Sommaire
(NdM: dans la suite, l'auteur du journal à l’origine de la dépêche s'exprime à la première personne)
Pour avoir un aperçu plus global de l'écosystème, veuillez faire une petite recherche sur GitHub, surveillez reddit/r/lisp et reddit/r/common_lisp, utilisez un moteur de recherche, ou commencez par jeter un coup d’œil sur la liste awesome-cl.
Il me tient à cœur de faire cette liste, car de l’extérieur on ne se rend pas forcément compte à quel point, certes, le langage et l’écosystème sont stables, mais qu’ils évoluent également.
S’il fallait en choisir trois, je mettrais ces travaux en avant :
- je suis impressionné par tout ce qui se passe autour de l’implémentation SBCL (et des travaux en cours sur ECL et ClozureCL)
- j’adore l’éditeur Lem, et suis également impressionné par tous les modules qu’il comporte déjà, par la qualité de sa base de code et par la facilité avec laquelle on peut l’explorer, ce qui est aussi rendu facile par l’interactivité du langage
- plusieurs outils pour écrire et exécuter des scripts plus rapidement que d’habitude émergent, et sont nécessaires à mon avis.
Bonne découverte.

Hacker News est passé de Racket à Common Lisp (SBCL)
C’est une nouvelle plutôt cool pour nous les publicitaires pro du langage. HN a été développé avec le dialecte de Lisp Arc, initialement implémenté avec Racket, et pour des questions de performance ils l’ont ré-implémenté en Common Lisp, avec SBCL.
Pour plus de contexte : Paul Graham (avec Robert Morris) crée Viaweb en 1995, le premier fournisseur d’applications en ligne (pour garder la terminologie de Wikipédia, page Paul Graham), développé en Common Lisp, avec l’implémentation CLisp. Cette implémentation existe toujours et est légèrement développée, mais il est généralement conseillé d’utiliser SBCL (qui colle mieux au standard, qui est plus performante, qui donne plus d’indications de typage pendant le développement, etc.). “PG” vend Viaweb à Yahoo en 1998 (pour ce qui devient Yahoo! Store), et fonde l’incubateur de start-ups YCombinator. PG n’était pas satisfait par Common Lisp, au tout au moins (là, je n’ai pas les sources) voulait un dialecte plus succinct, qui permette d’écrire des applications web de manière plus compacte. Il ébauche un dialecte de Lisp, appelé Arc, et l’implémente avec Racket (MzScheme à l’époque). Le site de Hacker News (géré par YCombinator) fut donc écrit en Arc avec cette première implémentation.
Le responsable (ou un des responsables) du portage vers SBCL et modérateur d’Hacker News, dang, explique :
[Clarc, l’implémentation en Common Lisp] est beaucoup plus rapide et permet de faire tourner HN sur plusieurs cœurs. Ça a été un travail de fond de quelques années, principalement parce que je ne trouve pas le temps pour travailler dessus.
Les sources du site d’HN ne seront pas publiées pour ne pas dévoiler de multiples mécanismes anti-spam et anti-abus (les séparer du code source serait « beaucoup de travail »), mais les sources de Clarc pourraient l’être, avec un peu plus d’efforts pour les séparer du code d’HN.
https://lisp-journey.gitlab.io/blog/hacker-news-now-runs-on-top-of-common-lisp/
C’est quoi Common Lisp ?
C’est un langage multi-paradigmes, et selon les implémentations, comme avec SBCL : compilation en code machine très performant, typage graduel, très interactif :
- débogueur interactif, permet de corriger une fonction, de la re-compiler et de reprendre l’exécution depuis la fonction boguée, sans devoir tout relancer de zéro (démo youtube)
- ne perd pas l’état du programme en cours quand on travaille avec un bon éditeur
- permet même de contrôler comment des instances sont mises à jour lorsque la définition d’une classe change (pas forcément utile pour le quotidien on est d’accord, encore que, quand on sait le faire on en tire parti, mais c’est pensé pour les systèmes à longue durée de vie, qu’on peut patcher pendant qu’ils tournent),
- un REPL avec beaucoup de fonctionnalités (ne redémarre jamais, on peut installer des bibliothèques depuis le REPL), extrêmement utile et satisfaisant en tant que développeur (j’en ai toujours un d’ouvert),
- on compile fonction par fonction avec un raccourci clavier, SBCL nous donne beaucoup de warnings et d’erreurs de typage instantanément (et pour du Haskell intégré dans Common Lisp, cf. Coalton ci-dessous).
Définir une fonction :
(defun hello ()
(print "hello!"))
;; Appeler la fonction:
(hello)
Compiler la fonction :
- soit
C-c C-c depuis tout bon éditeur, sans quitter le programme, sans redémarrer quoi que ce soit,
- soit
C-c C-k depuis l’éditeur, pour re-compiler le fichier,
- soit
sbcl --load hello.lisp depuis la ligne de commande (ce qu’on va donc faire rarement, seulement de temps en temps pour vérifier que ça passe, pour construire un binaire, pour déployer depuis les sources…)
Liens :
La communauté
Elle est active, il y a des évènements IRL réguliers dans quelques villes, l’European Lisp Symposium chaque année…
On peut voir les chiffres de la communauté reddit/r/common_lisp (plus petite que le plus général “lisp”),
La communauté est présente sur reddit, Discord (lien: https://discord.gg/hhk46CE), IRC, Mastodon, LinkedIn…
Documentation
On a la chance d’avoir de très bons livres sur CL, mais historiquement peu de doc en ligne. Ça évolue.
Les spécifications du langage ont été portées vers des sites beaucoup plus sympas à l’utilisation que le site de référence, comme le Common Lisp Community Spec, site également publié sous licence libre,
Le Common Lisp Cookbook reçoit un bon nombre de contributions. On peut le trouver en EPUB : https://github.com/LispCookbook/cl-cookbook/releases/tag/2025-01-09
Le livre PAIP est maintenant disponible en ligne : https://norvig.github.io/paip-lisp/#/
J’ai sorti un nouveau site sur le développement web en Common Lisp : https://web-apps-in-lisp.github.io/index.html
FreeCodeCamp a publié un cours “complet” sur Youtube : https://www.reddit.com/r/Common_Lisp/comments/1i1e766/lisp_programming_language_full_course_for/
cf. d’autres vidéos sympas ici : https://www.cliki.net/Lisp%20Videos
J’ai sorti neuf vidéos (1h22) pour expliquer CLOS, le système objet : https://lisp-journey.gitlab.io/blog/clos-tutorial-in-9-videos-1h22min--read-the-sources-of-hunchentoot-and-kandria/
Les implémentations
Il s’en passe des choses.
SBCL
SBCL a toujours des sorties mensuelles : https://www.sbcl.org/news.html
SBCL s’est vue dotée d’un nouveau GC.
Entre autres choses, rapidement :
- appeler SBCL comme une bibliothèque partagée depuis C ou Python, avec sbcl-librarian (par les mêmes personnes derrière Coalton) (recette sur le Cookbook),
- compilation croisée pour Android
- support pour Haiku
- « memory allocation arenas » pour arm64
- améliorations du module sb-simd
- SBCL est porté pour la Nintendo Switch, pour les besoins du jeu Kandria (cf plus bas)
- installation facile sur Windows avec Chocolatey (non officiel)
- ou des builds quotidiens pour MSYS2
ABCL - CL pour Java
ABCL a sorti des nouvelles versions :
Et Clojure ? Je ne connais qu’à peine (ça reste du Java, ça reste gourmand en ressources, le REPL est moins riche en fonctionnalités, le langage ne donne pas d’erreurs de type à la compilation avec un C-c C-c), donc je peux juste citer d’autres lispers. cf. :
CCL, LispWorks, Allegro, ECL, CLASP, SICL, LCL, Alisp, Medley
Ces implémentations sont actives.
ECL a un module pour WASM, en cours de développement mais qui permet déjà de lancer Maxima, un logiciel de calcul formel, dans un navigateur.
Breaking news: ECL vient d'être accepté par NLNet pour justement travailler sur ce module.
Pour info, on peut également utiliser Maxima via SageMath, avec KDE Cantor, avec l'interface graphique wxMaxima, sur Android, dans un "notebook" Jupyter, via Emacs avec le paquet "maxima-mode", et on peut faciliter son utilisation depuis un REPL Common Lisp et avec maxima-interface.
CLASP, pour interfacer CL et C++ nativement, est toujours développé par une start-up en bio technologies :
SICL est peut-être le futur de Common Lisp. C’est une nouvelle implémentation, modulaire. Des bouts sont déjà utilisés dans d’autres implémentations.
Medley est la ré-incarnation de la Medley Interlisp Lisp Machine. Je ne l’ai pas connue, trop jeune. On peut la tester via un navigateur.
LCL pour Lua Common Lisp est une nouvelle implémentation, Alisp est une nouvelle implémentation en cours de développement (en C).
Industrie, offres d’emplois
Il y a peu d’offres, publiques en tout cas, on voit des opportunités passer de manière moins formelle sur les réseaux. Mais il y en a (cf. le lien original, par ex. une offre pour 3E à Bruxelles).
Et oui, certaines entreprises utilisent toujours Common Lisp, et certaines entreprises choisissent de leur plein gré ce langage comme base de leurs nouveaux produits. On le voit surtout dans le domaine de l’informatique quantique, et toujours pour une certaine forme d’IA. Mais des boîtes plus classiques peuvent en tirer parti. On voit des logiciels de management de projet (Planisware, cocorico c’est une boîte française, développé avec l’implémentation Allegro), du développement web, des bots internet…
Quelques exemples :
et des usages, moins dans l’actualité :
Projets cools
Éditeurs
Éditeurs pour Lisp : https://lispcookbook.github.io/cl-cookbook/editor-support.html (il y en a d’autres qu’Emacs, mais essayez donc !)
Lem : https://lem-project.github.io/
Construit en CL, il est donc extensible à la volée en Lisp, comme Emacs. Contient un client LSP qui fonctionne pour de nombreux autres langages, et des modes syntaxiques plus classiques pour nombre d’autres.
Quelques fonctionnalités de Lem :
- mode vim et Emacs
- interface Git interactive (opérations classiques, rebase interactive (sans les actions “edit” ou “reword”))
- navigateur de fichiers
- panneau de navigation
- terminal via libvterm
- curseurs multiples
- pour le terminal (ncurses) et le bureau (SDL2), et une version “cloud” pour édition collaborative en chantier.
- Tetris (en mode graphique)
Nouveau projet : Neomacs https://github.com/neomacs-project/neomacs basé sur Electron
Coalton : comme Haskell, pour Common Lisp
En les citant, Coalton c’est :
the implementation of a static type system beyond Haskell 95. Full multiparameter type classes, functional dependencies, some persistent data structures, type-oriented optimization (including specialization and monomorphization). All integrated and native to CL without external tools.
C’est une bibliothèque logicielle qu’on installe comme n’importe quelle autre, mais qui fournit un autre langage pour écrire des programmes typés statiquement, tout en s’interfaçant de manière native avec son langage hôte.
Coalton est développé à l’origine pour des boîtes dans l’informatique quantique. Cf le compilateur quilc.
Ce n’est donc pas un jouet. Et si les développeurs ne font pas un tonnerre de tous les diables pour montrer leur travail incroyable, c’est qu’ils bossent ;) (mais ils répondront au FUD sur HN).
Les gestionnaires de bibliothèques
Depuis au moins 10 ans, le « package manager » qui rend de fidèles services est Quicklisp. Il sort des distributions de bibliothèques, qui ont été vérifiées pour charger correctement. La dernière en date était en octobre :
Et oui, elle date un peu. Plusieurs explications à cela, à lire et discuter par ailleurs.
Aujourd’hui, de nouveaux outils émergent:
Développement de jeux
Le meilleur exemple dans ce domaine est Kandria, qui est sorti sur Steam :
- https://kandria.com/
-
retours d’expérience (anglais): où oui, Common Lisp (ici SBCL) est assez performant pour faire tourner un jeu, y compris sur la Nintendo Switch, à condition de surveiller la création d'objets en mémoire.
Son auteur augmente maintenant son moteur de jeu pour la 3D. On peut le suivre et voir une démo sur Mastodon.
On trouvera d’autres ressources, par exemple :
Une fonctionnalité incroyablement utile pour les développeurs, est qu’on peut développer son jeu pendant qu’il tourne. Compiler une fonction avec C-c C-c, et voir le jeu changer. Sans tout relancer de zéro à chaque fois.
La communauté organise 2 fois par an des « Lisp Game Jam ». Où tous les dialectes de Lisp sont permis ;)
Interfaces graphiques
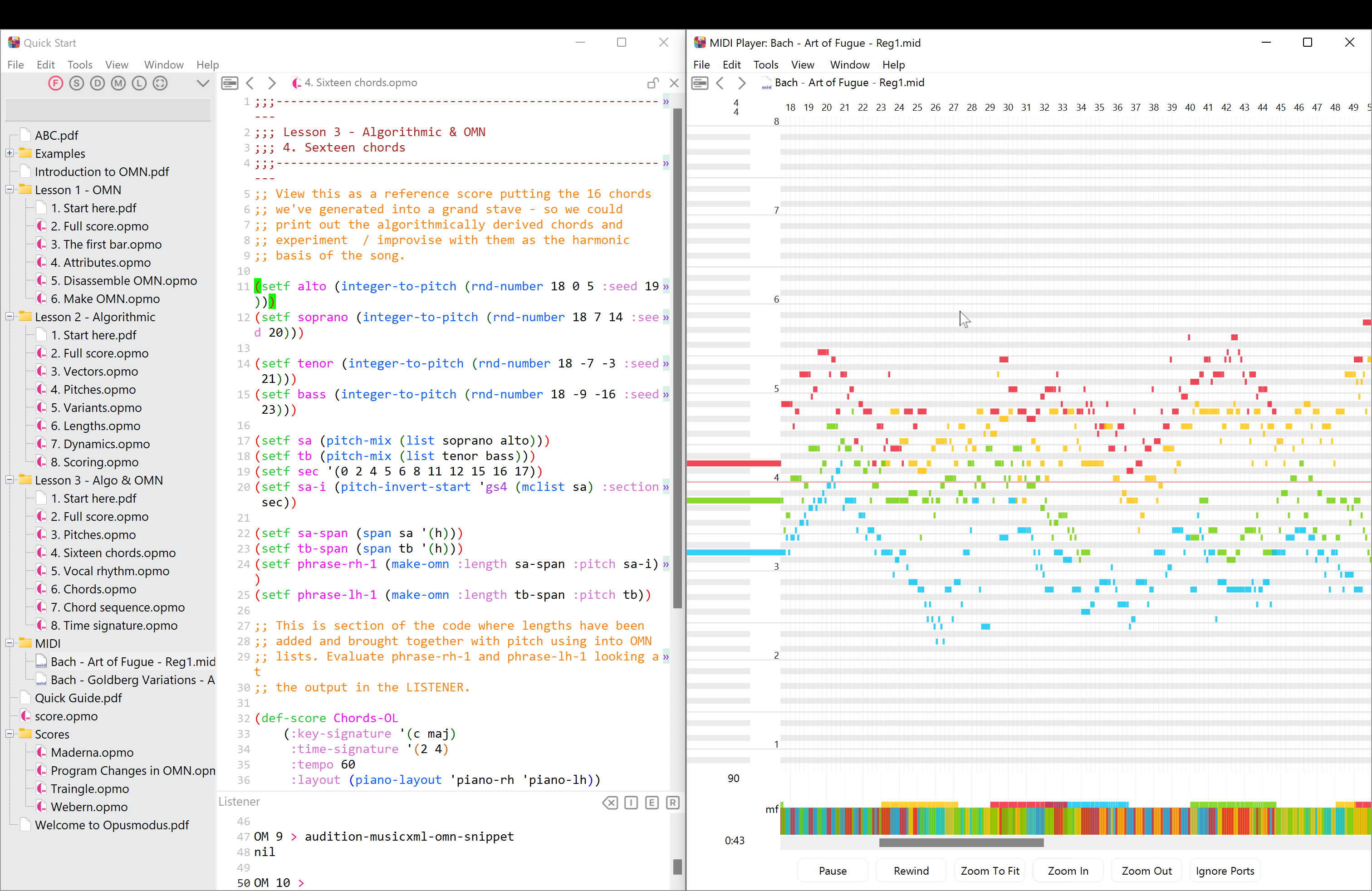
C’est un large sujet, et de multiples bibliothèques existent, plus ou moins faciles à prendre en main, plus ou moins portables, etc. Mais voyez la capture d’écran d’Opus Modus en introduction : c’est bien un logiciel graphique multi-plateformes. Dans ce cas, développé avec LispWorks. Par ailleurs, LispWorks possède un “runtime” pour Android et iOs.
Je vais vous laisser voir awesome-cl ou l’article original.
Le web, les web views, Electron
Le web en Common Lisp c’est faisable (et je le fais), on a pas mal de bibliothèques pour divers besoins, on a quelques “frameworks”, minimalistes. Il faut être prêt à mettre les mains dans le cambouis, à mieux connaître le web que lorsqu’on utilise des “frameworks” de haut niveau qui ont beaucoup de couches d’abstraction. Ceci dit, la malléabilité du langage, sa performance, son multi-threading, ses excellents outils de développement, ses fonctionnalités avancées, son déploiement facile… font que certaines choses compliquées dans un autre langage, ou qui nécessiteront une bibliothèque, se font en quelques lignes de manière native.
Ce qui me plaît, c’est la stabilité du langage et de l’écosystème, l’efficience des programmes (de l’ordre de C ou Java, une comparaison parmi d'autres, retours à trouver dans ses articles postérieurs et sur HN), et encore et toujours l’interactivité pendant le développement, le fait que le serveur de développement ne redémarre jamais, ne me fait pas attendre et reste réactif, et comme je disais plus haut le déploiement d’applications, facile : je peux générer un binaire de mon appli web, comprenant tous les fichiers statiques (templates HTML, le JavaScript, etc), le copier sur mon serveur, et c’est tout. Ou le vendre et ne pas devoir accompagner mon client pendant l’installation.
C’est ce que dit aussi l’auteur de Screenshotbot (projet open-source d’automatisation de prise de captures d’écran). Quand sa concurrence fait installer ses solutions via npm, il livre un petit binaire qui fait tout. Et j’ai bien dit petit, donc ±10Mo pour le projet et toutes ses dépendances, car il utilise LispWorks, qui permet d’enlever le code mort de l’image finale, alors que SBCL ne permet pas (encore ?) cela et les binaires pèsent ±30Mo compressés, 80Mo non compressés. Néanmoins, un binaire (compressé) de 30Mo (c’est le cas pour une application à moi qui inclue une douzaine de dépendances) contient le débogueur, le compilateur… ce qui permet de se connecter à une application pendant qu’elle tourne et de charger du code à la volée. On peut s’en servir pour observer ce qu’il se passe autant que pour faire des mises à jour. Au choix ! Mais oui, on peut garder les bonnes pratiques de l’industrie.
Pour démarrer sur le sujet :
Comme outils moins classiques, on a CLOG (CL Omnificient GUI), qui permet le développement d’applications web un peu comme une interface graphique, avec une grande interactivité pendant le développement (via websockets).
L’infatigable lisper @mmontone se lance dans mold-desktop, un desktop pour le web, en suivant les principes de « moldable software ».
Enfin, un article pour présenter les trois « web views » pour Common Lisp: webview, webui, Electron. On peut délivrer une application multi-plateformes écrite avec les technologies du web.
Scripting
En Common Lisp peut lancer un programme depuis les sources, ou bien générer un exécutable.
Mais, par défaut, l’un ou l’autre sont un peu lourds à l’usage et ne satisfont pas vraiment le développeur pressé qui souhaite lancer un petit script écrit en Lisp. C’est aussi un peu pour cela qu’on reste tant dans le REPL, où toute procédure une fois définie est instantanément appelable. On n’a pas véritablement besoin de passer par le terminal.
Mais des projets élargissent les possibilités.
kiln: « Infrastructure for scripting in Common Lisp to make Lisp scripting efficient and ergonomic » - soit, pouvoir appeler du Lisp depuis le shell de manière légère.
unix-in-lisp - il paraît fou ce projet : on “monte” les utilitaires Unix dans son image Lisp.
CIEL Is an Extended Lisp (discussion HN) - 100% Common Lisp, « batteries included »
- une collection de bibliothèques pour rendre CL plus utile au quotidien aujourd’hui : inclue des bibliothèques pour le JSON, le web, le CSV, les expressions régulières…
- un moyen de lancer des scripts au démarrage rapide et sans étape de “build”, avec toutes les bibliothèques à disposition.
Vidéos
Voici une petite sélection.
Des démos d’applications :
Apprendre :
De l’European Lisp Symposium 2024 :
Conclusion
C’était un compte-rendu écourté qui vous aura, je l’espère, donné envie d’en voir plus.
En Common Lisp on s’éclate ET on délivre du logiciel, ce qui n’est pas donné à tout le monde ;)