complète utilise 2,5 milliards de paramètres et a été entraînée sur une banque de systèmes NVIDIA DGX contenant 32 GPU NVIDIA H100 Tensor Core.
Fugatto peut non seulement générer des sons à partir de descriptions textuelles, mais aussi transformer des pistes existantes en ajoutant ou supprimant des éléments, ou encore en modifiant des caractéristiques vocales comme l’accent ou l’émotion. Il peut même permettre aux gens de produire des sons jamais entendus auparavant, comme une trompette qui aboie ou un saxophone qui miaule…
En effet, Fugatto ne se limite pas aux usages conventionnels de l’audio. Grâce à des fonctionnalités comme l’interpolation temporelle, le modèle peut générer des paysages sonores évolutifs. Par exemple, il peut créer un orage se transformant en une aube lumineuse, avec des chants d’oiseaux qui prennent progressivement le relais du tonnerre.
Le modèle utilise une technique appelée ComposableART pour combiner plusieurs instructions vues séparément pendant l’entraînement. Un utilisateur pourrait ainsi demander une voix triste avec un accent français, tout en ajustant précisément l’intensité de ces attributs. Cette capacité donne aux créateurs un contrôle artistique sans précédent, selon Rohan Badlani, chercheur en IA chez NVIDIA : ” Les résultats me donnaient l’impression d’être un artiste, même si je suis informaticien”.
Une palette d’applications potentielles
Fugatto se distingue par sa capacité à répondre à des besoins variés, dans des secteurs aussi divers que la musique, le marketing, l’éducation ou encore le jeu vidéo. Les producteurs pourront expérimenter rapidement différents styles, ajouter ou supprimer des instruments, et même générer des effets sonores inédits. Comme le souligne Ido Zmishlany, producteur multi-platine :
“L’histoire de la musique est aussi une histoire de la technologie. La guitare électrique a donné au monde le rock and roll. Quand le sampler est arrivé, le hip-hop est né. Avec l’IA, nous écrivons le prochain chapitre de la musique. Nous avons un nouvel instrument, un nouvel outil pour faire de la musique – et c’est super excitant”.
Les agences de publicité auront la possibilité d’adapter leurs campagnes en appliquant divers accents et émotions aux voix off, les développeurs de jeux vidéo de créer des ressources audio dynamiques qui s’adaptent à l’action en temps réel. Les outils d’apprentissage des langues pourraient, quant à eux, être enrichis par des voix spécifiques, comme celle d’un ami ou d’un parent.
Lancé en septembre 2024 en dehors de l'Union européenne, le nouveau mode « Avancé » de ChatGPT Voice permet de discuter avec un assistant vocal futuriste qui comprend les émotions, peut les imiter, accepte qu'on lui coupe la parole et peut même faire des accents ou se lancer dans un jeu de rôle. La France y a accès depuis le 22 octobre 2024.
Lancé en septembre 2024 en dehors de l'Union européenne, le nouveau mode « Avancé » de ChatGPT Voice permet de discuter avec un assistant vocal futuriste qui comprend les émotions, peut les imiter, accepte qu'on lui coupe la parole et peut même faire des accents ou se lancer dans un jeu de rôle. La France y a accès depuis le 22 octobre 2024.
Plusieurs mois après l'annonce polémique d'OpenAI, le nouveau ChatGPT Voice, capable de parler, de rire et de blaguer comme un humain, est disponible pour les abonnés ChatGPT Plus. Problème : OpenAI a décidé de bloquer sa sortie dans l'Union européenne, le Royaume-Uni, la Suisse et d'autres pays européens.
Plusieurs mois après l'annonce polémique d'OpenAI, le nouveau ChatGPT Voice, capable de parler, de rire et de blaguer comme un humain, est disponible pour les abonnés ChatGPT Plus. Problème : OpenAI a décidé de bloquer sa sortie dans l'Union européenne, le Royaume-Uni, la Suisse et d'autres pays européens.
Apple ne proposera pas de l'intelligence artificielle, mais de l'intelligence Apple. Derrière un nom pensé pour le marketing, et pour se distinguer des autres, se trouve un net coup d'accélérateur de l'entreprise sur l'IA. Deux éléments le montrent : l'intégration de ChatGPT et la transformation de Siri.
Apple ne proposera pas de l'intelligence artificielle, mais de l'intelligence Apple. Derrière un nom pensé pour le marketing, et pour se distinguer des autres, se trouve un net coup d'accélérateur de l'entreprise sur l'IA. Deux éléments le montrent : l'intégration de ChatGPT et la transformation de Siri.
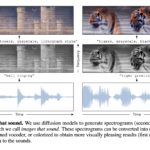
Des chercheurs de l’Université du Michigan ont mis au point une technique absolument dingue qui permet de générer des spectrogrammes ayant l’allure d’images capables de produire des sons qui leur correspondent lorsqu’ils sont écoutés. Ils appellent cela des « images qui sonnent ».
Leur approche est simple et fonctionne sans entraînement spécifique. Elle s’appuie sur des modèles de diffusion text-to-image et text-to-spectrogram pré-entraînés, opérant dans un espace latent partagé. Durant le
Des chercheurs de l’Université du Michigan ont mis au point une technique absolument dingue qui permet de générer des spectrogrammes ayant l’allure d’images capables de produire des sons qui leur correspondent lorsqu’ils sont écoutés. Ils appellent cela des « images qui sonnent ».
Leur approche est simple et fonctionne sans entraînement spécifique. Elle s’appuie sur des modèles de diffusion text-to-image et text-to-spectrogram pré-entraînés, opérant dans un espace latent partagé. Durant le processus de génération, les deux modèles « débruitent » des latents partagés de manière simultanée, guidés par deux textes décrivant l’image et le son désirés.
Le résultat est bluffant ! Ça donne des spectrogrammes qui, vus comme des images, ressemblent à un château avec des tours, et écoutés comme des sons, font entendre des cloches. Ou des tigres dont les rayures cachent les motifs sonores de leurs rugissements.
Pour évaluer leur bidouille, les chercheurs ont utilisé des métriques quantitatives comme CLIP et CLAP, ainsi que des études de perception humaine. Leur méthode dépasse les approches alternatives et génère des échantillons qui collent finement aux prompts textuels dans les deux modalités. Ils montrent aussi que coloriser les spectrogrammes donne des images plus agréables à l’œil, tout en préservant l’audio.
Cette prouesse révèle qu’il existe une intersection entre la distribution des images et celle des spectrogrammes audio et en dépit de leurs différences, ils partagent des caractéristiques bas niveau comme les contours, les courbes et les coins. Cela permet de composer de façon inattendue des éléments visuels ET acoustiques, comme une ligne qui marque à la fois l’attaque d’un son de cloche et le contour d’un clocher.
Les auteurs y voient une avancée pour la génération multimodale par composition et une nouvelle forme d’expression artistique audio-visuelle. Une sorte de stéganographie qui cacherait des images dans une piste son, dévoilées uniquement lorsqu’elles sont transformées en spectrogramme.
Pour recréer cette méthode chez vous, il « suffit » d’aller sur le Github du projet et de suivre les instructions techniques.
Vibe est un nouvel outil open source de transcription audio multilingue qui va vous faire vibrer ! Terminé le temps où vous deviez vous contenter de sous-titres approximatifs ou attendre des plombes pour obtenir une transcription potable.
Pour cela, il utilise l’IA Whisper, développé par les génies d’OpenAI et dont je vous ai parlé à maintes reprises. Ce modèle de reconnaissance vocale dernier cri est capable de transcrire un nombre ahurissant de langues avec une précision bluffante, ce qui
Vibe est un nouvel outil open source de transcription audio multilingue qui va vous faire vibrer ! Terminé le temps où vous deviez vous contenter de sous-titres approximatifs ou attendre des plombes pour obtenir une transcription potable.
Pour cela, il utilise l’IA Whisper, développé par les génies d’OpenAI et dont je vous ai parlé à maintes reprises. Ce modèle de reconnaissance vocale dernier cri est capable de transcrire un nombre ahurissant de langues avec une précision bluffante, ce qui permet de faire de Vibe une véritable solution audio polyvalente bourrée de fonctionnalités.
Vous pouvez par exemple transcrire des fichiers audio et vidéo par lots, prévisualiser le résultat en temps réel, exporter dans une flopée de formats (SRT, VTT, TXT…), et même personnaliser les modèles selon vos besoins. Il fonctionne entièrement hors ligne, donc pas de risque que vos données sensibles se retrouvent dans les griffes des GAFAM et ça tourne sous macOS, Windows et Linux. Pour cela, il vous suffit de vous rendre sur la page des releases GitHub et de télécharger la version qui correspond à votre OS.
Le support pour Apple Silicon est optimisé ce qui offre une performance accrue et pour Windows, la version 8 ou plus sera nécessaire, mais bon, je pense que vous êtes tous ou presque déjà sous Windows 10/11. Les utilisateurs Linux, quand à eux, peuvent installer Vibe via un fichier .deb, et les utilisateurs d’Arch Linux peuvent utiliser debtap pour convertir le paquet en fonction de leurs besoins.
Côté performance, c’est du gâteau puisque comme vous vous en doutiez, les ordinateurs Mac ont droit à une petite optimisation GPU qui booste les résultats. Mais même sur un vieux coucou Windows, Vibe est capable de s’adapter à vos ressources sans broncher via à ses réglages avancés. Et pour les Linuxiens, sachez que le support de l’audio système et du micro est prévu pour bientôt.
Bref, c’est à tester si vous êtes dans le business du sous-titre ou de la transcription.
L'entreprise a dévoilé un assistant vocal, au comportement très humain, qui a immédiatement fait penser au film Her. L'une des voix féminines proposées par OpenAI a été retirée, a annoncé l'entreprise, car elle ressemblait trop à celle de l'actrice Scarlett Johansson.
L'entreprise a dévoilé un assistant vocal, au comportement très humain, qui a immédiatement fait penser au film Her. L'une des voix féminines proposées par OpenAI a été retirée, a annoncé l'entreprise, car elle ressemblait trop à celle de l'actrice Scarlett Johansson.