Comment les Systèmes Multi-Agents réinventent l’intelligence artificielle
L’évolution de l’informatique moderne repose sur la gestion de données. Ces volumes deviennent de plus en plus massifs et complexes. Les architectures logicielles centralisées historiques peinent désormais à répondre à ces besoins de flexibilité. C’est dans ce contexte de transition numérique que s’inscrivent les Systèmes Multi-Agents comme une alternative majeure.
Ce paradigme déplace la logique algorithmique vers un réseau d’entités interconnectées. Chaque composant autonome participe activement à l’effort collectif. Cet article explore en profondeur les fondements et l’histoire de cette technologie. Il analyse également ses architectures ainsi que ses applications industrielles.
Les fondements de l’intelligence artificielle distribuée
Les architectures informatiques traditionnelles reposent sur un modèle monolithique. Un serveur central y prend les décisions et exécute les tâches de manière séquentielle. Cette centralisation se heurte vite à des limites physiques, comme la saturation de la mémoire. Les goulets d’étranglement qui en résultent ralentissent les performances et bloquent le traitement des données massives.
Pour dépasser ces limites, la recherche a développé l’Intelligence Artificielle Distribuée (IAD). Ce modèle fragmente le problème initial pour répartir le calcul sur plusieurs machines. La décision n’appartient plus à une entité unique, mais devient le fruit d’un effort partagé. Cette décentralisation améliore la réactivité en temps réel et rend les systèmes plus flexibles.
L’IAD mise sur l’émergence pour faire naître une intelligence collective. À l’image d’une colonie de fourmis, chaque individu suit des règles simples sans dépendre d’un chef central. Leurs interactions dans un espace partagé génèrent un comportement de groupe complexe. Cette synergie permet de résoudre des défis logistiques ou mathématiques, le système global devenant souvent plus performant que chacun de ses composants.
Définition et piliers fondamentaux des Systèmes Multi-Agents
L’agent informatique est la brique de base de ce modèle distribué. Qu’il soit un logiciel ou un robot physique, il possède ses propres objectifs et une autonomie relative. Il analyse sa situation et agit sans attendre d’ordres permanents. Ses capteurs perçoivent son milieu et ses actionneurs le modifient selon un cycle continu : perception, délibération, action.
Les agents coexistent dans un environnement partagé, virtuel comme internet ou physique comme un entrepôt. Cet espace dynamique leur impose des contraintes qui limitent leurs actions ou leurs calculs. Il évolue sous l’effet de leurs comportements et d’événements extérieurs. Ce milieu permet aussi une communication indirecte, la stigmergie, où les agents s’adaptent en observant les traces de leurs pairs.
Pour éviter le chaos, une organisation collective structure le réseau. Elle définit les rôles de chacun, attribue les responsabilités et fixe l’accès aux ressources communes. Des règles et des protocoles encadrent les échanges afin de prévenir les blocages. Ce cadre pilote la répartition des tâches, garantissant la cohérence et la stabilité des décisions globales.
Architecture interne et typologie d’un agent autonome
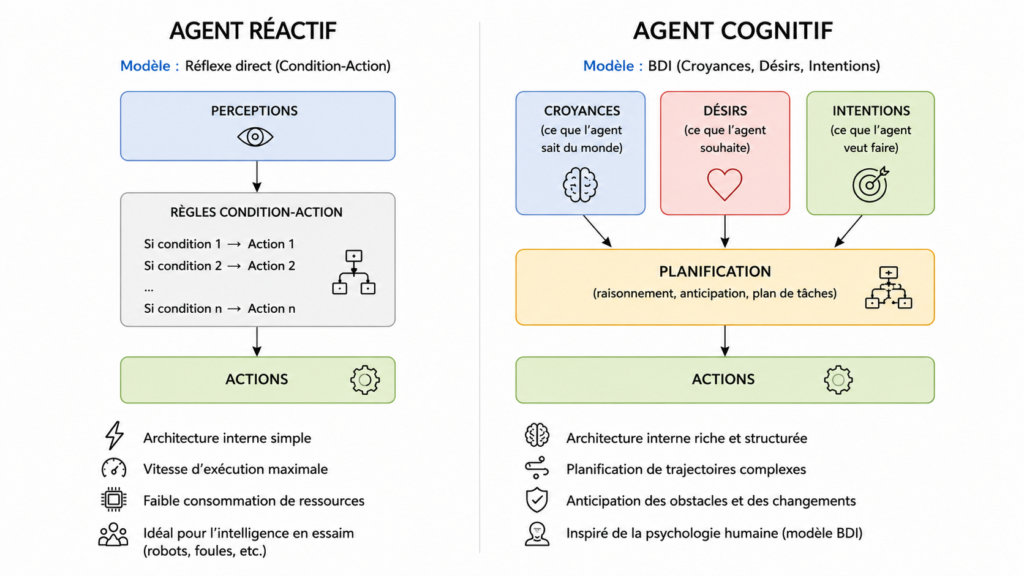
Les agents réactifs possèdent l’architecture interne la plus simple. Leur comportement repose entièrement sur un modèle réflexe direct. Ils associent une perception immédiate à une action selon une logique de type « Condition-Action« . Ces entités ne possèdent qu’une mémoire très limitée pour modéliser l’avenir.
Cette simplicité logicielle garantit une vitesse d’exécution maximale. Les agents consomment également très peu de ressources informatiques. Ce modèle permet de simuler efficacement les principes de l’intelligence en essaim. Il sert ainsi à coordonner des flottes de robots ou des foules urbaines.
À l’opposé, les agents cognitifs disposent d’une structure interne beaucoup plus riche. Ils s’appuient sur le modèle logique BDI inspiré de la psychologie humaine. Cette architecture articule explicitement les croyances, les désirs et les intentions de l’entité. Ce fonctionnement permet de planifier des trajectoires complexes et d’anticiper les obstacles.
Mécanismes d’interaction au sein des Systèmes Multi-Agents
La collaboration entre agents exige un langage commun pour éviter les malentendus. La fondation FIPA a créé des normes internationales pour répondre à ce défi. Le standard FIPA-ACL est aujourd’hui un langage de communication largement utilisé. Ce protocole permet à des entités hétérogènes d’échanger des informations de façon structurée.
Chaque message FIPA-ACL contient des champs obligatoires qui organisent la discussion. Il indique l’émetteur, le récepteur et un contenu précis. Son élément clé est le « performatif », qui définit l’intention du message, comme une question ou une offre. Grâce à cette structure, l’agent comprend mieux l’objectif de son interlocuteur.
Pour répartir le travail, les agents utilisent des protocoles de négociation comme le filet de contrats. Un agent émetteur publie un appel d’offres décrivant une tâche et ses contraintes. Les autres agents évaluent leurs capacités avant de soumettre une proposition. L’émetteur choisit l’offre la plus adaptée, facilitant une gestion efficace sans intervention humaine.
Historique et grandes étapes de l’évolution des agents
Les bases de la discipline naissent dans les années 1970. En 1973, Carl Hewitt introduit le modèle d’Acteurs, où des entités autonomes communiquent par messages. Ce concept pose les jalons du calcul parallèle et distribué. En parallèle, le Jeu de la vie (Game of Life) de John Conway prouve que des règles locales simples peuvent générer une dynamique collective complexe.
Les années 1980 ouvrent l’ère de l’intelligence artificielle distribuée appliquée. La recherche développe alors les systèmes à base de « Tableau Noir ». Le projet de reconnaissance vocale HEARSAY-II valide cette architecture en faisant collaborer plusieurs modules sur une mémoire partagée. Cette innovation démontre concrètement l’intérêt du travail d’équipe entre composants logiciels.
Entre 1990 et 2000, la technologie se structure et s’industrialise. Rao et Georgeff formalisent l’architecture BDI en 1991 pour modéliser le raisonnement. La fondation FIPA standardise ensuite les langages de communication en 1996, avant que le framework JADE ne devienne une référence des développeurs. Les entreprises s’emparent alors de ces outils pour automatiser le commerce en ligne et la logistique.
Apports et avantages concurrentiels des Systèmes Multi-Agents
La décentralisation améliore la résilience informatique. Les architectures classiques dépendent souvent d’un point de contrôle unique sujet aux pannes générales. Les modèles distribués réduisent ce risque critique. La défaillance d’un agent isolé n’interrompt pas le fonctionnement global du système.
Le système peut ainsi afficher des capacités d’auto-guérison. Lorsqu’un agent s’arrête, ses voisins détectent aussitôt son absence. Ils se répartissent de manière autonome ses tâches en cours de traitement. Les protocoles de négociation réajustent le réseau pour sécuriser les infrastructures critiques.
Ce modèle excelle également en matière de scalabilité et de flexibilité. L’ajout d’un nouvel agent ne nécessite aucune réécriture du code source global. La nouvelle entité se connecte à l’environnement, s’enregistre et communique aussitôt. Cette modularité permet d’ajuster la taille du système en temps réel.
Domaines d’application industriels et cas d’usage réels
Les réseaux électriques modernes intègrent des énergies renouvelables intermittentes, comme le solaire ou l’éolien. Les infrastructures classiques peinent à gérer cette instabilité. Pour y remédier, les réseaux intelligents (Smart Grids) peuvent déployer des architectures multi-agents. Chaque producteur et consommateur dispose ainsi de son propre agent logiciel autonome.
Ces programmes évaluent en temps réel la production locale et la demande prévisible. Ils négocient ensuite les prix de l’électricité sur des marchés de proximité. Si l’offre baisse, les agents réduisent automatiquement la consommation des équipements non prioritaires. Cette régulation fine protège les lignes des surcharges et prévient les pannes en cascade.
La robotique collaborative applique des principes proches dans les entrepôts du commerce électronique. Des flottes de robots mobiles s’y déplacent de manière autonome pour transporter les marchandises. Les machines négocient leur passage aux intersections sans dépendre d’un serveur central. Elles adaptent leur itinéraire face aux obstacles, ce qui fluidifie les commandes et réduit les collisions.
L’état de l’art : la révolution des Multi-Agent Systems à l’ère des LLM
L’intégration des modèles de langage transforme l’architecture des agents. Les concepteurs n’ont plus à programmer chaque règle logique à la main. Le LLM sert désormais de moteur de raisonnement principal pour l’entité. L’agent comprend les instructions naturelles et planifie ses actions.
Pour accomplir une mission complexe, l’agent suit une boucle continue. Il décompose l’objectif en sous-tâches et choisit les outils adaptés. L’entité analyse ensuite ses propres résultats à chaque étape intermédiaire. Si le rendu est insatisfaisant, il corrige sa stratégie de manière autonome.
Cette agilité permet de déployer ces technologies en entreprise. Les organisations automatisent ainsi des processus métiers de bout en bout. En ingénierie logicielle, des agents architectes, codeurs et testeurs collaborent en continu. Cette coopération autonome réduit les tâches manuelles et les coûts.
Frameworks modernes et outils d’orchestration actuels
Le marché du développement Python s’articule aujourd’hui autour de deux outils clés. Le framework open-source LangGraph modélise les interactions sous forme de graphes cycliques. Il offre un contrôle sur l’état à chaque étape de calcul. À l’inverse, CrewAI adopte une approche axée sur des rôles métiers.
Ce framework organise les agents comme les membres d’une équipe opérationnelle. Il attribue et gère leurs tâches de manière séquentielle ou parallèle. Au-delà de ces choix techniques, faire communiquer des systèmes différents reste un défi majeur. Le Model Context Protocol (MCP) apporte une réponse standardisée à ce problème.
Ce protocole ouvert définit la manière dont un agent expose ses outils et ses données. Il sert d’interface entre l’intelligence artificielle et les systèmes d’information. Des applications issues de plateformes hétérogènes peuvent enfin collaborer. Ce standard aide à briser les silos technologiques et à relier des écosystèmes variés.
Défis techniques et verrous de sécurité des Systèmes Multi-Agents
Le déploiement industriel de ces architectures fait face à de réelles contraintes économiques. Les agents basés sur des modèles de langage consomment beaucoup de jetons. Lors des phases de négociation, les requêtes se multiplient et font rapidement grimper la facture. Cette communication intense pèse lourdement sur les budgets des entreprises.
La latence est un autre obstacle majeur. Les débats et les vérifications croisées entre agents ralentissent la décision finale. Plusieurs minutes peuvent ainsi s’écouler avant de résoudre un problème complexe. Des outils d’observabilité sont donc indispensables pour surveiller le réseau et limiter les boucles de discussion infinies.
Enfin, la sécurité de ces systèmes connectés pose des défis inédits. Leurs échanges constants exposent la mémoire collective à des risques d’empoisonnement. Une injection indirecte de requêtes peut ainsi manipuler un agent à son insu. J’estime donc que des protocoles de validation stricts doivent encadrer chaque action critique pour empêcher le sabotage ou les fuites de données.
Paradigmes technologiques émergents : apprentissage MARL et Web3
L’apprentissage par renforcement multi-agents (MARL) transforme la recherche en informatique. Dans ce modèle, les agents apprennent à collaborer par essais et erreurs au sein de simulations. Ils reçoivent des récompenses mathématiques dès qu’ils atteignent un objectif collectif. Ce mécanisme d’auto-amélioration leur permet de co-évoluer avec une supervision humaine limitée.
Les agents développent ainsi des stratégies de coordination inédites. La finance utilise le MARL pour modéliser les marchés boursiers. Les villes l’appliquent aussi pour optimiser les flottes de véhicules autonomes. Cette autonomie croissante pousse parfois ces systèmes à s’associer aux technologies décentralisées du Web3.
La blockchain offre un cadre de confiance utile à ces réseaux de machines. Elle attribue aux agents une identité numérique vérifiable et infalsifiable. Des contrats intelligents sécurisent ensuite leurs paiements directs de machine à machine, sans intermédiaire bancaire. Cette infrastructure pose les bases d’une économie plus largement pilotée par des logiciels intelligents.
Cet article Comment les Systèmes Multi-Agents réinventent l’intelligence artificielle a été publié sur LEBIGDATA.FR.