BadHost - Un caractère et votre agent IA passe à l'ennemi
Les chercheurs de X41 D-Sec viennent de divulguer une faille critique baptisée BadHost (CVE-2026-48710) dans Starlette, le framework Python qui sert de fondation à FastAPI, vLLM , LiteLLM et une grande partie des serveurs MCP basés sur FastAPI.
325 millions de téléchargements par semaine, et il suffit d'injecter un seul caractère dans le header HTTP "Host" pour contourner les contrôles d'accès path-based qui lisent "request.url.path" dont autant dire que beaucoup de déploiements d'agents IA en production tournent en ce moment avec une porte d'entrée très mal verrouillée.
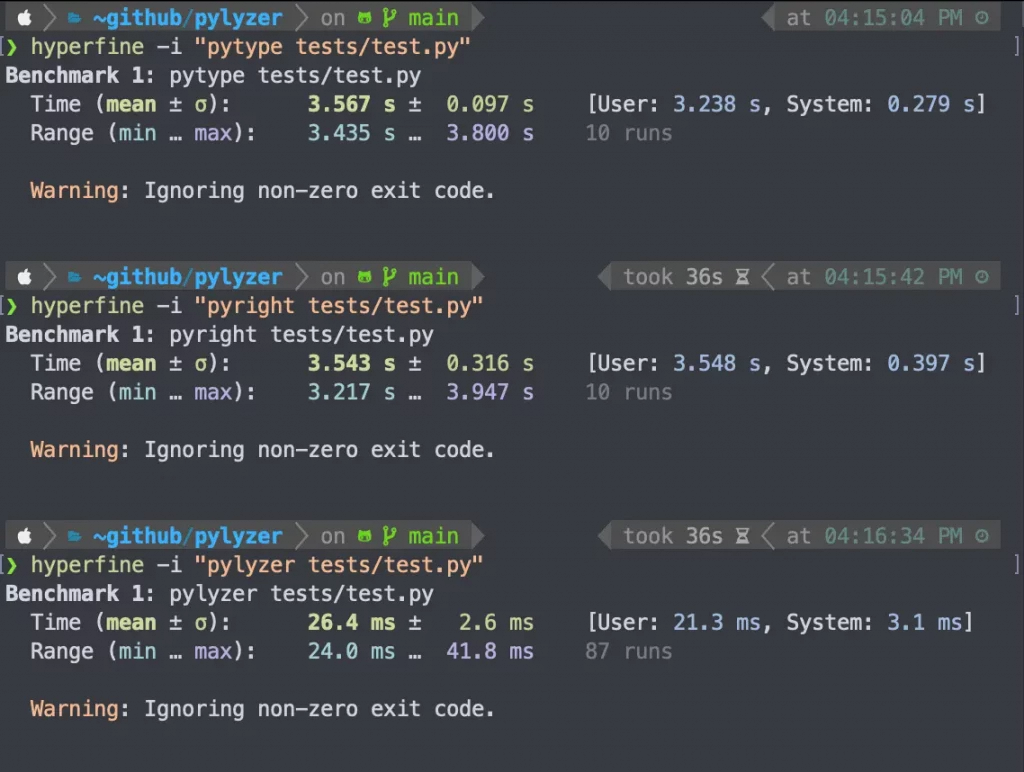
Le proof of concept publié par OSTIF donne ceci :
curl -i -H 'Host: foo' http://target/admin # 403, bloqué
curl -i -H 'Host: foo?' http://target/admin # 200, ça passe !!
Et c'est tout ! Un simple point d'interrogation collé au Host header, et l'endpoint "/admin" qui jusqu'alors filtrait les non-authentifiés s'ouvre alors aussi facilement que le claque-merde de mes haters ^^.
Donc si votre infra utilise FastAPI, vLLM ou LiteLLM exposés directement en ASGI (uvicorn, hypercorn, granian) sans reverse proxy strict devant, vous pouvez tester votre exposition immédiatement grâce au scanner de BadHost développé par Nemesis et X41 D-Sec.

Niveau mécanique, Starlette reconstruit l'objet "request.url" en concaténant la valeur du header "Host" avec le path de la requête, puis re-parse le tout. Sauf que la valeur de "Host" n'est jamais validée donc si vous y injectez un "/", un "?" ou un "#", vous décalez la frontière entre path, query et fragment au moment du re-parse.
Du coup, le routeur Starlette dispatche sur le vrai path de la requête HTTP (donc votre endpoint sensible s'exécute bien), mais les middlewares qui lisent "request.url.path" voient simplement un path empoisonné qui ne correspond plus à rien d'interdit.
Donc le contrôle d'accès saute et le code derrière tourne quand même. On est sur un score CVSS de 7/10 et la boite de sécu Secwest estime même que cette note est largement sous-estimée... En gros c'est super grave !
Car la portée réelle ce sont surtout les serveurs MCP qui peuvent stocker ou manipuler des tokens et identifiants pour accéder aux ressources externes auxquelles les agents IA se connectent : bases de données, comptes mail, calendriers, S3, webhooks...etc
Bref, le genre de "coffre-fort" que vous ne voulez pas voir ouvert via un header HTTP à la con malformé. Markus Vervier de X41 D-Sec a même publié un petit échantillon de ce que leurs scanners ont déjà trouvé en production : Des bases de données d'essais cliniques chez des biopharmas, des données de vérification d'identité avec PII en temps réel, des accès SSH à des équipements industriels via bastion, des boites mails complètes en lecture/écriture, des listes de souscripteurs CMS, des topologies AWS complètes avec metric queries.
Bref, l'écosystème agents IA vient de passer en mode naturiste !
Pour régler ce problème, vous devez donc mettre à jour vers Starlette 1.0.1 ou supérieur, dans tous vos déploiements LLM qui l'intègrent... Et là c'est le bordel parce qu'il y en a partout : Dans les images Docker, les virtualenvs et les artefacts "vendorisés" un peu partout... Donc faut tout rebuilder.
Et si vous avez du code custom, l'OSTIF recommande aussi de remplacer request.url.path par request.scope["path"] partout où une décision de sécurité est prise.
En gros, lire la valeur non reconstruite est le "fix" qui survivra aux prochaines versions du bug, parce que croyez-moi, ça reviendra à coup sûr !
Maintenant, côté infra, X41 D-Sec et OSTIF indiquent que nginx, Apache httpd et Cloudflare rejettent le PoC par défaut, mais ça ne doit pas vous empêcher de vérifier votre config. Donc ne traitez votre reverse proxy comme une mitigation qu'après l'avoir testé explicitement avec le scanner Nemesis.
Au-delà du correctif technique, BadHost rappelle une mécanique qu'on a déjà vue avec la faille RCE de llama-cpp-python à savoir que la chaîne d'approvisionnement de l'IA ne tient que sur quelques mainteneurs bénévoles qui prennent des risques personnels énormes pour patcher proprement.
Kludex, le mainteneur de Starlette, est actuellement sous une avalanche de reports depuis des mois. L'audit qui a permis de trouver le bug a par ailleurs été financé par OSTIF et AWS et sans ça, BadHost serait encore probablement dans la nature pour un an voire plus avant d'être découvert plus naturellement.
Donc si votre boîte fait tourner du LLM en prod via FastAPI, vLLM ou LiteLLM, vous avez aujourd'hui 2 choses urgentes à faire : 1/ passer votre infra dans le scanner Nemesis, et 2/ envoyer un petit don à Kludex pour le soutenir !
Sources : Ars Technica , OSTIF