FramIActu – Le bilan après six mois de veille
Peut-être l’attendiez-vous impatiemment, et pourtant, la FramIActu de juillet n’a pas vu le jour.
Nous l’annoncions à demi-mot en juin : nous ne publierons plus la FramIActu sur un rythme mensuel. Les raisons à cela sont multiples et c’est pourquoi nous vous proposons un article « bilan », qui fait le point sur des mois (voire des années) de veille sur l’intelligence artificielle.
Différents termes techniques liés au champ de recherche de l’Intelligence Artificielle ont été utilisés dans cet article.
Si certains termes vous échappent, nous vous invitons à consulter le site FramamIA où nous avons cherché à expliquer la plupart d’entre eux.
Les évolutions techniques des derniers mois
De meilleures performances
Au cours des derniers mois, les entreprises et start-ups du domaine n’ont cessé d’améliorer les grands modèles de langage (LLMs) et autres systèmes d’IA, afin que ceux-ci puissent accomplir des tâches plus variées, être plus efficaces, et soient moins chers à produire et à déployer.
L’institut sur l’intelligence artificielle centré sur l’humain de l’université de Standford a récemment publié un index analysant ces états et évolutions sous différents aspects.
Dans ce rapport, nous constatons une forte amélioration des performances des IA sur les tests de référence servant à évaluer leurs capacités.
L’écart de performances entre les différents modèles est d’ailleurs largement réduit en comparaison de l’année dernière.
En revanche, de nouveaux tests comparatifs, bien plus exigeants, ont été développés (comme le fameux « Dernier examen de l’humanité ») et les IA y réalisent, pour le moment, des scores très faibles.
Autre amélioration : alors qu’en 2022 le plus petit modèle (PaLM) réalisait un score de 60 % à un un test comparatif spécifique (MMLU) avait besoin de 540 milliards de paramètres, le modèle Phi-3-mini de Microsoft accompli aujourd’hui les mêmes performances avec 3,8 milliards de paramètres. Il est donc aujourd’hui possible de construire des modèles qui nécessitent bien moins de ressources.
Vous avez dit six doigts ?
Les améliorations des performances et des capacités des différents modèles d’IA génératives (IAg) sont particulièrement visibles pour les IAg spécialisées dans la génération d’images et de vidéo.
Si à leurs débuts les IAg comme Dall-E ou Midjourney étaient moquées par le public en raison des absurdités qu’elles généraient, leurs résultats sont aujourd’hui bien plus difficiles à différencier de la réalité. Finies les mains à six doigts !
Les IAg permettant de créer des vidéos sont d’autant plus impressionnantes (techniquement), notamment Veo 3, de Google, récemment sortie et permettant de créer des vidéos en tout genre avec une cohérence sans précédent. Il est désormais extrêmement difficile de discerner une vidéo générée par Veo 3 d’une vidéo filmée par des humain·es.
Voici de nombreux exemples de vidéos générées par Veo 3.
Mistral, de son côté, a publié un nouveau modèle de compréhension audio nommé Voxtral. Celui-ci aurait de meilleures performances que Whisper, le modèle d’OpenAI, jusqu’alors considéré comme le meilleur en terme de rapport qualité/prix.
Voxtral propose des performances similaires ou supérieures à ses concurrents pour un coût bien plus bas.
Toutes ces améliorations sont déjà utilisées par de nombreuses entités à travers le monde.
Comme Netflix, qui a utilisé l’IAg pour créer une scène d’effondrement d’immeuble dans une de ses séries1, ou Disney, ayant utilisé ChatGPT pour écrire les paroles d’une des chansons de sa série indienne Save the Tigers2.
Netflix, d’ailleurs, souhaite mettre en place des coupures publicitaires générées par IA pendant le visionnage des vidéos3.
L’arrivée d’un nouveau paradigme : les modèles de raisonnement
Les modèles d’IAg traditionnels sont basés sur un paradigme consistant à « entraîner » les IA à partir du plus grand nombre de données possible afin de créer les millions (voire les milliards) de paramètres qui composeront le modèle. Le coût de ce type de modèle est principalement concentré sur cette phase d’entraînement.
Par exemple, le première modèle GPT d’OpenAI, GPT-1, sorti en juin 2018, contenait 117 millions de paramètres4. Un an plus tard, le modèle GPT-2 en comportait 1,5 milliards5. Quelques mois plus tard, GPT-3 en comportait 175 milliards6. Enfin, le modèle GPT-4.5, en comporterait, d’après les rumeurs7 (car nous n’avons pas de donnée officielle)… entre 5 et 10 billions (10 000 milliards) !
Ce paradigme, s’il fonctionnait très bien au cours des années précédentes, semble atteindre aujourd’hui un plafond de verre. Malgré l’augmentation massive du nombre de paramètres, les résultats obtenus ne sont pas aussi impressionnants que l’on pourrait s’y attendre, mais surtout, le coût pour exploiter de tels modèles devient difficile à assumer pour des entreprises comme OpenAI.
L’entreprise a d’ailleurs rapidement retiré GPT-4.5 de son offre8, au profit d’un nouveau modèle nommé GPT-4.1, bien moins cher pour la compagnie. (On est d’accord, c’est un peu n’importe quoi les noms de modèle chez OpenAI !)
Pour faire face aux limites qui semblent se dessiner, un nouveau paradigme a vu le jour : celui des modèles de raisonnement.
L’idée est qu’au lieu de se concentrer principalement sur l’entraînement du modèle, les modèles de raisonnement sont conçus pour accomplir des étapes supplémentaires (par rapport aux modèles classiques) afin d’achever des résultats similaires voire meilleurs sans avoir à augmenter la taille du modèle.
Contrairement à un modèle classique qui cherchera à donner directement une réponse lors de l’étape d’inférence, les modèles de raisonnement découpent cette étape en différents processus plus petits, cohérents les uns vis-à-vis des autres.
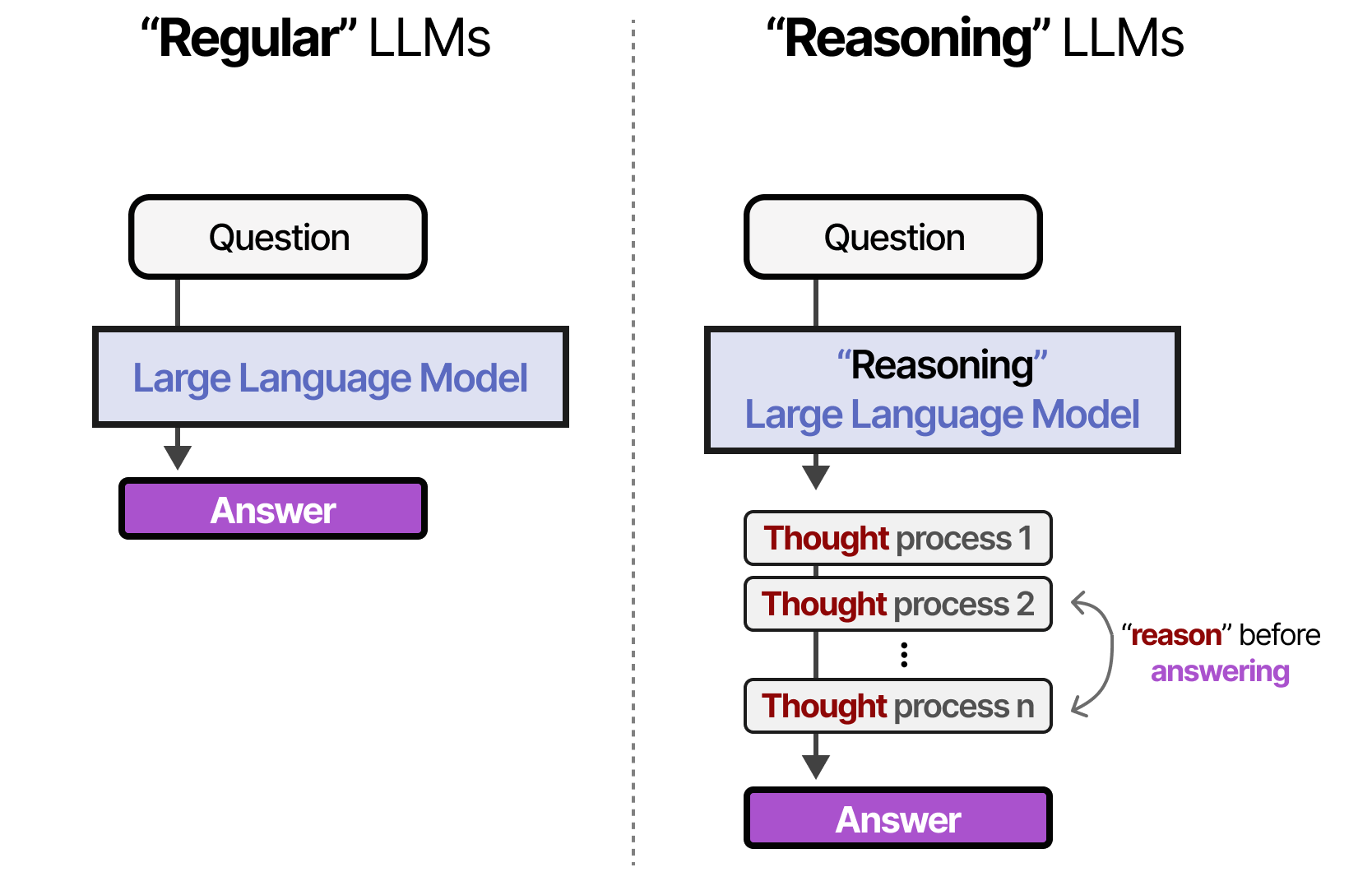
Source : Maarten Grootendorst – A visual guide to reasoning LLMs
Le nombre d’étapes qu’un modèle de raisonnement va effectuer est configurable, et peut aussi bien varier d’une étape unique à des dizaines ou des milliers. En revanche, plus le nombre d’étapes est conséquent, plus le coût (en temps, en énergie, en puissance de calcul) est élevé.
Ce dernier point représente un changement majeur : les modèles de raisonnement peuvent potentiellement être bien plus coûteux en termes de ressources que les modèles classiques car le nombre d’étapes de raisonnement revient à multiplier — souvent de façon cachée à l’utilisateurice — la quantité de calculs nécessaires pour fournir une réponse.
Or, face au succès de modèles comme Open-o1 ou DeepSeek-R1, les modèles de raisonnement ont le vent en poupe et sont souvent ceux privilégiés, aujourd’hui.
L’émergence des IA agentiques
Les IA agentiques sont des IA conçues pour être capables d’interagir avec leur environnement.
Là où les IAg classiques s’appuient sur un jeu de données figé et apportent une réponse « simple » en fonction de la demande qu’on leur fournit, les IA agentiques ont pour objectif de pouvoir accéder à d’autres applications afin d’accomplir la tâche demandée en toute autonomie. De plus, l’IA agentique est capable d’exécuter une série de sous-tâches jusqu’à l’accomplissement de la demande.
En théorie, vous pouvez demander à une IA agentique de créer votre site vitrine. Celle-ci va alors concevoir la structure du site, établir une charte graphique et l’appliquer. Elle le testera ensuite pour s’assurer qu’il fonctionne. Enfin, l’agent pourra très bien pousser le code sur une forge logiciel (comme Github, Gitlab, ou autre) et exécuter des actions sur la forge afin de créer un site accessible au public. Dans tout ce processus, votre seule action aurait été de demander à l’IA agentique de vous réaliser ce site.
Dans la pratique, les IA agentiques sont encore largement peu efficaces, les plus performantes ne réussissent pour le moment que 30 % des tâches en totale autonomie9. Cependant, comme pour les IAg auparavant, on peut assez facilement imaginer, au regard de la vitesse d’évolution des techniques d’IA, que des progrès fulgurants arriveront d’ici un an ou deux.
On peut d’ailleurs noter l’émergence d’un protocole nommé MCP, initié par Anthropic, pour standardiser la manière dont les IA se connectent à d’autres applications.
À noter que’OpenAI vient de sortir ChatGPT Agent10 prétendant pouvoir presque tout réaliser et Google a annoncé différentes applications d’IA agentiques11.
Il est probable que l’utilisation d’IA agentiques se démocratise à mesure que leurs capacités s’améliorent et que les géants comme Google les intègrent aux applications de notre quotidien.
Une accumulation de problèmes sociétaux
Nous l’avons vu, les IAg ne cessent de s’améliorer techniquement. Cependant, nombre des problèmes soulevés lors de l’apparition de ChatGPT n’ont pas été traités et de nouveaux apparaissent.
Les robots indexeurs d’IA attaquent le Web
Pour collecter les données nécessaires à l’entraînement des IA génératives, les acteurs de l’IA parcourent l’ensemble du Web pour en extraire le contenu. Aujourd’hui, de nombreux acteurs ont déployé leur propre robot pour y parvenir.
Le problème est que ces robots mettent à mal l’ensemble de l’infrastructure faisant tourner le Web et ne respectent pas les sites précisant ne pas souhaiter être indexés par ces robots.
Comme nous en parlions dans la FramIActu d’avril certains sites ont constaté que plus de 90 % de leur trafic proviennent désormais des robots d’IA. Pour Wikipédia, cela représente 50 % de trafic supplémentaire depuis 202412.
Afin de palier ce pillage des ressources et garantir l’accès de leurs sites internet aux humain·es, des organisations comme l’ONU ont opté pour la mise en place d’un logiciel « barrière » à l’entrée de leurs site13. Nommé Anubis, ce logiciel permet d’empêcher les robots d’IA d’accéder au site web. Cependant, cette barrière n’est pas sans coût : les utilisateurices doivent parfois patienter quelques fractions de seconde (voire, parfois, quelques secondes) avant de pouvoir accéder à un site internet, le temps qu’Anubis s’assure que la demande d’accès provient bien d’un·e humain·e.
À Framasoft, nous avons aussi été confronté à cette situation et certains de nos services sont désormais protégés par Anubis.
D’autres acteurs se tournent vers Cloudflare puisque cette entreprise a mis en place un outil permettant de bloquer les robots d’IA par défaut14. Cloudflare est utilisé par environs 1/5 des sites web15. Cela signifie que l’entreprise se place dans une position privilégiée pour décider de qui a le droit d’accéder au contenu de ces sites web.
À l’avenir, il est possible que les acteurs d’IA les plus riches doivent finir par payer Cloudflare pour accéder au contenu des sites protégés par l’entreprise.
Si cela se produit, un des risques possibles est qu’au lieu d’empêcher l’essor de l’IA, la situation accentue plutôt l’écart entre les géants du numérique et les autres acteurs, plus modestes.
Le Web est pollué
Depuis l’arrivée de l’IA générative, un changement majeur dans l’histoire de l’humanité a eu lieu : il est désormais plus rapide de « créer » du contenu que d’en lire.
Ce simple fait semble totalement transfigurer notre rapport au Web puisque celui-ci se rempli à une vitesse vertigineuse de contenus générés par IA, dont une bonne partie se fait passer pour du contenu rédigé par des humain·es.
Aussi, les IAg sont très fortes pour créer du contenu adapté aux règles de Google Search, permettant à des entités peu scrupuleuses de faire apparaître leur contenu en tête des résultats du moteur de recherche. Cette pratique, nommée IA Slop, représente un véritable fléau. Le contenu diffusé n’a pas besoin d’exprimer un propos en rapport avec le réel, il est généré et publié automatiquement à l’aide d’IAg afin d’attirer du public en espérant générer du trafic et des revenus publicitaires.
À ce sujet, nous republiions il y a quelques mois sur le Framablog un article passionnant d’Hubert Guillaud.
De plus, le média Next publiait, il y a quelques mois, une enquête sur le millier de médias générés par IA mis en avant par Google Actualités, la principale plateforme d’accès aux médias16.
L’IAg est aussi utilisée pour concevoir des articles et messages de médias sociaux promouvant des discours complotistes ou climato-sceptiques à une échelle presque industrielle17,18.
Les promoteurs de ces théories peuvent plus facilement que jamais trouver de nouvelles adhésions à leur discours. Cette facilité pour générer du contenu vraisemblable contribue fortement à l’accroissement des discours visant à désinformer.
À mesure que le Web se rempli de contre-vérités, celles-ci risquent de prendre de plus en plus de poids dans les réponses des futurs modèles d’IAg. On parle d’une forme d’autophagie, où les IAg se nourrissent d’éléments générés par d’autres IAg19.
C’est à cause de ce phénomène d’autophagie que des entreprises comme Reddit (un média social très populaire dans le monde anglo-saxon) peuvent se permettre de revendre à prix d’or leurs données : du texte rédigé par des humain·es et facilement identifiable comme tel20,21.
La pollution du Web ne s’arrête cependant pas aux contenus textuels… désormais, avec la facilité d’accès aux IAg d’images et de vidéos, des millions de contenus générés par l’IA pullulent sur internet.
À la sortie de Veo3, Tiktok s’est retrouvé noyé sous la quantité de vidéos généré par l’IAg, dont un certain nombre contenant des propos racistes22. Certain·es artistes ont même cherché à profiter de la tendance en prétendant que leurs vidéos étaient générée par l’IAg, alors que celles-ci étaient réalisées par des humain·es23.
Certaines entreprises se spécialisent aussi dans la génération de DeepFake pornographiques. Ces outils permettent alors à des harceleurs de nuire à leurs ex petites-amies24 et à des adolescents de nuire leurs camarades25.
Les principales victimes de ces DeepFakes sont des femmes26.
Ces contenus générés par IA et la difficulté à les différencier des contenus « humains » participent à un sentiment d’abandon du réel. Il devient tellement difficile et exigeant de différencier le contenu généré par IA des autres que l’on peut être tenté·e de se dire « À quoi bon ? ».
À la manière de ce que décrit Clément Viktorovitch vis-à-vis de la perception des discours politiques27, il est possible que nous entrons ici aussi dans une ère de post-vérité : qu’importe si le contenu est vrai ou faux, tant qu’il nous plaît.
Un rapport au savoir bouleversé
En construisant une encyclopédie collaborative, gérée comme un commun et disponible mondialement, Wikipédia a révolutionné l’accès au savoir.
Non seulement la plus grande bibliothèque de l’histoire de l’humanité est à portée de clics, mais nous pouvons désormais participer aussi à son élaboration.
Wikipédia a permis de renverser un paradigme ancré depuis longtemps qui consistait à réserver la rédaction d’une encyclopédie aux experts du sujet. Grâce à quelques règles permettant d’assurer la qualité des contributions, l’encyclopédie en ligne permet un effort d’intelligence collective inédit dans l’histoire.
Or, si Wikipédia est accessible librement dans la plupart des pays du monde, la majorité des personnes accèdent à son contenu… via le moteur de recherche Google.
En effet, le réflexe commun pour accéder à Wikipédia est de chercher un terme sur son moteur de recherche préféré (Google pour l’immense majorité de la planète) et d’espérer que celui-ci nous présente un court résumé de la page Wikipédia correspondante et nous pointe vers celle-ci.
Google sert donc aujourd’hui d’intermédiaire, de porte d’accès principale, entre une personne et la plus grande encyclopédie de l’humanité.
Le problème, c’est que Google est bien plus qu’un simple moteur de recherche.
Google possède un système éditorial complexe, « personnalisant » les résultats en fonction de l’identité d’un individu, sa culture, son pays28, et poussant les éditeurs des sites Web à se plier à la vision que l’entreprise a du Web. Ne pas respecter cette vision nuit à notre bon référencement sur le moteur de recherche et donc, fait encourir le risque de ne jamais être trouvé·e dans la masse des sites existants.
Cette vision se confond avec le but lucratif de l’entreprise, dont le profit prévaut sur le reste. C’est pourquoi les liens sponsorisés prennent une place importante (principale, presque) dans l’interface du moteur. Il est ainsi nécessaire de payer Google pour s’assurer que notre site Web soit vu.
Cette éditorialisation du contenu chez Google a encore évolué récemment avec la mise en place d’AI Overviews. Cette fonctionnalité (pas encore activée en France), s’appuyant sur l’IA de l’entreprise, résume automatiquement les contenus des différents sites Web. Certes, la fonctionnalité semble pratique, mais elle pourrait encourager une tendance à ne jamais réellement visiter les sites.
Avec l’AI Overviews, nous ne quittons plus de Google.
À travers cette fonctionnalité, Google apporte d’autres briques pour transformer notre rapport au Web29 et asseoir sa position dominante dans l’accès au savoir.
Cependant, Google n’est pas le seul acteur à transformer notre rapport au Web et à l’accès au savoir. Les IA conversationnelles prennent de plus en plus de place et récemment ChatGPT est même devenu plus utilisé que Wikipédia aux États-Unis30.
Sans que cela n’indique pour le moment une diminution dans l’usage de Wikipédia par les humain·es, il est possible que celui-ci se raréfie à mesure que la qualité des réponses des IAg s’améliorent ou recrachent directement le contenu de Wikipédia.
Les acteurs de l’IA risquent donc de devenir les nouvelles portes principales pour accéder à l’encyclopédie. Nous pouvons imaginer différents risques à cela, semblables à ceux déjà existants avec Google, comme lorsque l’entreprise a volontairement dégradé la qualité des résultats des recherches pour que les utilisateurices consultent davantage de publicités31.
Le rapport au savoir évolue aussi dans le monde de la recherche, où l’IA est aussi en train de bousculer des lignes, car de plus en plus de projets scientifiques s’appuient désormais sur ces outils32. Une étude estime que 13.5 % des recherches bio-médicales réalisées en 2024 étaient co-rédigé·es à l’aide d’une IAg33.
Les auteurices de l’étude indiquent :
Si les chercheurs peuvent remarquer et corriger les erreurs factuelles dans les résumés générés par IA de leurs propres travaux, il peut être plus difficile de trouver les erreurs de bibliographies ou de sections de discussions d’articles scientifiques générés par des LLM
et ajoutent que les LLMs peuvent répliquer les biais et autres carences qui se trouvent dans leurs données d’entraînement « ou même carrément plagier ».
De plus, l’IA n’est pas utilisée que pour la rédaction des papiers scientifiques. De plus en plus de chercheureuses basent leurs études sur des modélisations faites par IA34, entraînant parfois des résultats erronés et des difficultés à reproduire les résultats des études… voire même rendre la reproduction impossible.
Il est difficile de mettre en lumière tous les impacts sociétaux de l’IA (et particulièrement l’IAg) dans un article de blog. Nous avons simplement sélectionné quelques points qui nous semblaient intéressants mais si vous souhaitez approfondir le sujet, le site FramamIA peut vous fournir des clés de compréhension sur l’IA et ses enjeux.
L’Intelligence Artificielle n’est pas un simple outil
Depuis le tsunami provoqué par l’arrivée de ChatGPT, nous entendons souvent que l’Intelligence Artificielle n’est qu’un « simple outil », sous-entendant que son impact sur nos vies et nos sociétés dépend avant tout de notre manière de l’utiliser.

Ce discours s’appuie sur le postulat que l’outil — et la technique en général —, quel qu’il soit, est foncièrement neutre.
Or, si on reconnaît l’ambivalence de la technique, c’est-à-dire qu’elle puisse avoir à la fois des effets positifs et négatifs, cela ne signifie pas pour autant que les conséquences de ces effets s’équilibrent les unes les autres et encore moins que la technique est neutre d’un point de vue idéologique, politique, social ou économique.
Au contraire, tout outil porte forcément les intentions de ses créateurices et s’intègre dans un système économico-historico-social qui en fait un objet fondamentalement politique, éliminant toute possibilité de neutralité. De plus, les conditions d’existence d’un outil et son intégration dans nos sociétés l’intègrent de fait dans un système qui lui est propre, occultant ici l’idée de « simple outil ». Un outil est forcément plus complexe qu’il n’y paraît.
Dans son blog, reprenant un billet d’Olivier Lefebvre paru sur Terrestre.org, Christophe Masutti écrivait récemment qu’« on peut aisément comprendre que comparer une IAg et un marteau pose au moins un problème d’échelle. Il s’agit de deux systèmes techniques dont les conditions d’existence n’ont rien de commun. Si on compare des systèmes techniques, il faut en déterminer les éléments matériels et humains qui forment chaque système. »
Si le système technique du marteau du menuisier peut se réduire à des conditions matérielles et sociales relativement faciles à identifier dans un contexte restreint, il en va tout autre des IAg « dont l’envergure et les implications sociales sont gigantesques et à l’échelle mondiale ». On peut reprendre ainsi l’inventaire des conditions que dresse Olivier Lefebvre :
- des centres de données dont les constructions se multiplient, entraînant une croissance vertigineuse des besoins en électricité35,36,
- des réseaux de télécommunication étendus et des usines de production de composants électroniques, ainsi que des mines pour les matières premières qui sont elles mêmes assez complexes (plus complexes que les mines de fer) et entraînent des facteurs sociaux et géopolitiques d’envergure37,
- les investissements colossaux (en milliards de dollars) en salaires d’ingénieurs en IA, en infrastructures de calcul pour entraîner les modèles, en recherche, réalisés dans une perspective de rentabilité38,39,40,41,
- l’exploitation humaine : des millions de personnes, majoritairement dans les pays du Sud, sont payées à la tâche pour labelliser des données, sans lesquelles l’IA générative n’existerait pas42,43,44,
- le pillage d’une immense quantité d’œuvres protégées par droits d’auteurs pour l’entraînement des modèles45,46,
- et nous pouvons rattacher plein d’autres éléments en cascade pour chacun de ceux cités ci-dessus.
L’Intelligence Artificielle est une bulle économique mais…
… mais cela signifie pas que lorsque celle-ci éclatera, l’IA (et particulièrement les IA génératives) disparaîtra. Les changements apportés à la société semblent indiquer tout le contraire. L’IA a déjà commencé à transformer drastiquement notre société.
Alors que de nombreux pays du monde et d’entreprises s’étaient engagés à atteindre une neutralité carbone d’ici 2050, ces engagements semblent aujourd’hui ne plus intéresser personne. Google a augmenté de 65 % ses émissions de gaz à effet de serre en 5 ans47, Microsoft de 29 % en 4 ans48, Trump relance la filière charbon aux États-Unis49…
Au nom des sacro-saintes compétitions et productivités, les engagements climatiques reculent alors même que nous constatons qu’il est désormais impossible de limiter le réchauffement climatique à +1,5°C par rapport à l’ère pré-industrielle50.
Les conséquences du recul de ces engagements et l’amplification du réchauffement climatique liée aux effets directs (construction de nouveaux centre de données, de nouvelles sources d’énergie, etc.) et indirects (encouragement du climato-scepticisme, report des engagements climatiques, etc.) sont des effets dont les conséquences nous affectent déjà et qui s’accentueront très certainement à l’avenir.
Cependant, les bouleversements climatiques ne sont pas les seuls sujets sur lesquels s’exerce l’influence de l’IAg dans notre société. L’IAg est aussi un système poussant à la prolétarisation des sociétés.
Aujourd’hui, 93 % des 18-25 ans ont utilisé une IAg ces six derniers mois, et 42 % les utilisent au quotidien, soit deux fois plus que l’année dernière51.
Il est probable que des milliers (voire des millions) d’étudiant·es ont déjà développé une dépendance à l’IAg dans le cadre de leurs études et ne peuvent aujourd’hui plus s’en passer pour accomplir les tâches que la société et ses institutions attendent d’elles et eux.
Alors qu’un tiers des PME (Petites et Moyennes Entreprises) l’utilisent déjà, la France souhaite que 80 % des PME et ETI (Entreprises de Taille Intermédiaire) adoptent l’IA dans leurs pratiques de travail d’ici 203052.
ChatGPT est aujourd’hui utilisé par 400 millions d’utilisateurices hebdomadaires53… et nous parlons uniquement de ChatGPT, pas de Gemini, Claude, ou autre concurrent.
Dans leur excellente étude sur le « forcing de l’IA », le collectif Limites Numérique décortiquait la manière dont les géants du numérique imposent l’utilisation de l’IA à leurs utilisateurices en l’intégrant absolument partout.
WhatsApp et ses 2,4 milliards d’utilisateurices ? Meta AI est intégré par défaut.
Android et ses 3,3 milliards d’utilisateurices ? Gemini est désormais activé par défaut.
Google Search et ses 190 000 recherches par seconde ? Intégration d’AI Overviews pour 200 pays, permettant de résumer automatiquement les contenus des sites.
En trois ans, l’IA générative s’est imposée absolument partout dans notre environnement numérique et même si de nombreuses start-ups tomberont lors de l’explosion de la bulle financière54, il est probable que les géants du secteur restent en place.
Par contre, nos habitudes, nos pratiques de travail, notre rapport au monde et au savoir… eux, auront bel et bien changé.
Conclusion
Nous l’avons dit en introduction de cet article, cela fait des années que nous observons et cherchons à comprendre ce que représente l’IA et ses enjeux. Pour être honnête, ce n’est clairement pas chose aisée.
Comme nous avons essayé de le faire comprendre à travers le site FramamIA, l’IA est bien plus qu’un « simple outil ». C’est d’abord un champ de recherche mais aussi un système complexe, similaire au système numérique (dans lequel il s’intègre).
Depuis ChatGPT, notre temps de veille pour suivre l’actualité du numérique, déjà conséquent à l’époque, a presque doublé. Nous avons passé littéralement des centaines d’heures à lire des articles, à réfléchir à leur propos, à en discuter en interne. À chercher à comprendre comment techniquement fonctionne une IA générative et ses différences avec une IA spécialisée ou un algorithme n’étant pas considéré comme une IA. À chercher à comprendre, aussi, si l’adoption de cette technique n’est qu’une simple mode ou si celle-ci est bel et bien en train de révolutionner notre environnement.
Nous continuerons, à l’avenir, d’accomplir cette veille même si le rythme de publication de la FramIActu sera moins dense. Malgré tout, nous continuerons de partager notre veille sur notre site de curation dédié.
Aussi, comme nous sommes une association « qui fait », nous explorons d’autres pistes pour accomplir notre objet associatif (l’éducation populaire aux enjeux du numérique) autour de ce sujet. Nous souhaitons aider la société à subir le moins possible les conséquences négatives de l’imposition de l’IA dans nos vies.
Nous avons des pistes d’action, nous vous les partagerons quand nous seront prêt·es !
Belle fin d’été à toutes et tous !
À bientôt sur le Framablog !
- L’IA générative utilisée par Netflix dans “L’Éternaute” génère surtout… des économies — Télérama ↩︎
- Disney a crédité ChatGPT au générique de l’une de ses séries — BFMTV ↩︎
- Netflix will show generative AI ads midway through streams in 2026 — ArsTechnica ↩︎
- GPT-1 — Wikipédia ↩︎
- GPT-2 — Wikipédia ↩︎
- GPT-3 — Wikipédia ↩︎
- How Big Is GPT-4.5 and Why ? — Github ↩︎
- OpenAI lance GPT-4.1 et met déjà GPT-4.5 à la retraite — Next ↩︎
- TheAgentCompany : Benchmarking LLM Agents on Consequential Real World Tasks — arXiv ↩︎
- OpenAI dégaine son ChatGPT Agent, qui prétend pouvoir presque tout faire — Next ↩︎
- IA chez Google : des annonces, des annonces, mais quelle stratégie ? — Next ↩︎
- Comment les robots d’exploration impactent les opérations des projets Wikimedia — Wikimédia ↩︎
- Anubis works — Xe Iaso ↩︎
- Cloudflare va bloquer les crawlers des IA par défaut — Next ↩︎
- Usage statistics and market share of Cloudflare — W3Techs ↩︎
- [Enquête] Plus de 1 000 médias en français, générés par IA, polluent le web (et Google) — Next ↩︎
- The ABCs of AI and Environmental Misinformation — DeSmog ↩︎
- Anatomy of an AI-powered malicious social botnet — arXiv ↩︎
- Self-Consuming Generative Models Go MAD — arXiv ↩︎
- Exclusive : Reddit in AI content licensing deal with Google — Reuters ↩︎
- Reddit says it’s made $203M so far licensing its data — TechCrunch ↩︎
- TikTok is being flooded with racist AI videos generated by Google’s Veo 3 — ArsTechnica ↩︎
- Real TikTokers are pretending to be Veo 3 AI creations for fun, attention — ArsTechnica ↩︎
- A Deepfake Nightmare : Stalker Allegedly Made Sexual AI Images of Ex-Girlfriends and Their Families — 404 Media ↩︎
- Enquête ouverte en Normandie après la diffusion de deepfakes d’une douzaine de collégiennes — Next ↩︎
- Photos intimes, deepnudes : 13 femmes en colère s’organisent — Next ↩︎
- Clément Viktorovitch : « Le discours politique a perdu pied et s’est affranchi du réel » — L’est éclair ↩︎
- Ce site montre à quel point les moteurs de recherche ne sont pas neutres et impartiaux — Numerama ↩︎
- Pour la première fois, un géant de la tech affirme que l’IA va tuer le web — Numerama ↩︎
- Aux États-Unis, ChatGPT est plus utilisé que Wikipédia — Le Grand Continent ↩︎
- The Man Who Killed Google Search — Where’s your Ed at ? ↩︎
- Intégrité scientifique à l’heure de l’intelligence artificielle générative : ChatGPT et consorts, poison et antidote ? — Cairn.info ↩︎
- En 2024, 13,5 % des résumés d’articles de recherche biomédicale étaient co-rédigés par IA — Next ↩︎
- Why an overreliance on AI-driven modelling is bad for science — Nature ↩︎
- Intelligence artificielle : Stargate, le projet fou américain à 500 milliards de dollars — Next ↩︎
- Après Microsoft et Google, Amazon annonce aussi des investissements dans le nucléaire — Next ↩︎
- Nvidia dépense 500 milliards de dollars pour des usines dédiées à l’IA aux États-Unis — Frandroid ↩︎
- IA : une nouvelle impulsion pour la stratégie nationale — info.gouv.fr ↩︎
- Sharing : The Growing Influence of Industry in AI Research — Medium ↩︎
- ACL 2023 The Elephant in the Room : Analyzing the Presence of Big Tech in Natural Language Processing Research — arXiv ↩︎
- NVIDIA a franchi les 4 000 milliards de dollars de capitalisation — Next ↩︎
- Les sacrifiés de l’IA — France TV ↩︎
- Vidéos sur les travailleurs du clic — DataGueule ↩︎
- Meta poaches 28-year-old Scale AI CEO after taking multibillion dollar stake in startup — Reuters ↩︎
- « Vous ne pouvez plus faire sans nous » : les acteurs culturels cherchent l’accord juste avec les sociétés d’IA — Libération ↩︎
- Intelligence artificielle : Open AI copie Ghibli sans l’accord de Miyazaki — Libération ↩︎
- Google undercounts its carbon emissions, report finds — The Guardian ↩︎
- Depuis 2020, les émissions de Microsoft ont augmenté de 29 % — Next ↩︎
- Trump relance le charbon américain pour alimenter les datacenters d’IA — Datacenter Magazine ↩︎
- Limiter le réchauffement climatique à 1,5 °C est désormais impossible — Le Monde ↩︎
- Étude : 93 % des 18-25 ans utilisent l’IA en 2025 — Blog du Modérateur ↩︎
- Avec « Osez l’IA », le gouvernement veut accélérer l’adoption de l’IA en entreprise — Next ↩︎
- OpenAI’s weekly active users surpass 400 million — Reuters ↩︎
- Generative AI experiences rapid adoption, but with mixed outcomes – Highlights from VotE : AI & Machine Learning — S&P Global ↩︎