La Chine aurait autorisé la start-up d'IA chinoise DeepSeek a acquérir des puces H200 de Nvidia, selon un article de Reuters daté du 28 janvier 2026. En parallèle, ByteDance, Alibaba et Tencent auraient également reçu une autorisation similaire, pour plus de 400 000 GPU H200.
Coup de théâtre dans la guerre des semi-conducteurs : Donald Trump a donné le 8 décembre 2025 son feu vert à l’exportation des H200 de Nvidia vers la Chine. Une ouverture inattendue, qui pourrait bien rebattre les cartes pour les deux camps.
Alors que l’administration Biden a dévoilé début décembre de nouvelles restrictions visant à limiter l’accès de la Chine à certaines technologies de pointe, notamment les puces d’IA, elle a présenté hier, une semaine avant de céder la place à Donald Trump, un projet de réglementation visant à bloquer les exportations de ces puces vers la Chine, la Russie, l’Iran et la Corée du Nord. Leur accès à ses principaux alliés, dont la France, sera également soumise à certaines conditions, soulevant le tollé chez les acteurs de l’IA, notamment chez NVIDIA.
Sous couvert de sécurité nationale, les Etats-Unis, pour préserver leur position prédominante dans la course à l’IA, ont mis en place des restrictions vers l’exportation des GPU et des puces d’accélération d’IA vers la Chine, son principal concurrent, et la Russie dès 2022, introduisant des exigences plus strictes pour l’octroi de licences pour les exportations vers la Chine et d’autres pays en 2023.
Ils pourraient franchir un nouveau pas avec cette nouvelle réglementation, que critique Ned Finkle, vice-président des affaires gouvernementales chez NVIDIA. Il affirme dans un billet de blog où il rappelle l’apport de l’IA pour les soins de santé, l’agriculture, la fabrication, l’éducation, entre autres :
“L’administration Biden cherche maintenant à restreindre l’accès aux applications informatiques grand public avec sa règle sans précédent et erronée de « diffusion de l’IA », qui menace de faire dérailler l’innovation et la croissance économique dans le monde entier”.
Que stipule la réglementation provisoire ?
La réglementation provisoire, présentée par la Maison-Blanche, introduit une série de mesures destinées à encadrer strictement la diffusion des technologies d’IA avancées, tout en préservant les intérêts économiques et stratégiques des États-Unis.
Blocage des exportations vers les pays de préoccupation
Les exportations de puces avancées seront strictement interdites vers la Chine, la Russie, l’Iran et la Corée du Nord. Ces pays, considérés comme des adversaires stratégiques, sont ciblés pour empêcher l’utilisation de ces technologies à des fins militaires, cybernétiques ou de surveillance de masse.
Aucune restriction pour les alliés
Les 18 principaux alliés des États-Unis, parmi lesquels la France, l’Allemagne, la Belgique, le Danemark, l’Irlande, l’Italie, l’Espagne, le Royaume-Uni, la Suède, le Japon, la Corée du Sud et Taïwan, pourront continuer à importer ces technologies, mais sous réserve de répondre à des critères de sécurité stricts et d’obtenir des licences pour les commandes de grande envergure.
Deux statuts ont été créés pour encadrer les exportations vers les utilisateurs finaux :
Universal Verified End User (UVEU) : Ce statut permettra aux entreprises situées dans des pays alliés et respectant des normes de sécurité élevées de bénéficier de livraisons flexibles pour leurs besoins en IA. Elles ne pourront toutefois déployer que 7% de leur capacité de calcul dans chaque pays tiers ;
National Verified End User (NVEU) : Accordé aux entreprises des pays considérés comme non-préoccupants qui pourront acheter jusqu’à 320 000 GPU avancés sur deux ans, tout en respectant les exigences de sécurité.
Les entités non-VEU pourront quant à elles acheter jusqu’à 50 000 GPU avancés par pays, un nombre qui pourra être doublé en cas d’accord signé avec les États-Unis.
Exemptions pour les petites commandes de puces
Les commandes de puces dont la capacité de calcul collective ne dépasse pas 1 700 GPU avancé ne nécessiteront pas de licence et ne seront pas comptabilisées pas dans les plafonds nationaux. Ces exemptions concernent principalement des institutions universitaires, médicales et de recherche qui utilisent ces technologies à des fins non-sensibles et pourront ainsi les recevoir rapidement.
Encadrement des modèles d’IA avancés
Les poids de modèles fermés ne pourront être transférés qu’à des acteurs vérifiés, tandis que des normes de sécurité accrue sont imposées pour leur stockage.
Cette réglementation pourrait entrer en vigueur d’ici 120 jours, reste à savoir ce qu’en fera le gouvernement Trump, soutenu par les acteurs de la Silicon Valley.
Pour Ned Finkle :
“Elle sape déjà les intérêts des États-Unis. Comme l’a démontré la première administration Trump, l’Amérique gagne grâce à l’innovation, à la concurrence et au partage de nos technologies avec le monde – et non en se retirant derrière un mur d’excès de pouvoir gouvernemental. Nous attendons avec impatience un retour à des politiques qui renforcent le leadership américain, stimulent notre économie et préservent notre avantage concurrentiel dans le domaine de l’IA et au-delà”.
L’évolution rapide de l’IA a ouvert la voie à des avancées impressionnantes dans le domaine de la conception des puces électroniques, l’approche développée par Google DeepMind en est un exemple concret. Lancée en 2020, désormais baptisée AlphaChip, elle utilise l’apprentissage par renforcement pour optimiser la disposition des composants des puces, réduisant le temps de conception de quelques mois à seulement quelques heures. DeepMind a partagé la semaine dernière sur son blog des détails supplémentaires sur ce framework open source.
AlphaChip aborde la conception des puces comme un jeu. À partir d’une grille vide, l’IA place les composants des circuits un par un, tout en respectant les contraintes de conception complexes telles que les connexions entre les composants et l’optimisation de l’espace. À chaque disposition générée, le modèle apprend et s’améliore, ce qui permet de produire des puces de plus en plus performantes. L’utilisation d’un réseau neuronal spécialisé, un graphe basé sur les bords, aide AlphaChip à comprendre les relations entre les différents blocs de puces, améliorant ainsi la qualité et la rapidité des conceptions.
Selon Deepmind, “ses dispositions sont utilisées dans les puces du monde entier, des centres de données aux téléphones mobiles”.
Depuis sa publication en 2020, il a été utilisé pour concevoir plusieurs générations des unités de traitement tensoriel (TPU), introduites en 2016 par Google Cloud pour accélérer les tâches d’IA, qui font fonctionner aujourd’hui les LLM de Google comme Gemini.
AlphaChip a non seulement optimisé la disposition des composants des TPU, rendant chaque génération plus performante que la précédente, mais a également fourni à chacune d’elle, une plus grande partie de l’ensemble de l’étage, accélérant le cycle de conception.
Crédit image : Google. Graphique à barres montrant le nombre de blocs de puces conçus par AlphaChip sur trois générations d’unités de traitement tensoriel (TPU) de Google : v5e, v5p et Trillium.
Des entreprises comme MediaTek utilisent également AlphaChip pour concevoir des puces comme la série Dimensity 5G, utilisée dans les smartphones de pointe, ce qui lui a permis d’améliorer à la fois les performances et l’efficacité énergétique de ses puces.
Vers un futur plus efficace et durable
Aujourd’hui, AlphaChip optimise non seulement la disposition des puces, mais aussi d’autres étapes du cycle de conception, comme la synthèse logique et l’optimisation des timings. Il pourrait dans le futur transformer radicalement la conception des puces pour des appareils aussi variés que les smartphones, les capteurs agricoles ou encore les équipements médicaux, en améliorant chaque étape du cycle.
DeepMind conclut :
“Les futures versions d’AlphaChip sont en cours de développement et nous sommes impatients de travailler avec la communauté pour continuer à révolutionner ce domaine et créer un avenir dans lequel les puces sont encore plus rapides, moins chères et plus économes en énergie”.
AlphaChip : comment l'IA de Deepmind redéfinit les normes de la conception des puces
Fin octobre dernier, Apple présentait le même jour trois puces destinées à ses ordinateurs, les M3, M3 Pro et M3 Max. Alors qu’elle a débuté le lancement des premiers Mac équipés de ces puces, elle s’apprêterait, selon le journaliste Mark Gurman de Bloomberg, à produire les M4 destinées à équiper l’ensemble de sa gamme.
Apple a commencé à produire ses propres puces, les M1, en 2020, délaissant les processeurs d’Intel. Les M3 ont été les premières puces d’ordinateur personnel élaborées à partir du procédé de gravure en 3 nanomètres de TSMC, ce qui leur permet de renfermer davantage de transistors dans un format plus petit pour une rapidité et une efficacité accrues. Leur Neural Engine était présenté par Apple comme “un moteur sur mesure pour l’IA et la vidéo”.
Johny Srouji, Senior Vice President of Hardware Technologies d’Apple, déclarait lors de leur annonce :
“La puce Apple a complètement redéfini l’expérience Mac. Chaque aspect de son architecture est conçu pour optimiser les performances et l’efficacité énergétique. Avec la technologie en 3 nanomètres, une architecture GPU de nouvelle génération, un CPU plus performant, un Neural Engine plus rapide, et plus de mémoire unifiée, les puces M3, M3 Pro et M3 Max sont les plus avancées à ce jour pour un ordinateur personnel”.
Elles équipent le MacBook Pro, le MacBook Air et l’iMac.
La prochaine génération de puces d’APPLE
Selon Mark Gurman, la puce M4 disposera d’un Neural Engine encore plus rapide et de plus de mémoire pour les tâches d’IA et de machine learning. Elle se déclinera en 4 versions : celle de base, appelée en interne Donan, la M4 Pro baptisée Brava, la M4 Max plus performante et pour finir, encore plus puissante, Hidra, la M4 Ultra qui équipera l’ordinateur de bureau haut de gamme d’Apple, le Mac Pro, fin 2025. Celui-ci pourrait ainsi bénéficier d’une RAM de 512 Go.
Les premiers Mac à être livrés avec la puce M4 seront le MacBook Pro 14 pouces bas de gamme et l’iMac 24 pouces, prévus pour la fin de cette année. Les nouveaux MacBook Pro haut de gamme 14 pouces et 16 pouces intégrant les puces M4 Max sont attendus entre fin 2024 et début 2025 tout comme le Mac mini. Les nouveaux MacBook Air 13 pouces et 15 pouces sont quant à eux prévus pour le printemps 2025.
Ce calendrier peut évidemment évoluer, Apple apportera plus de précisions sur sa puce M4 lors de sa conférence annuelle, la Worldwide Developers Conference (WWDC) le 10 juin prochain. L’IA y tiendra une place centrale non seulement pour les Mac mais également pour ses iphones puisque Mark Gurman dans sa newsletter d’hier, évoquant la mise à jour d’iOS 18, écrit : “alors que le monde entier attend la grande présentation de l’IA d’Apple le 10 juin, il semble que la première vague de fonctionnalités fonctionnera entièrement sur l’appareil”.
Apple les premiers MacBook Pro équipés de puces M4 seraient prévus pour la fin de l'année
Les GAFAM ou GAMAM (Google, Apple, Facebook (Meta), Amazon, Microsoft) portés par l’essor de l’IA générative, connaissent une croissance importante de leur capitalisation boursière tout comme NVIDIA. Alphabet, la maison mère de Google, a ce vendredi 12 avril franchi pour la seconde fois de son existence le cap des 2 billions de dollars, se retrouvant ainsi la 4ème entreprise la plus valorisée au monde.
Alors que la valorisation de NVIDIA portée par la demande de puces ne cesse de grimper, les 5 GAFAM ont également vu la leur augmenter significativement l’an passé et en ce début 2024.
En mai 2023, Apple était l’entreprise la plus valorisée devant Microsoft, suivie par Saudi Aramco, une société pétrolière saoudienne, Alphabet et Amazon. Alors que l’inflation leur était favorable, l’appétit des investisseurs pour la GenAI et la demande de puces avaient quelque peu modifié ce classement : Microsoft, principal investisseur d’OpenAI, s’est installé en 1ère place et NVIDIA est venu s’immiscer en 3ème position devant Saudi Aramco.
Vendredi dernier, le classement a de nouveau évolué : Saudi Aramco s’est vu relégué à la sixième place par Alphabet et Amazon. Si Microsoft semblait inatteignable avec une valorisation de plus de 3 billions (3000 milliards de dollars), celle d’Apple était de 2,7 billions.
Les perspectives optimistes d’août 2023 pour NVIDIA, boosté par les ventes du H100, son GPU pour datacenters, se sont avérées justes : l’entreprise s’est retrouvée en 3ème place du top 5 avec une valorisation de plus de 2,2 billions. Alphabet, qui, pendant un moment a lui aussi dépassé le seuil des 2 000 milliards de dollars comme il l’avait éphémèrement fait en novembre 2021, est redescendu aux alentours de 1,990 billions tandis qu’Amazon était valorisé à plus de 1,966 billions.
Google (Alphabet) avait quelque peu raté la présentation de son modèle phare Gemini fin décembre dernier et vu ses actions chuter rapidement. La société a cependant su regagner la confiance des investisseurs la semaine dernière lors de Google Cloud Next où elle a notamment dévoilé son CPU Axion.
Les puces de NVIDIA, notamment le GPU H100, sont les plus utilisées que ce soit pour les datacenters, les supercalculateurs, l’entraînement ou l’inférence des LLM. Lors de la GTC 2024, qui a réuni Jensen Huang, fondateur et PDG de NVIDIA, a présenté des GPU qui devraient apporter encore plus de puissance de calcul : la puce “la plus puissante au monde pour l’IA” Blackwell B200 basée sur une nouvelle architecture et la super puce GB200, qui combinera les architectures Grace et Blackwell.
Nommée en l’honneur de David Harold Blackwell, mathématicien de l’Université de Californie à Berkeley spécialisé dans la théorie des jeux et les statistiques, et premier chercheur noir intronisé à l’Académie nationale des sciences, la nouvelle architecture succède à l’architecture NVIDIA Hopper, lancée il y a deux ans.
Elle comprend, selon NVIDIA, six technologies transformatrices pour l’informatique accélérée, qui contribueront à débloquer des percées dans le traitement des données, la simulation d’ingénierie, l’automatisation de la conception électronique, la conception de médicaments assistée par ordinateur, l’informatique quantique et l’IA générative, autant d’opportunités industrielles émergentes pour NVIDIA.
Outre les puces Blackwell, elle dispose notamment d’un moteur de transformateur de deuxième génération : alimentée par une nouvelle prise en charge de la mise à l’échelle des micro-tenseurs et les algorithmes avancés de gestion de la plage dynamique de NVIDIA intégrés aux frameworks NVIDIA TensorRT-LLM et NeMo Megatron, Blackwell prendra en charge le double de la taille des calculs et des modèles avec de nouvelles capacités d’inférence IA en virgule flottante 4 bits.
Un NVLink de cinquième génération permet d’accélérer les performances des modèles d’IA de plusieurs billions de paramètres grâce à un débit bidirectionnel de 1,8 To/s par GPU, garantissant une communication haut débit transparente entre jusqu’à 576 GPU pour les LLM les plus complexes.
Crédit Nvidia
Blackwell multiplie les performances de Hopper par 2,5 en FP8 pour l’entraînement, par puce et par 5 avec FP4 pour l’inférence.
Lors de son discours d’ouverture, Jensen Huang affirmait:
“Pendant trois décennies, nous avons poursuivi l’informatique accélérée, dans le but de permettre des percées transformatrices telles que l’apprentissage profond et l’IA. L’IA générative est la technologie déterminante de notre époque. Blackwell est le moteur de cette nouvelle révolution industrielle. En travaillant avec les entreprises les plus dynamiques au monde, nous réaliserons les promesses de l’IA pour tous les secteurs”.
Le GPU B200 et la superpuce GB200
Comptant deux cœurs de processeur, chacun comportant 104 milliards de transistors, les GPU d’architecture Blackwell sont fabriqués à l’aide d’un processus TSMC 4NP sur mesure avec des puces GPU limitées à deux réticules connectées par une liaison puce à puce de 10 To/seconde formant ainsi un seul GPU unifié. Tout comme les GH200 Grace Hopper, les B200 sont dotés de mémoire HBM3e, (192 pour ces derniers contre 282 Go pour le GH200),qui permet de gérer les charges de travail d’IA générative les plus complexes, allant des grands modèles linguistiques aux systèmes de recommandation et aux bases de données vectorielles. La bande passante mémoire est de 8 To/s.
Crédit NVIDIA : à gauche GB200, à droite le gpu H100
La superpuce GB200 connecte deux de ces GPU B200 à un processeur Grace, via une interconnexion puce-puce NVLink ultra-basse consommation de 900 Go/s, pour offrir des performances 30 fois supérieures pour les calculs d’inférence. Selon Jensen Huang, la formation d’un modèle de 1 800 milliards de paramètres aurait auparavant nécessité 8 000 GPU Hopper et 15 mégawatts de puissance, 2 000 GPU Blackwell permettent de le faire en ne consommant que quatre mégawatts.
Le GB200 serait également 25 fois plus performant en matière d’efficacité énergétique que le H 100.
Crédit NVIDIA Le GB200 NVL72
Le GB200 est un composant clé du NVIDIA GB200 NVL72, un système multi-nœuds, refroidi par liquide et à l’échelle du rack pour les charges de travail les plus gourmandes en ressources de calcul. Il combine 36 superpuces Grace Blackwell, dont 72 GPU Blackwell et 36 CPU Grace interconnectés par le NVLink de cinquième génération. Grâce à lui, l’inférence d’un LLM de mille milliards de paramètres serait 30 fois plus rapide.
GTC 2024 NVIDIA dévoile le GPU Blackwell B200 et la super puce GB200
Après Sam Altman, c’est au tour de Masayoshi Son, fondateur et PDG de SoftBank de partir à la recherche de fonds pour créer sa propre entreprise de fabrication de puces de pointe nécessaires à l’IA générative, un marché très lucratif dominé par NVIDIA, qu’AMD s’efforce de rattraper avec l’Instinct MI300X. Pour ce projet baptisé Izanagi d’un montant de 100 milliards de dollars, Masayoshi Son en cherche 70 auprès d’investisseurs du Moyen-Orient.
Après des pertes de 27,4 milliards de dollars annoncés en 2022, Masayoshi Son, s’était quelque peu retranché dans le silence. Le Vision Fund qu’il a créé en 2017 a réduit considérablement ses investissements, des actions d’Alibaba qui lui a permis de faire fortune ont été revendues et, malgré des pertes de 32 milliards affichées en 2023, le milliardaire se disait en juin dernier prêt à rebondir et à investir dans l’IA.
Il déclarait :
“Nous sommes prêts à passer en mode offensif, je veux que SoftBank mène la révolution de l’IA”.
Durant la période en mode défense, durant laquelle la société a amassé plus de 35 milliards de dollars de liquidités, il s’était consacré à la réintroduction en bourse d’ARM, société acquise par SoftBank en 2016 pour 32 milliards de dollars. Entrée en bourse le 14 septembre dernier réussie puisque la société de semi-conducteurs a vu sa valeur grimper à 65 milliards de dollars et plus que doubler depuis.
SoftBank était d’ailleurs prêt en 2020 à céder Arm à Nvidia mais ce dernier a dû renoncer à l’acquisition en 2022 face aux obstacles réglementaires et à l’opposition de la concurrence. Il a toutefois annoncé en décembre dernier un investissement de 147,3 millions de dollars dans le fabricant des processeurs qui complètent ses puces dans les centres de données.
SoftBank a pour projet aujourd’hui de fabriquer lui aussi des puces d’IA en collaboration avec sa filiale Arm. Il va y consacrer 30 des milliards de dollars engrangés et espère collecter le reste afin de se tailler une place de choix dans ce marché des puces estimé à plus de 1000 milliards de dollars à l’horizon 2030.
SoftBank, à la recherche d'investisseurs pour se lancer dans la fabrication de puces d'IA
Cela fait près d’un an qu’OpenAI, la start-up derrière ChatGPT, face à la pénurie et au coût des puces nécessaires pour alimenter ses projets, prévoit de fabriquer ses propres puces d’IA. Avant son éviction temporaire de la société, Sam Altman aurait approché plusieurs investisseurs dans l’objectif de mettre en place un réseau mondial d’usines de fabrication de semi-conducteurs, projet relancé selon un rapport récent de Bloomberg.
Confronté à la pénurie de puces mais aussi à une totale dépendance à des fournisseurs comme NVIDIA ou AMD, Microsoft, le principal investisseur d’OpenAI, s’est lancé en novembre dernier dans le développement de ses propres puces d’IA pour Azure, OpenAI avait d’ailleurs collaboré avec lui pour affiner la puce MAIA et la tester avec ses modèles.
OpenAI n’a pas les moyens de Microsoft, développer ses propres puces d’IA serait pour lui une entreprise complexe, coûteuse et très risquée qui nécessiterait plusieurs années pour être mise en œuvre. La société a donc opté pour une collaboration avec d’importants acteurs du secteur des semi-conducteurs, Intel, Taiwan Semiconductor Manufacturing Company (TSMC), le principal fournisseur de puces de NVIDIA, et Samsung seraient, entre autres, de potentiels partenaires.
Ce projet, auquel s’intéresserait Microsoft, permettrait à OpenAI de s’assurer d’un approvisionnement certain pour le développement de ses IA génératives, mais également d’étendre ses capacités technologiques et de forger des partenariats stratégiques. Pour le concrétiser, Sam Altman s’est lancé dans une quête active de financement et serait en discussions avec des investisseurs majeurs, dont G42 et SoftBank, pour lever entre 8 et 10 milliards de dollars.



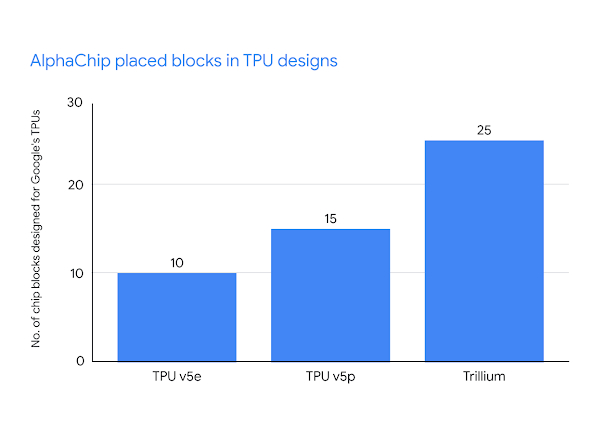 Crédit image : Google. Graphique à barres montrant le nombre de blocs de puces conçus par AlphaChip sur trois générations d’unités de traitement tensoriel (TPU) de Google : v5e, v5p et Trillium.
Crédit image : Google. Graphique à barres montrant le nombre de blocs de puces conçus par AlphaChip sur trois générations d’unités de traitement tensoriel (TPU) de Google : v5e, v5p et Trillium.







