Avec la profusion de nouveautés en matière d’intelligence artificielle, ce n’est pas forcément facile de s’y retrouver. Chaque jour, il y a des nouveaux modèles qui sortent pour générer du texte, des images, des vidéos, de la musique et etc … L’actualité autour de l’IA est très riche et cela peut parfois devenir difficile de ... Lire la suite
PDG de Mistral : « L'impact de l'IA sur le PIB de chaque pays sera à deux chiffres dans les années à venir ». Arthur Mensch a comparé l'IA à l'avènement de l'électricité, encourageant des nations à développer leurs infrastructures
L'influence sur l'économie de l'intelligence artificielle est de plus en plus mise en avant. Le PDG de Mistral, une entreprise qui a choisi l'axe de l'open source dans son développement de l'IA, a récemment prédit que l'IA pourrait entraîner une croissance à deux chiffres...
Alibaba lance un modèle open source avancé de génération de vidéos basé sur l'IA qui devient rapidement un outil pour générer du porno
Alibaba, le géant chinois du commerce et de la technologie, a récemment lancé un modèle avancé de génération de vidéos basé sur l'intelligence artificielle. Présenté comme une avancée majeure dans le domaine de la création de contenu, ce modèle open source a cependant été rapidement détourné par des utilisateurs pour produire des vidéos pornographiques générées...
OpenAI a annoncé son intention d'intégrer son générateur de vidéos Sora directement dans ChatGPT, afin de créer un centre de création unique pour les textes, les images et les vidéos.
OpenAI a l'intention d'intégrer son outil de génération de vidéos d'IA, Sora, directement dans son application de chatbot grand public, ChatGPT. Aujourd'hui, Sora n'est disponible que par le biais d'une application web dédiée lancée par OpenAI en décembre. Cependant, Rohan Sahai, chef de produit d'OpenAI pour Sora,...
Les vidéos de deepfake deviennent étonnamment bonnes : l'IA chinoise OmniHuman-1 peut générer les vidéos de deepfake les plus réalistes à ce jour, parlant, chantant et bougeant, à partir d'une seule photo.
Des chercheurs de ByteDance, propriétaire de TikTok, ont fait la démonstration d'un nouveau système d'IA, OmniHuman-1, capable de générer les vidéos deepfake les plus réalistes à ce jour. Le modèle n'a besoin que d'une seule image de référence et d'un son pour générer un clip vidéo. OmniHuman...
Google Deepmind présente Veo 2, un nouvel outil de génération de vidéos par l'IA pour créer des "vidéos d'une qualité incroyable" dans le but de battre Sora d'OpenAI et d'être le meilleur modèle IA vidéo
Google Deepmind a présenté Veo 2, un nouvel outil de génération de vidéos par intelligence artificielle (IA) qui s'appuie sur le Veo original et crée des "vidéos d'une qualité incroyable". Cette annonce intervient après le lancement de la version officielle de Sora, le modèle...
Chameleon : un modèle d'IA capable de vous protéger de la reconnaissance faciale grâce à un masque numérique sophistiqué l'outil vise à empêcher la formation de l'IA générative sur des images personnelles
Un groupe de chercheurs a mis au point un système d'IA capable de protéger les utilisateurs contre la reconnaissance faciale indésirable par des acteurs malveillants. Baptisé Chameleon, le modèle d'IA utilise une technologie spéciale de masquage pour générer un masque qui dissimule les visages...
La startup française Mistral AI annonce la sortie de Large 2, son nouveau LLM phare avec 123 milliards de paramètres, qui serait meilleur pour générer du code, des mathématiques et du raisonnement.
Mistral AI annonce la sortie de Mistral Large 2, la nouvelle génération de son grand modèle de langage. Par rapport à son prédécesseur, Mistral Large 2 est nettement plus performant en matière de génération de code, de mathématiques et de raisonnement. Il offre également un support multilingue beaucoup...
Le fondateur de Zoom, Eric Yuan, envisage d'intégrer des clones d'IA, ou « jumeaux numériques », dans les réunions, pour représenter les utilisateurs et prendre des décisions en leur nom
Eric Yuan, PDG et fondateur de Zoom, envisage d'intégrer des clones d'intelligence artificielle (IA), ou « jumeaux numériques », dans les réunions pour représenter les utilisateurs et prendre des décisions en leur nom. Ayant fondé Zoom après avoir travaillé chez Cisco, Yuan a simplifié la vidéoconférence et vu...
Des étudiants de Harvard ajoutent la reconnaissance faciale aux lunettes connectées Ray-Ban de Meta pour identifier les inconnus en temps réel la démonstration met en évidence le côté obscur de ces gadgets
Deux étudiants de Harvard ont créé une démonstration inquiétante de la façon dont les lunettes connectées peuvent faire appel à la reconnaissance faciale pour obtenir instantanément l'identité, le numéro de téléphone et l'adresse d'une personne. Leur démonstration utilise des technologies actuelles...
Raspberry Pi et Sony s'associent pour lancer un module caméra pour les applications d'IA basées sur la vision par ordinateur, Raspberry Pi AI Camera est doté d'un traitement IA intégré et coûte 70 dollars
Le 30 septembre 2024, Raspberry Pi a annoncé une avancée majeure dans le domaine de la vision par ordinateur avec le lancement de son nouveau module caméra, le Raspberry Pi AI Camera. Ce module, développé en collaboration avec Sony, intègre le capteur d'image intelligent IMX500 de Sony, capable...
La veille technologique fait partie des missions de tout responsable informatique. Elle repose sur une bonne connaissance et une consultation régulière de de ressources disponibles en ligne, mais pas seulement. Il n’est pas rare que les usages évoluent au sein de la structure et que nous découvrions, en échangeant avec nos utilisateurs, de nouveaux outils. Problème : ils ne correspondent pas toujours aux recommandations du service informatique, sont parfois incompatibles avec le RGPD ou peuvent poser des problèmes de confidentialité (ou de sécurité).
La politique de la ville d’Échirolles privilégie l’utilisation de logiciels libres et une gestion responsable des données. Il est donc de notre devoir, quand un logiciel n’est pas compatible avec notre schéma directeur « Échirolles numérique libre »., de nous en préoccuper. Mais ces solutions naissent dans notre système d’information parce qu’elles correspondent à un besoin non couvert ou que les utilisateurs considèrent comme plus simple/plus efficace, etc. Interdire l’utilisation n’est donc pas satisfaisant du point de vue du service rendu : il convient de se mettre à la recherche d’alternatives qui sont mieux adaptées au projet de la structure.
Depuis quelques années, Canva est apparu dans nombre d’entreprises et de collectivités, son utilisation est rapidement devenue massive. Nous nous sommes donc mis à la recherche d’une solution crédible, open source, et qui permettrait d’apporter une réponse au besoin de nos employés. Il en existe de nombreuses, et le benchmarking n’a pas été simple. Mais une solution a fini par s’imposer :
Polotno
Polotno se présente comme un clone de Canva. Il permet la création de présentations, posters ou création graphiques en local. Aucun compte n’est nécessaire et les productions ne sont pas conservées sur le serveur.
Il partage avec la solution propriétaire une interface simple et intuitive, l’accès direct à d’immenses bases de données d’icônes (Iconfinder et Noun Project), de photographies (Unsplash), et de nombreux modèles graphiques ou textuels.
Une version en ligne existe à l’adresse studio.polotno.com. Les créations sont conservées localement dans le cache du navigateur, ce qui est plutôt une bonne chose du point de vue de la confidentialité mais qui ne facilite pas le travail en équipe. En revanche, la possibilité d’exporter les créations (en format JSON) avec l’ensemble des éléments (photos, polices, etc.) permet de les transmettre facilement, et de les sauvegarder.
Petit couac : cette version en ligne est mal traduite en français et l’utilisateur est encouragé à créer un compte (payant) sur un cloud en ligne pour sauvegarder son travail. Heureusement, il s’agit d’un logiciel open source. Le code est accessible sous licence MIT. Nous avons donc fait le choix de créer une instance échirolloise de Polotno, correctement traduite et expurgée de ces éléments commerciaux.
J’en ai également installé une, auto-hébergée, pour mon usage personnel. Vous pouvez la tester en cliquant ici.
Quelques éléments ne sont pas encore à la hauteur (impossibilité, dans le module texte, de créer des listes), mais le logiciel évolue rapidement et les mises à jour apportent régulièrement des améliorations.
Sur la gestion des données personnelles par Canva (en anglais) :
Alibaba présente la révolution MIMO : La synthèse vidéo de personnages contrôlables à l'aide de la modélisation spatiale décomposée vise à produire des vidéos réalistes de personnages animables.
Alibaba présente MIMO, un nouveau cadre qui permet de synthétiser des vidéos de personnages avec des attributs contrôlables. À l'aide de la modélisation spatiale décomposée, MIMO vise à produire des vidéos réalistes de personnages animables dans des scènes réalistes.
OpenAI permet désormais aux utilisateurs gratuits de ChatGPT d'accéder à DALL-E 3, un modèle d'IA texte-image avancé, les utilisateurs peuvent générer jusqu'à deux images par jour via DALL-E 3.
OpenAI permet désormais aux utilisateurs gratuits de ChatGPT d'accéder à DALL-E 3. Cette fonctionnalité est partiellement disponible sur le plan gratuit, auparavant réservé aux utilisateurs Plus. Les utilisateurs peuvent générer jusqu'à deux images d'IA par jour grâce au modèle DALL-E 3. OpenAI teste également...
Le modèle GPT-4o présente un risque "moyen", selon la dernière évaluation d'OpenAI, qui met en lumière ses efforts pour atténuer les risques potentiels liés à son dernier modèle d'IA multimodale.
OpenAI vient de publier la fiche système de GPT-4o. Le document met en lumière les efforts d'OpenAI pour atténuer les risques potentiels associés à son dernier modèle d'IA multimodale. Selon cette évaluation, GPT-4o présente des risques "faibles" pour la cybersécurité, les menaces biologiques,...
Stability AI lance Stable Fast 3D : une nouvelle IA générative d'images 3D 1200 fois plus rapide, qui peut créer des images 3D à partir d'une seule image d'entrée en seulement une demi-seconde.
Stability AI lance Stable Fast 3D qui génère des ressources 3D de haute qualité à partir d'une seule image en seulement 0,5 seconde. Construit sur la base de TripoSR, Stable Fast 3D présente des améliorations architecturales significatives et des capacités accrues. Le modèle a des applications pour les développeurs...
Glaze, outil contre le mimétisme de l'IA, piraté : les artistes font face à des délais d'attente pour la protection contre l'imitation par l'IA, au milieu des MAJ des conditions de service
Les artistes sont de plus en plus inquiets face aux menaces posées par l'intelligence artificielle (IA), capable de copier leurs styles uniques. En réponse à cette préoccupation, l'outil Glaze, qui ajoute un bruit imperceptible aux images pour empêcher leur utilisation par les générateurs d'images IA, est en...
NVIDIA introduit l'IA dans le monde physique à la CVPR, avec NVIDIA Omniverse Cloud Sensor RTX, un nouvel ensemble de microservices, et JeDi qui simplifie la génération d'images personnalisées
NVIDIA Research présente plus de 50 articles à la conférence Computer Vision and Pattern Recognition (CVPR), introduisant des logiciels d'IA avec des applications potentielles dans les industries créatives, le développement de véhicules autonomes, les soins de santé et la robotique.
Les films seront-ils bientôt générés dans leur entièreté par IA ? Oui, selon l'acteur et investisseur technologique Ashton Kutcher Qui estime que ce sera le cas après avoir passé Sora d'OpenAI au test
Ashton Kutcher, acteur et investisseur technologique, a récemment déclaré que nous serions bientôt capables de générer un film entier à l'aide de l'IA, propulsant ainsi la barre de la créativité et de l'innovation à Hollywood à des niveaux jamais atteints. C'est une sortie qui n'échappe pas aux critiques...
Présentation de l'IA "Gen-3 Alpha" : le nouveau modèle de base de Runway pour la génération de vidéos, des vidéos détaillées avec des changements de scène, ainsi qu'un éventail de choix cinématiques.
Runway présente l'IA "Gen-3 Alpha", son nouveau modèle de base pour la génération de vidéos. Selon Runway, Gen-3 Alpha permet de créer des vidéos très détaillées avec des changements de scène complexes, un large éventail de choix cinématiques et des directions artistiques détaillées.
Que ce soit pour les sessions de jeu vidéo, les conférences virtuelles ou simplement pour animer une chaîne YouTube, les avatars animés ajoutent une touche dynamique à votre présence numérique. Ce présent guide vous présente les outils IA disponibles pour transformer vos photos statiques en personnages pleins d’entrain.
Choix du style d’avatar : définir son univers visuel
L’étape initiale dans la création d’un avatar animé consiste à définir l’esthétique souhaitée. Le choix du style d’avatar influence grandement son impact visuel. Veut-on qu’il représente fidèlement notre vraie apparence, ou préfère-t-on adopter un design fantaisiste ? Des options variées s’offrent ici, allant du portrait réaliste au style crayonné plus artistique. Cette décision détermine non seulement l’apparence de l’avatar, mais également l’univers dans lequel il évoluera.
Cette vidéo montre comment créer un avatar qui bouge en quelques minutes.
Principaux outils IA pour la création d’avatars animés
Plusieurs plateformes IA offrent désormais des services avancés pour la création et l’animation d’avatars. Quelques-uns d’entre eux se distinguent particulièrement par leur efficacité et leur facilité d’utilisation. Adobe Character Animator permet par exemple de donner vie à des dessins via webcam en reproduisant les expressions faciales de l’utilisateur. Pour sa part, FaceRig utilise également la reconnaissance faciale pour animer des avatars 3D en temps réel pour le plus grand bonheur des gamers et vlogueurs.
Pour sa part, Zepeto est très populaire chez les jeunes. Cette application mobile permet de créer un avatar à partir d’une simple photographie et de l’animer dans différents contextes sociaux. Application navite sur les appareils fonctionnant avec iOS, Memoji permet de créer des avatars stylisés qui peuvent être utilisés dans les vidéos et lors des chats vidéos. D’autres alternatives encore plus intéressantes sont à trouver sur notre guide. Consultez-le maintenant !
Étapes à suivre pour créer et animer un avatar
La création d’un avatar animé passe par plusieurs étapes clés, de la conception à l’animation proprement dite :
1️⃣ Sélection de l’image. Tout commence par choisir la bonne photo, celle qui sera transformée en un avatar. Idéalement, optez pour un cliché bien éclairé où les traits du visage sont clairement visibles. –
2️⃣ Importation dans le programme choisi. Une fois l’image sélectionnée, on l’importe dans l’un des programmes mentionnés ci-dessus. Chaque programme propose une méthode légèrement différente d’importation et de configuration initiale.
3️⃣ Personnalisation. Avant d’animer votre avatar, prenez le temps de personnaliser son apparence. Modifiez la coiffure, le maquillage, le vêtement pour qu’ils correspondent parfaitement à l’identité que vous souhaitez projeter.
4️⃣ Animation. En fonction de l’outil utilisé, vous pouvez ensuite procéder à l’animation de votre avatar. Cela peut impliquer de synchroniser les mouvements des lèvres avec une piste audio pour une voix off, d’ajouter des gestes manuels ou même des pas de danse.
5️⃣ Exportation. Après avoir animé votre avatar comme désiré, l’étape finale est de l’exporter sous forme de fichier vidéo ou GIF, prêt à être partagé sur les plateformes de médias sociaux ou intégré dans des projets vidéo plus vastes.
Utilisations créatives d’un avatar animé
Au-delà des jeux et des interactions sociales virtuelles, les avatars animés servent également de puissants outils dans le domaine professionnel. Ils peuvent servir d’assistants virtuels, animant des sessions Questions-Réponses sur des sites web d’entreprises ou même présentant des tutoriels. Les possibilités sont presque illimitées et permettent d’ajouter une dimension interactive là où les textes et images fixes échouent à captiver l’audience autant que des avatars dynamiques.
Employer des avatars animés dans vos communications augmente non seulement l’engagement utilisateur, mais aussi enrichit l’expérience digitale globale. La capacité de transmettre des émotions et des intentions à travers des gestes enrichit considérablement l’interactivité d’une session en ligne. De surcroît, dans une ère où le temps passé devant les écrans ne cesse de croître, utiliser des formes variées de média telles que les avatars animés peut différencier significativement votre contenu digital.
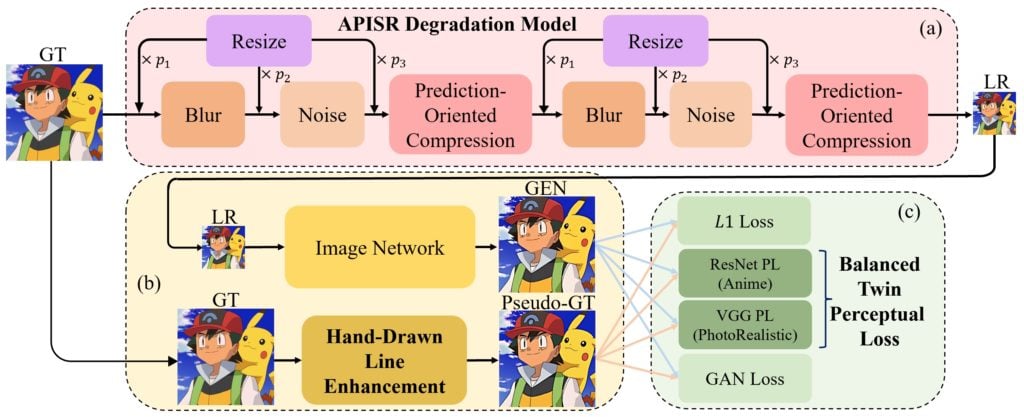
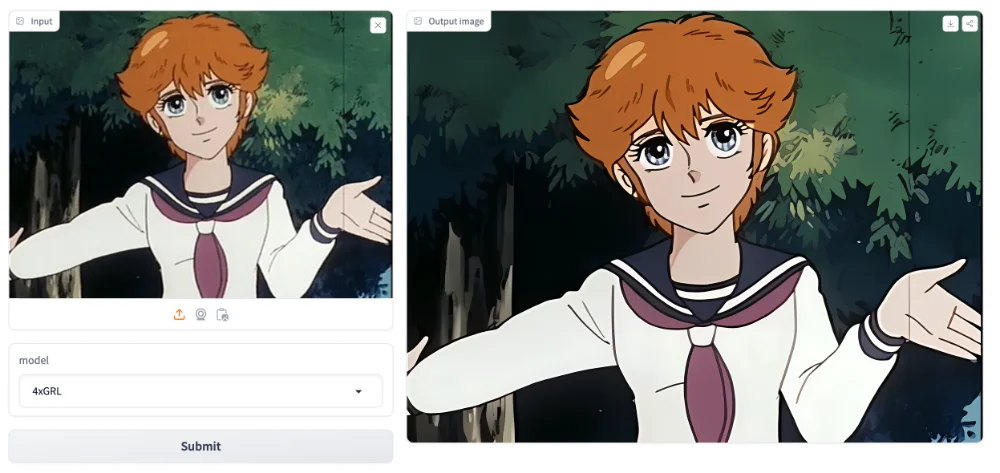
Comme beaucoup d’entre vous, j’ai été élévé au Club Dorothée et malheureusement, en 2024, tous ces animés de notre enfance, de Goldorak aux Chevaliers du Zodiaque, en passant par Nicky Larson, ont quand même mal vieilli. Ah si seulement, on pouvait les améliorer pour les remettre graphiquement au goût du jour… Et bien bonne nouvelle, c’est possible grâce au projet APISR.
Cet outil utilise différentes techniques directement inspirées du processus de production des animes afin de proposer un upscaling vraiment spécialisé pour ce type de vidéos. APISR sélectionne ainsi les frames les moins compressées et les plus riches en informations pour en faire un dataset qui servira alors à améliorer les images, en éliminant les artéfacts de dégradation et en retravaillant les lignes déformées ou estompées des dessins.
Et le résultat est bluffant comme vous pouvez le voir ici sur la démo. C’est génial puisque les fans d’animes vont pouvoir revoir les classiques de leur jeunesse avec une qualité digne des meilleures productions actuelles, le tout en temps réel.
En attendant de voir ces versions remasterisées grâce à des players ou des outils qui n’existent pas encore, vous pouvez déjà tester APISR grâce au code source disponible sur GitHub ou via Huggingface.
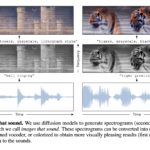
Des chercheurs de l’Université du Michigan ont mis au point une technique absolument dingue qui permet de générer des spectrogrammes ayant l’allure d’images capables de produire des sons qui leur correspondent lorsqu’ils sont écoutés. Ils appellent cela des « images qui sonnent ».
Leur approche est simple et fonctionne sans entraînement spécifique. Elle s’appuie sur des modèles de diffusion text-to-image et text-to-spectrogram pré-entraînés, opérant dans un espace latent partagé. Durant le processus de génération, les deux modèles « débruitent » des latents partagés de manière simultanée, guidés par deux textes décrivant l’image et le son désirés.
Le résultat est bluffant ! Ça donne des spectrogrammes qui, vus comme des images, ressemblent à un château avec des tours, et écoutés comme des sons, font entendre des cloches. Ou des tigres dont les rayures cachent les motifs sonores de leurs rugissements.
Pour évaluer leur bidouille, les chercheurs ont utilisé des métriques quantitatives comme CLIP et CLAP, ainsi que des études de perception humaine. Leur méthode dépasse les approches alternatives et génère des échantillons qui collent finement aux prompts textuels dans les deux modalités. Ils montrent aussi que coloriser les spectrogrammes donne des images plus agréables à l’œil, tout en préservant l’audio.
Cette prouesse révèle qu’il existe une intersection entre la distribution des images et celle des spectrogrammes audio et en dépit de leurs différences, ils partagent des caractéristiques bas niveau comme les contours, les courbes et les coins. Cela permet de composer de façon inattendue des éléments visuels ET acoustiques, comme une ligne qui marque à la fois l’attaque d’un son de cloche et le contour d’un clocher.
Les auteurs y voient une avancée pour la génération multimodale par composition et une nouvelle forme d’expression artistique audio-visuelle. Une sorte de stéganographie qui cacherait des images dans une piste son, dévoilées uniquement lorsqu’elles sont transformées en spectrogramme.
Pour recréer cette méthode chez vous, il « suffit » d’aller sur le Github du projet et de suivre les instructions techniques.
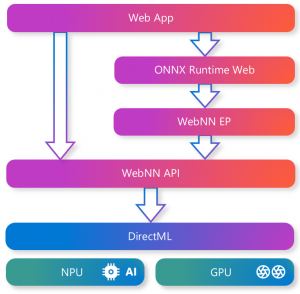
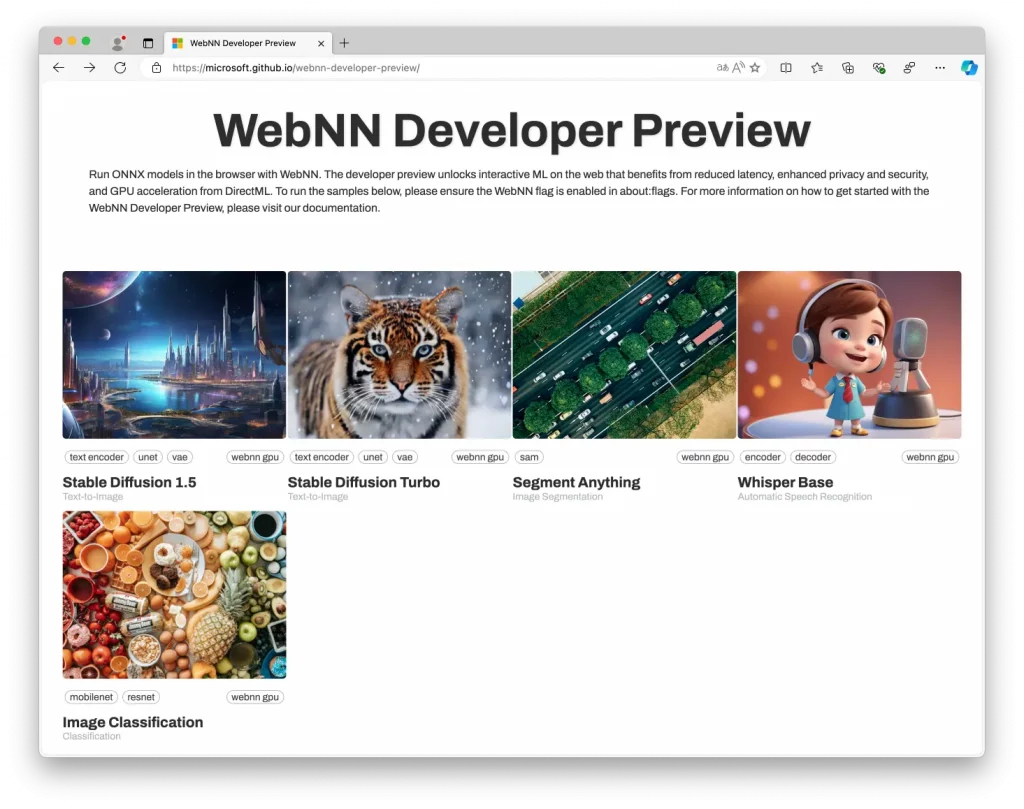
Ça y est, les amis, l’API WebNN débarque enfin en preview pour les développeurs, et croyez-moi, ça va changer totalement la manière dont on fait tourner de l’IA dans nos navigateurs web !Grâce à cette techno, on va pouvoir profiter de la puissance de nos GPU et autres accélérateurs matériels directement depuis nos pages web, sans avoir à installer le moindre plugin ou logiciel supplémentaire.
Concrètement, WebNN est une API JavaScript qui va permettre aux applications web d’exécuter des tâches d’inférence de réseaux neuronaux de manière super efficace, en exploitant à fond les capacités des CPU, GPU et autres processeurs dédiés à l’IA (les fameux NPU et TPU). Fini les calculs qui rament, bonjour la fluidité et la réactivité, même pour les modèles les plus gourmands !
WebNN est complètement agnostique côté matériel et côté modèles. Quel que soit le hardware qu’on a sous le capot (Intel, AMD, NVIDIA, Qualcomm…) et le format des modèles (ONNX, TensorFlow…), cette API va nous permettre de tirer parti un maximum des ressources disponibles, tout ça de manière transparente, sans avoir à se prendre la tête avec des lignes de code spécifiques à chaque plateforme.
Cette API suit un modèle de programmation super simple en deux grandes étapes :
1. La construction du modèle : on utilise l’API MLGraphBuilder pour définir notre réseau de neurones, ses opérations, ses entrées et ses sorties et une fois que c’est fait, on peut le compiler en un graphe exécutable.
2. L’exécution du modèle : maintenant qu’on a notre super graphe optimisé, il ne reste plus qu’à lui envoyer nos données d’entrée, et il va nous fournir ses prédictions et classifications à toute vitesse !
Grâce à WebNN, les tâches d’inférence de machine learning sont accélérées par le matériel local, ce qui offre des performances améliorées et une faible latence, même sans connexion internet ou avec une connexion non fiable. De plus, les données restent sur la machine de l’utilisateur, ce qui préserve ainsi sa vie privée.
WebNN est conçu pour fonctionner avec DirectML sur Windows, lequel assure des performances optimales sur divers matériels, notamment les RTX GPUs de NVIDIA, les Intel Core Ultra avec Intel AI Boost, et les Copilot+ PC avec des NPU Qualcomm Hexagon. Ça ouvre la porte à des applications évoluées de génération d’IA, de reconnaissance d’images, de traitement du langage naturel, et bien d’autres cas d’utilisation tout à fait passionnants.
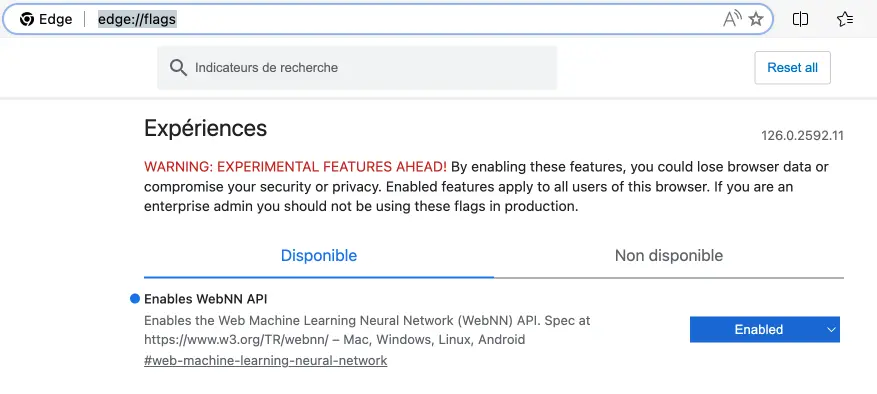
Si vous voulez vous lancer dès maintenant avec WebNN, je vous conseille fortement de visiter le dépôt WebNN Developer Preview sur GitHub. Vous y trouverez plein de démos et d’exemples de code pour vous familiariser avec l’API et ses fonctionnalités. Par contre, vous devrez télécharger Edge en version Canary et la dernière Insider de Windows 11 puis dans la barre d’URL, tapez edge://flags/ pour pouvoir ensuite activer WebNN.
Les deepfakes sont désormais le deuxième incident de sécurité le plus fréquent, les attaquants utilisent la technologie d'IA pour inciter les victimes à effectuer des transferts de fonds, d'après ISMS.online
L'inquiétude autour des deepfakes grandit depuis un certain temps et une nouvelle étude publiée par ISMS.online montre que les deepfakes se classent désormais au deuxième rang des incidents de sécurité de l'information les plus courants pour les entreprises britanniques et que plus d'un tiers...
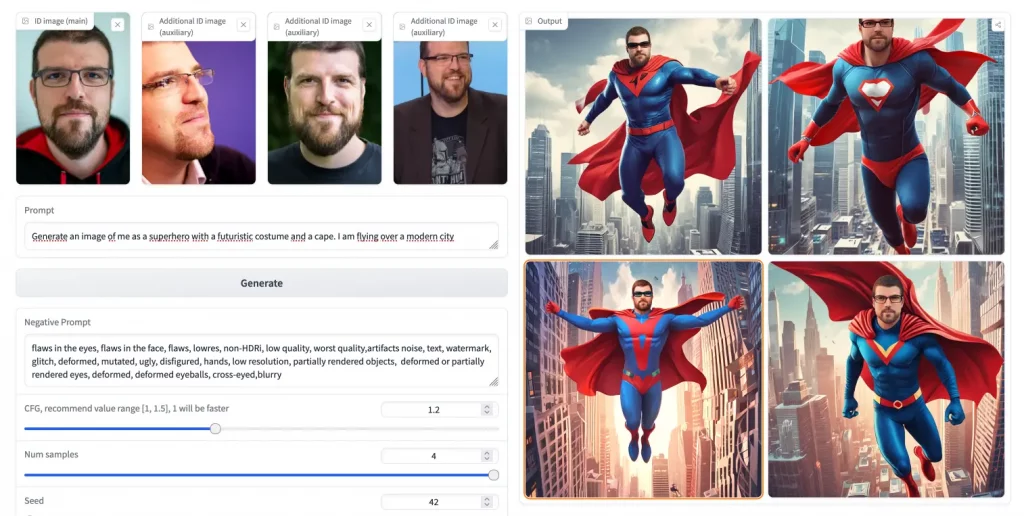
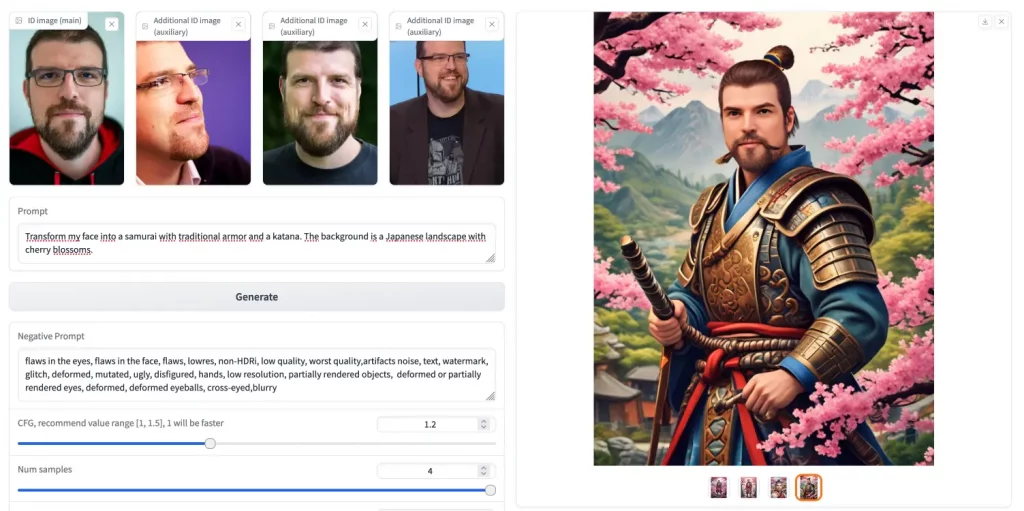
Développé par une équipe de chez ByteDance (mais si, TikTok, votre réseau social préféré), ce modèle baptisé PuLID va vous permettre de créer des images sur-mesure à partir de photos existantes et tout ça en un clin d’œil.
Basé sur le principe d’alignement contrastif, PuLID vous offre une customisation d’identité ultra rapide et de haute qualité. Pour cela, il utilise une architecture qui apprend à la volée les caractéristiques clés d’une identité source (des photos de vous) pour les transposer efficacement sur de nouvelles images cibles (images générées par IA). On obtient alors des visuels uniques générés en quelques secondes à peine, tout en préservant la cohérence des photos d’origine.
Bon, ok, ça peut paraître un peu barbare dit comme ça mais c’est super simple à utiliser. Si vous êtes flemmard, vous pouvez aller directement sur Huggingface ou pour les plus courageux, l’installer sur votre machine. Tout ce dont vous avez besoin, c’est d’un bon vieux Pytorch (version 2.0 minimum svp) et de quelques lignes de code pour démarrer l’entraînement.
PuLID (Pure and Lightning ID Customization via Contrastive Alignment) fonctionne en utilisant des techniques de machine learning pour aligner des représentations latentes en comparant des paires d’images ou d’identités. L’objectif est de maximiser la similarité pour des identités similaires et de minimiser la similarité pour des identités différentes. En ajustant ces représentations grâce à l’alignement contrastif, PuLID permet de créer des images uniques avec une grande précision et rapidité.
Si vous bossez dans la comm et que ous avez déjà quelques concepts arts sympas d’un personnage, mais vous aimeriez voir à quoi il ressemblerait dans différents environnements ou avec des styles graphiques variés, pas de souci ! Vous balancez vos images dans PuLID avec les bonnes instructions et le tour est joué. Vous obtiendrez alors tout un tas de variations stylées de votre personnage, tout en gardant son visage reconnaissable.
L’équipe de ByteDance a pensé à tout : PuLID est 100% open-source et disponible sur GitHub. Vous pouvez donc bidouiller le code comme bon vous semble pour l’adapter à vos besoins. Y’a même des tutoriels et des exemples pour vous aider à prendre en main le bouzin rapidement.
Et pour les plus impatients d’entre vous, voici un petit tuto d’installation pour commencer à jouer avec PuLID :
Installer PyTorch : Suivez les instructions sur le site de PyTorch pour installer la version compatible avec votre système. Par exemple, pour CUDA 11.7 :
Pour en savoir plus sur PuLID et récupérer le code source, rendez-vous sur le repo GitHub.
Allez, je vous laisse vous amuser avec votre nouveau jouet. Un grand merci à Lorenper pour l’info. Grâce à toi, on va pouvoir personnaliser nos avatars comme jamais.
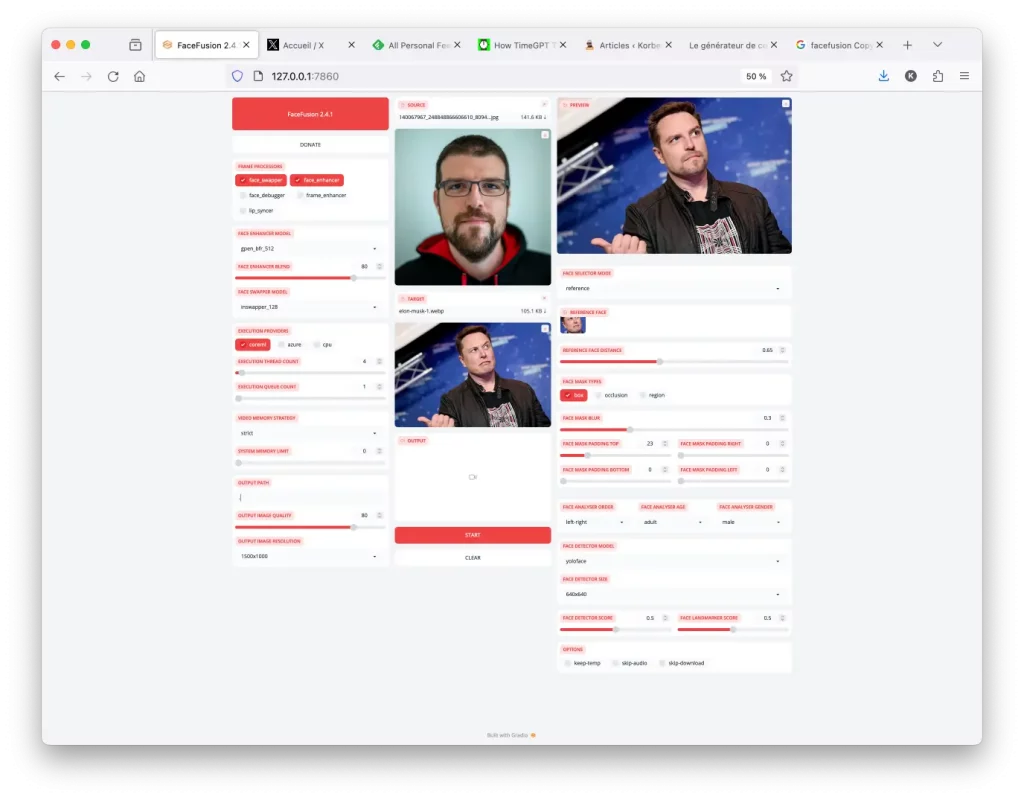
Dernièrement, j’ai testé FaceFusion et j’ai adoré, donc je voulais vous en parler rapidement. Il s’agit d’un outil open source qui permet de faire des échanges de visages (swap) d’une excellente qualité aussi bien avec des photos que des vidéos. Vous vous en doutez, le tout est boosté par de l’intelligence artificielle comme un peu tout ce qui sort en ce moment.
En gros, vous prenez votre visage, vous la collez sur une autre, et bim, ça donne un truc hyper réaliste en quelques clics !
Sous le capot, FaceFusion utilise des techniques de pointe en deep learning pour détecter et aligner les visages avec une précision chirurgicale. Ça passe par des modèles comme YOLOFace ou RetinaFace pour repérer les faciès, puis des algos transforment et mixent tout ça façon Picasso du futur.
Le résultat est assez bluffant puisque vous pouvez littéralement mettre votre tronche de cake à la place de Leonardo DiCaprio et devenir la star de Titanic en deux temps trois mouvements (de brasse coulée).
FaceFusion est optimisé pour le GPU mais fonctionnera également sur votre bon vieux CPU et cela même sur des vidéos en grosses résolutions. D’ailleurs, y’a ‘tout un tas de réglages pour gérer la qualité, que ce soit pour du swap d’image ou de vidéo.
Et histoire de vous simplifier la vie, une jolie interface graphique est même fournie pour piloter l’outil sans mettre les mains dans le cambouis.
Franchement, FaceFusion c’est un outil vraiment cool mais faudra quand même pas déconner et en faire n’importe quoi hein, genre swapper des têtes de politiques pour faire des deep fakes SURTOUT AVEC BURNO LE MAIRE, ça peut vite partir en vrille. 😅
Bref que ce soit pour faire des blagues à vos potes, créer des effets spéciaux délirants, ou juste explorer le champ des possibles de l’IA appliquée à l’image, FaceFusion risque de vite devenir votre nouveau meilleur ami. Et vu que c’est open source, vous pouvez mettre les mains dans le code si ça vous éclate.
Bref, foncez sur le GitHub et en cadeau, je vous ai même fait une vidéo tuto !
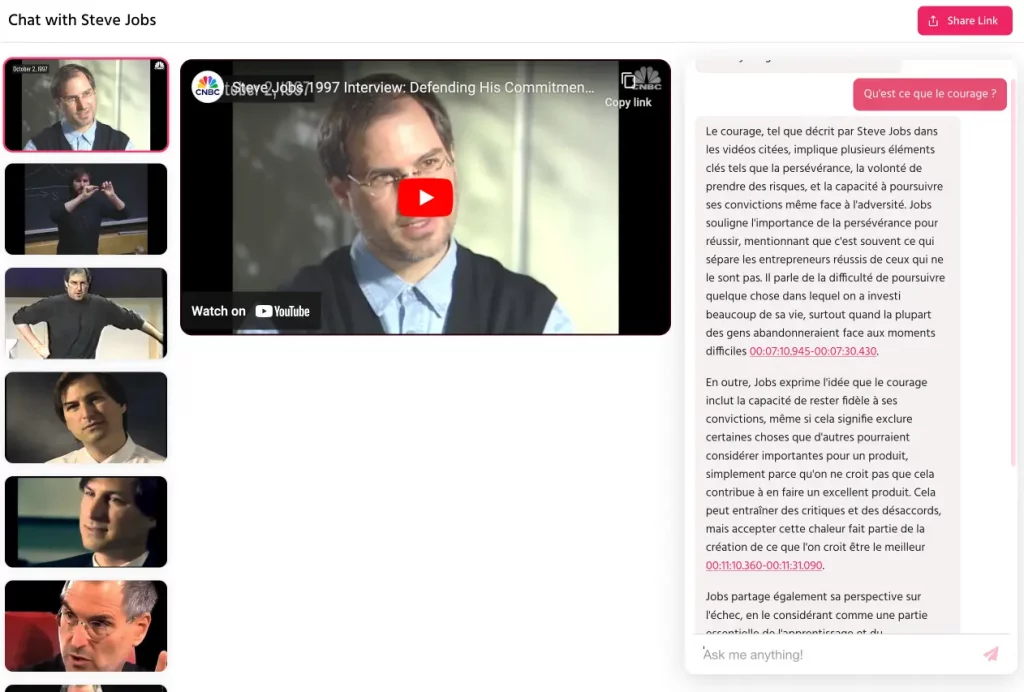
Grâce à la magie de l’intelligence artificielle, vous allez pouvoir discuter avec votre gourou préféré. Enfin, quand je dis « discuter », c’est un bien grand mot. Disons plutôt que vous allez pouvoir poser des questions à un modèle de langage entraîné sur une petite quantité d’interviews et discours de Steve Jobs himself.
Pour cela, le créateur de ce chatbot a utilisé un service nommé Jelli.io qui permet justement de chatter avec des vidéos et le résultat est plutôt cool, même si le chatbot n’incarne pas directement Steve Jobs (pour des questions éthiques j’imagine et pour n’énerver personne…)
Bref, de quoi vous inspirer et vous motiver sans forcement mater des heures et des heures d’interviews.
VASA-1 est un nouveau framework qui permet de générer des visages parlants ultra-réalistes en temps réel ! En gros, vous balancez une simple photo à cette IA, ainsi qu’un petit clip audio, et bim ! Elle vous pond une vidéo d’un visage qui parle, avec une synchronisation de la bouche nickel chrome, des expressions faciales hyper naturelles et des mouvements de tête très fluides. C’est hyper bluffant !
Les chercheurs de Microsoft ont réussi ce tour de force en combinant plusieurs techniques de pointe en deep learning. Ils ont d’abord créé un espace latent expressif et bien organisé pour représenter les visages humains. Ça permet de générer de nouveaux visages variés, qui restent cohérents avec les données existantes. Ensuite, ils ont entraîné un modèle de génération de dynamiques faciales et de mouvements de tête, appelé le Diffusion Transformer, pour générer les mouvements à partir de l’audio et d’autres signaux de contrôle.
Et le résultat est juste époustouflant. On a l’impression de voir de vraies personnes qui parlent, avec toutes les nuances et les subtilités des expressions faciales. Les lèvres bougent parfaitement en rythme avec les paroles, les yeux clignent et regardent naturellement, les sourcils se lèvent et se froncent…
En plus de ça, VASA-1 peut générer des vidéos en haute résolution (512×512) à une cadence élevée, jusqu’à 40 images par seconde, avec une latence de démarrage négligeable. Autant dire que c’est le graal pour toutes les applications qui nécessitent des avatars parlants réalistes. On peut imaginer des assistants virtuels avec lesquels on pourrait interagir de manière super naturelle, des personnages de jeux vidéo encore plus crédibles et attachants, des outils pédagogiques révolutionnaires pour apprendre les langues ou d’autres matières, des thérapies innovantes utilisant des avatars pour aider les patients… etc etc..
En plus de pouvoir contrôler la direction du regard, la distance de la tête et même les émotions du visage généré, VASA-1 est capable de gérer des entrées qui sortent complètement de son domaine d’entraînement comme des photos artistiques, du chant, d’autres langues…etc.
Bon, évidemment, il reste encore quelques limitations. Par exemple, le modèle ne gère que le haut du corps et ne prend pas en compte les éléments non rigides comme les cheveux ou les vêtements. De plus, même si les visages générés semblent très réalistes, ils ne peuvent pas encore imiter parfaitement l’apparence et les mouvements d’une vraie personne mais les chercheurs comptent bien continuer à l’améliorer pour qu’il soit encore plus versatile et expressif.
En attendant, je vous invite à checker leur page de démo pour voir cette merveille en action. C’est juste hallucinant ! Par contre, vu les problèmes éthiques que ça pourrait poser du style usurpation d’identité, fake news et compagnie, et connaissans Microsoft, je pense que VASA-1 ne sera pas testable par tous bientôt malheureusement. Mais je peux me tromper…
Vous avez enfin trouvé un peu de temps pour vous occuper de vos photos de vacances. Des milliers de clichés s’accumulent année après année sur votre disque dur. Quel bazar ! Rechercher une photo précise là-dedans risque de vous prendre des plombes. Pas cool… Heureusement, un petit outil bien pratique débarque à la rescousse : rclip, un outil en ligne de commande boosté à l’IA capable de rechercher vos photos par leur contenu visuel.
Développé à l’aide du réseau de neurones CLIP d’OpenAI, rclip permet de rechercher des images avec n’importe quelle requête texte. L’idée est simple mais diablement efficace : extraire des vecteurs caractéristiques de chaque image, stocker ces vecteurs, puis les comparer avec le vecteur de la requête pour trouver les photos les plus similaires. Et le tout en un clin d’oeil !
Pour l’installer, rien de plus simple. Sur Linux, un petit snap et c’est réglé.
sudo snap install rclip
Pour les autres OS, des options alternatives existent, comme une AppImage, une version Homebrew pour macOS ou un installeur .msi pour Windows. Si vous préférez passer par pip, c’est possible aussi. Pas d’excuse pour ne pas l’essayer !
Une fois installé, placez vous dans le répertoire contenant vos photos et lancez une recherche avec
rclip "ma requête"
Par exemple rclip "striped cat" pour dénicher les photos de votre félin préféré. À la première exécution, rclip va indexer vos images, ce qui peut prendre un certain temps selon la taille de votre photothèque (comptez environ 3h pour 1 million de photos sur un MacBook M1 Max). Mais ce n’est qu’un mauvais moment à passer, les recherches suivantes seront quasi-instantanées.
Au lieu d’une requête textuelle, vous pouvez aussi utiliser une image comme référence, en passant son chemin en paramètre :
rclip ./mon_image.jpg
Rclip trouvera alors les photos visuellement les plus proches de celle-ci. Puissant pour retrouver des clichés sur un même thème !
Cerise sur le gâteau, il est possible de combiner des requêtes texte et image avec des opérateurs + et -. Par exemple
rclip horse + strips
rclip apple - fruit
Vous pouvez même enchaîner les requêtes, du genre
rclip "./ma_voiture.jpg" - "sport car" + "snow"
pour trouver les photos de votre véhicule sous la neige, mais en excluant les bolides. Les possibilités sont quasi-illimitées.
L’affichage des résultats est également bien pensé. Si vous utilisez un terminal compatible comme iTerm2 ou Konsole, un simple rclip -p suffit pour prévisualiser les images directement dans la console. Avec d’autres terminaux, vous pouvez rediriger la sortie de rclip vers votre visionneuse préférée, par exemple
rclip -f -t 5 | feh -f - -t
pour afficher les 5 meilleurs résultats dans une jolie grille sous Linux.
En résumé, rclip est un outil à la fois pragmatique et fun qui révolutionne la façon dont on peut fouiller dans sa bibliothèque de photos. Fini les heures perdues à scroller frénétiquement à la recherche d’une image précise !
Si vous voulez tester rclip par vous-même, foncez sur son dépôt GitHub qui regorge d’infos. Son créateur y propose même des démos sur des jeux de données massifs, comme 1,28 million d’images ! De quoi vous convaincre de l’essayer sur vos propres photos.
Allez, c’est parti pour faire du tri dans votre bazar de photos !
Ça fait des années qu'on entend parler des deepfakes et des risques de l'IA générative. En ce début d'année et avec l'accessibilité de plus en plus grande des outils de deepfakes vocaux et visuels, beaucoup de charlatans tentent de les utiliser pour monter des business obscurs.
On fait le tour dans cette vidéo autour de 3 cas : leur utilisation dans les publicités, pour créer de faux contenus et les conséquences de ces technologies sur la vie des personnes. On conclut par une invitation à réfléchir sur notre rapport à la réalité.
SPONSO :
Merci à @Infomaniaknetwork de sponsorisé cette vidéo ! Découvre leurs solutions :
➡️ SwissTransfer, la meilleure alternative gratuite à WeTransfer : https://chk.me/ERBIpHr
➡️ L’IA générative souveraine pour créer vos applications : https://chk.me/hHriKdh
➡️ Lien vers la chaine secondaire : https://www.youtube.com/@defendoff-lachainesecondai7914
-----------
Merci à @notabenemovies et à Camille (https://twitter.com/Capxnce) pour leurs participation !
-----------
CHAPITRES :
00:00 : Introduction
01:49 : Les fausses pubs avec usurpation d'identité
03:47 : Sponso
04:49 : Que fait Meta pour lutter contre les deepfakes ?
07:35 : Les créations de contenus avec des deepfakes
08:32 : Interview @notabenemovies sur le compte d'IA qui lui a volé sa voix
10:39 : Le rôle des créateurs de contenus ?
12:07 : Faut il réguler ces outils ?
12:34 : Le danger de la création de deepfakes sur les personnes (Interview)
14:32 : La fabrique du doute généralisée
L'Ukraine déploie des drones capables d'aller de façon autonome à la recherche de cibles et de les abattre Dans un contexte de multiplications des appels à réglementer les usages de l'IA
Une vidéo du collecteur de fonds ukrainien Serhii Sternenko, publiée le 20 mars, présente un drone d'attaque doté d'un système de reconnaissance automatique de la cible qui vise un char d'assaut russe à longue distance. Même après la perte de la liaison vidéo, le drone réussit son attaque. Le tableau qui intervient...
Dans cette vidéo, je vous explique comment installer et utiliser l'application Applio (Sous Windows et Linux) afin de transformer une voix en une autre (clonage de voix par IA).
Merci aux Patreons pour le soutien.
★ POUR SOUTENIR LA CHAINE ★
Venez voir ce que je vous propose ici : https://patreon.com/korben
★ RETROUVEZ-MOI SUR TWITCH EN LIVE ★
Je fais également du live stream sur : https://twitch.tv/korbenfr
⚑ S'ABONNER A LA CHAINE ⚑
Si vous ne voulez pas rater les prochaines vidéos, n'hésitez pas à vous abonner, à cocher la cloche et tout le reste via http://www.youtube.com/subscription_center?add_user=Korben00
★★★ RETROUVEZ-MOI AILLEURS ★★★
Laissez un commentaire sur cette vidéo et j'essayerai d'y répondre. Ou vous pouvez également vous me retrouver sur différentes plateformes sociales :
Mon site : https://korben.info
Pour s'abonner au podcast : https://paralleles.org
Twitter : https://twitter.com/Korben
Instagram : https://www.instagram.com/korben00/
TikTok : https://www.tiktok.com/@korbeninfo
Facebook : https://www.facebook.com/ManuelDorne
La chaine YouTube Webosaures : https://www.youtube.com/channel/UCu34Tq5qMR-FiTYwLyy9U6w
✔ Liens mentionnés dans la vidéo ✔
https://docs.applio.org/
FeatUp, c’est le nom de ce nouvel algorithme révolutionnaire développé par une équipe de chercheurs du MIT dont le but consiste à faire passer la vision par ordinateur à la vitesse supérieure en lui offrant une résolution digne d’un œil de lynx.
Comment ça marche ? En gros, FeatUp s’attaque au problème de la perte d’information qui se produit quand les algorithmes d’IA analysent une image. Normalement, ils la découpent en une grille de petits carrés de pixels qu’ils traitent par groupe. Résultat, la résolution finale est bien plus faible que l’image de départ. Avec FeatUp, fini la myopie ! L’algo est capable de capter tous les détails, des plus évidents aux plus subtils.
La clé, c’est de faire légèrement bouger et pivoter les images pour voir comment l’IA réagit à ces micro-variations. En combinant des centaines de « cartes de caractéristiques » ainsi générées, on obtient un ensemble de données haute définition super précis. Un peu comme quand on crée un modèle 3D à partir de plusieurs images 2D sous différents angles.
Mais pour que ça turbine, il a fallu créer une nouvelle couche de réseau de neurones ultra-efficace, baptisée « suréchantillonnage bilatéral conjoint« . Grâce à elle, FeatUp améliore les performances d’un tas d’algos différents, de la segmentation sémantique à l’estimation de profondeur.
Les applications potentielles sont dingues : imaginez pouvoir repérer un minuscule panneau sur une autoroute encombrée pour une voiture autonome, ou localiser précisément une tumeur sur une radio des poumons. Avec sa capacité à transformer des suppositions vagues en détails précis, FeatUp pourrait rendre tous ces systèmes bien plus fiables et sûrs.
L’objectif des chercheurs, c’est que FeatUp devienne un outil fondamental du deep learning, pour enrichir les modèles sans sacrifier l’efficacité. Comme le résume Mark Hamilton, co-auteur de l’étude, l’enjeu est d’obtenir « le meilleur des deux mondes : des représentations très intelligentes avec la résolution de l’image d’origine« .
Bref, si FeatUp tient ses promesses, on n’a pas fini d’entendre parler de cette prouesse technologique qui pourrait donner un sacré coup de boost à l’IA visuelle puisqu’elle fournit des versions haute résolution d’analyses d’images qu’on pensait jusque-là limitées à la basse résolution. »
Stability.ai présente Stable Video 3D, un outil d'IA générative pour le rendu de vidéos en 3D, qui permet aux utilisateurs de générer une courte vidéo à partir d'une image ou d'un texte.
Stability.ai lance Stable Video 3D (SV3D), un modèle génératif basé sur Stable Video Diffusion, qui fait progresser le domaine de la technologie 3D et offre une qualité et une cohérence de vue grandement améliorées. Cette version permet de générer des vidéos orbitales à partir d'une seule image sans conditionnement...
Aujourd’hui, j’aimerais vous présenter LocalAI, une alternative open source à OpenAI. En tout cas, c’est comme ça que le créateur du projet le présente. Il s’agit d’une solution idéale pour tous ceux qui cherchent une API REST compatible avec les spécifications de l’API OpenAI pour l’inférence locale.
Grâce à LocalAI, vous pouvez exécuter des modèles linguistiques, générer des images, de l’audio et bien d’autres choses encore, localement ou sur site avec du matériel grand public, et ce, sans avoir besoin d’un GPU ! Le projet a pour principal objectif de rendre l’IA accessible à tous.
Pour résumer, voici les principales caractéristiques de LocalAI :
Une API REST locale, alternative à OpenAI. Comme ça, vous gardez bien au chaud vos propres données.
Pas besoin de GPU. Pas besoin d’accès internet non plus. Toutefois, l’accélération GPU est possible en option.
Prise en charge de plusieurs modèles.
Dès qu’ils sont chargés une première fois, les modèles restent en mémoire pour une inférence plus rapide.
N’utilise pas de shell, mais des liaisons directes pour une inférence plus rapide et de meilleures performances.
En termes de fonctionnalités, LocalAI offre une large gamme d’options, parmi lesquelles :
La génération de texte avec les modèles GPT (comme llama.cpp ou gpt4all.cpp).
La conversion de texte en audio.
La transcription audio en texte avec whisper.cpp.
La génération d’images avec Stable Diffusion.
Les dernières fonctionnalités d’OpenAI récemment ajoutées comme l’API Vision par exemple.
La génération d’embeddings pour les bases de données vectorielles.
Le téléchargement de modèles directement à partir de Huggingface.
LocalAI est bien sûr un projet communautaire donc n’hésitez pas si vous souhaitez vous impliquer !
Pour commencer rapidement avec LocalAI, vous pouvez consulter leur guide Getting Started qui décrit les différentes méthodes d’installation et les exigences matérielles ou aller consulter les guides de la communauté. Je vous ferais aussi probablement un tutoriel prochainement si mon emploi du temps me le permet.
LocalAI est disponible sous forme d’image conteneur et de binaire, compatible avec divers moteurs de conteneurs tels que Docker, Podman et Kubernetes. Les images de conteneurs sont publiées sur quay.io et Docker Hub, et les binaires peuvent être téléchargés à partir de GitHub.
Concernant les exigences matérielles, ça varie en fonction de la taille du modèle et de la méthode de quantification utilisée mais pour choper quelques repères de performance avec différents backends, comme llama.cpp, vous pouvez consulter ce lien.
Maintenant pour en savoir plus, vous pouvez explorer le site localai.io. Vous y trouverez de nombreuses informations et des exemples d’utilisation pour vous aider à tirer le meilleur parti de LocalAI.
Dans cette vidéo, comment bénéficier de la plupart des innovations de l'IA, que ce soit pour du LLM, du text-to-image, de l'upscale créatif et bien d'autres choses encore, sans machine dédiée, sans attendre des heures, en utilisant des cartes très puissantes et tout cela pour un coup dérisoire !
Oui, vous pourrez par exemple passer d'une image moyenne à une image ultra-HD et très détaillée, sans installer quoi que ce soit, sur une tablette et pour quelques centimes en utilisant une carte à 20000 euros,
Et si vous êtes un peu développeur, vous aurez aussi de quoi vous amuser, vous allez voir c'est une vraie mine d'or !
Si ça vous intéresse !
📑 Chapitres :
00:00 Introduction
01:51 Présentation de Replicate et inscription
05:14 Le modèle Face To Many sur Replicate.com
09:30 Le modèle Face To Sticker sur Replicate.com
11:57 Le modèle Clarity Upscaler sur Replicate.com
19:44 Wallpaperai.io
18:20 Le modèle Multidiffusion Upscaler sur Replicate.com
22:30 Conclusion
📑 Liens relatifs à cette vidéo :
https://replicate.com/fofr/face-to-many
https://replicate.com/fofr/face-to-sticker
https://replicate.com/philipp1337x/clarity-upscaler
https://wallpaperai.io/
Mon matériel :
★ https://www.amazon.fr/shop/johansolutionsdigitales
★ Mon appareil photo : Sony A6000 https://amzn.to/2KSNjso
★ L'objectif que j'utilise : Sigma 30mm 1.4 DC DN Contemporary https://amzn.to/39mmxSJ
✅ Accélérez ma production de vidéo sur la chaine :
https://fr.tipeee.com/johan-solutions-digitales/
✅ Pour réserver un conseil ou accompagnement actif en visio : https://www.directsolutions.fr/
Abonnez-vous et commentez
Retrouvez-moi aussi sur
✅ Le groupe Facebook de la chaîne : https://www.facebook.com/groups/396113454680595
✅ Mon instagram : https://www.instagram.com/jpuisais/
✅ Mes photos gratuites sur Pixabay : https://pixabay.com/fr/users/xtendo-1194315/
✅ Mon Twitter : https://twitter.com/mrgris
✅ Mon (vieux) site : http://www.johanpuisais.com/
Quelle sera notre expérience de l'intelligence artificielle dans l'avenir, seront nous toujours obligés d'être connecté pour bénéficier de l'IA ? Hébergement Web avec Hostinger 👉 https://hostinger.fr/johan
Et bien des puces d'une conception totalement nouvelles sont en cours de développement, et elles promettent de tout changer en termes de rapidité, de consommation d'énergie et de coûts !
Par ailleurs, ces IA resteront-elles des outils neutres qui se conforment à nos demandes ou bien disposeront-elles de leurs propres personnalités, seront-elles capables d'empathie, de devancer nos attentes ?
Une chose est sûre, certaines équipes qui développent de nouveaux modèles actuellement ont choisi cette voie, et vous le verrez, avec un vrai succès, vous pourrez même l'utiliser !
Vous avez été nombreux à me signaler votre intérêt pour TripoSR qui permet de générer des objets 3D à partir d'une simple image, je vous donnerai une alternative en ligne !
Et puis en attendant Sora, si vous souhaitez générer des vidéos par IA, j'aurais quelque chose à vous montrer, vous pourrez également tester cela gratuitement en ligne !
💻 Votre hébergement web sur : https://www.hostinger.fr/johan avec le code "JOHAN"
📑 Chapitres :
00:00 Introduction
01:49 Intelligence artificielle : des puces pour l'avenir
04:36 Inflection 2.5 : l'IA qui a de l'empathie
05:24 Test et utilisation de PI et du modèle IA Inflection 2.5
09:45 L'assistant IA de Hostinger le sponsor de cette vidéo
11:34 Générer un contenu sur WordPress avec l'assistant IA Hostinger
14:22 De la 3D à partir d'une image avec TripoSR en ligne
15:37 Text to Vidéo avec Haiper.ai en attendant Sora
19:40 Conclusion
Mon matériel :
★ https://www.amazon.fr/shop/johansolutionsdigitales
★ Mon appareil photo : Sony A6000 https://amzn.to/2KSNjso
★ L'objectif que j'utilise : Sigma 30mm 1.4 DC DN Contemporary https://amzn.to/39mmxSJ
✅ Accélérez ma production de vidéo sur la chaine :
https://fr.tipeee.com/johan-solutions-digitales/
✅ Pour réserver un conseil ou accompagnement actif en visio : https://www.directsolutions.fr/
Abonnez-vous et commentez
Retrouvez-moi aussi sur
✅ Le groupe Facebook de la chaîne : https://www.facebook.com/groups/396113454680595
✅ Mon instagram : https://www.instagram.com/jpuisais/
✅ Mes photos gratuites sur Pixabay : https://pixabay.com/fr/users/xtendo-1194315/
✅ Mon Twitter : https://twitter.com/mrgris
✅ Mon (vieux) site : http://www.johanpuisais.com/
OpenAI Sora est un nouveau modèle de génération de vidéos par IA. Mais il n'est pas seul. D'où viennent les IA vidéos ? Comment ca marche ? Et au delà de jsute générer de la vidéo que nous cache vraiment ces IAs ? Sans doute une nouvelle porte vers l'Intelligence Artificielle Générale.
Rejoins moi sur Twitch : https://www.twitch.tv/defendintelligence
00:00 Les premieres entreprises d'IA vidéos.
02:18 : La véritable naissance des IA de génération de vidéos.
04:22 : Les modèles des géants de la tech passé inapercu (Tiktok, Google, Meta, Nvidia)
05:32 : Introduction de OpenAI Sora
07:48 : Comment fonctionne ces IA pour générer des vidéos ? (Transformers Vidéos et Diffusion)
13:01 : Les incroyables capacité de OpenAI Sora
15:01 : Les aspects éthiques dans tout ca ?
17:03 : La véritable révolution de ces modèles d'IA !





































")
