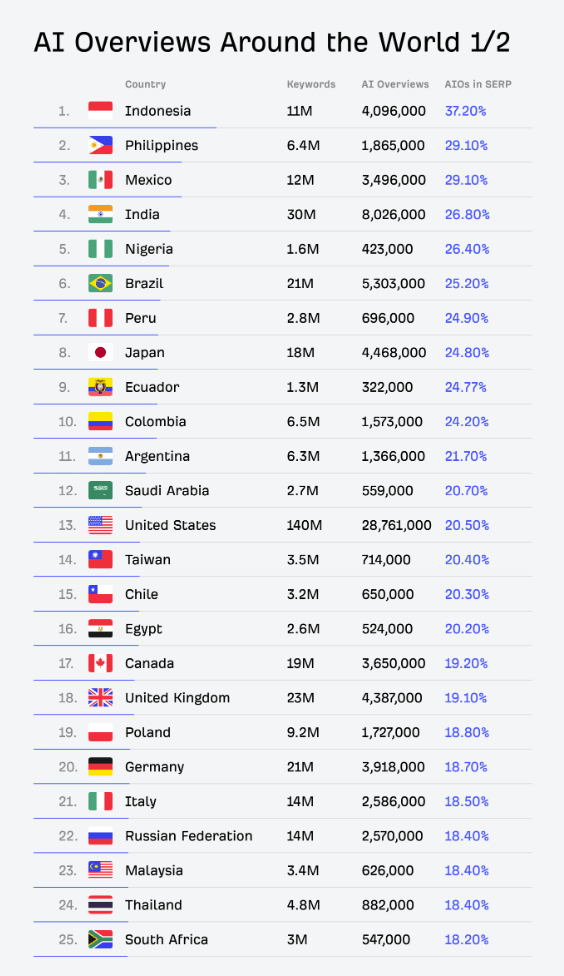
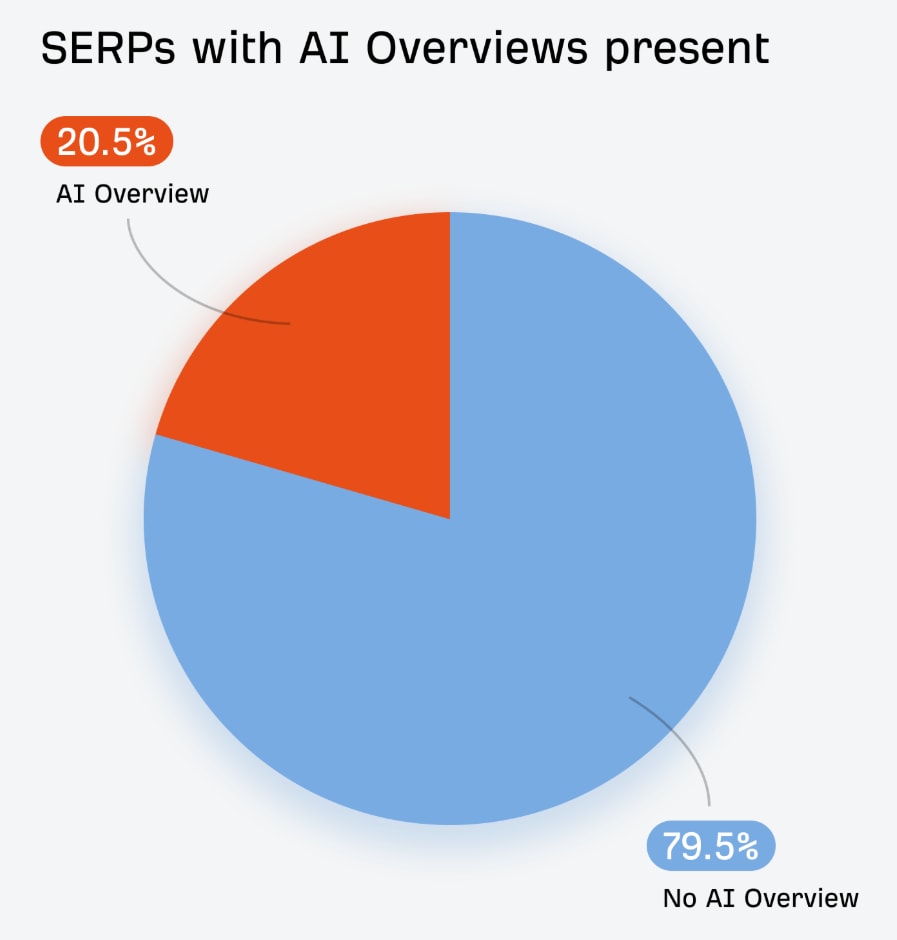
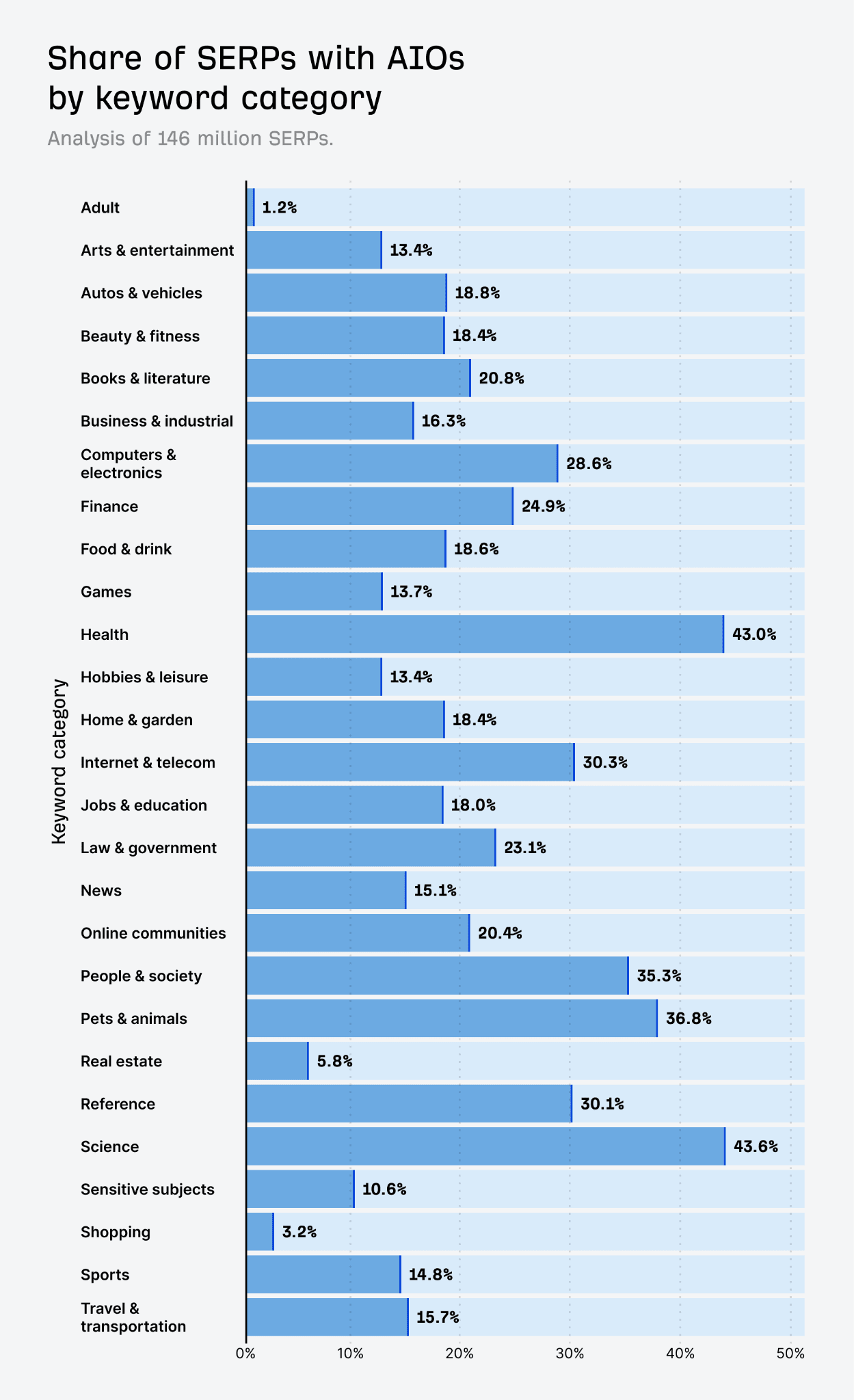
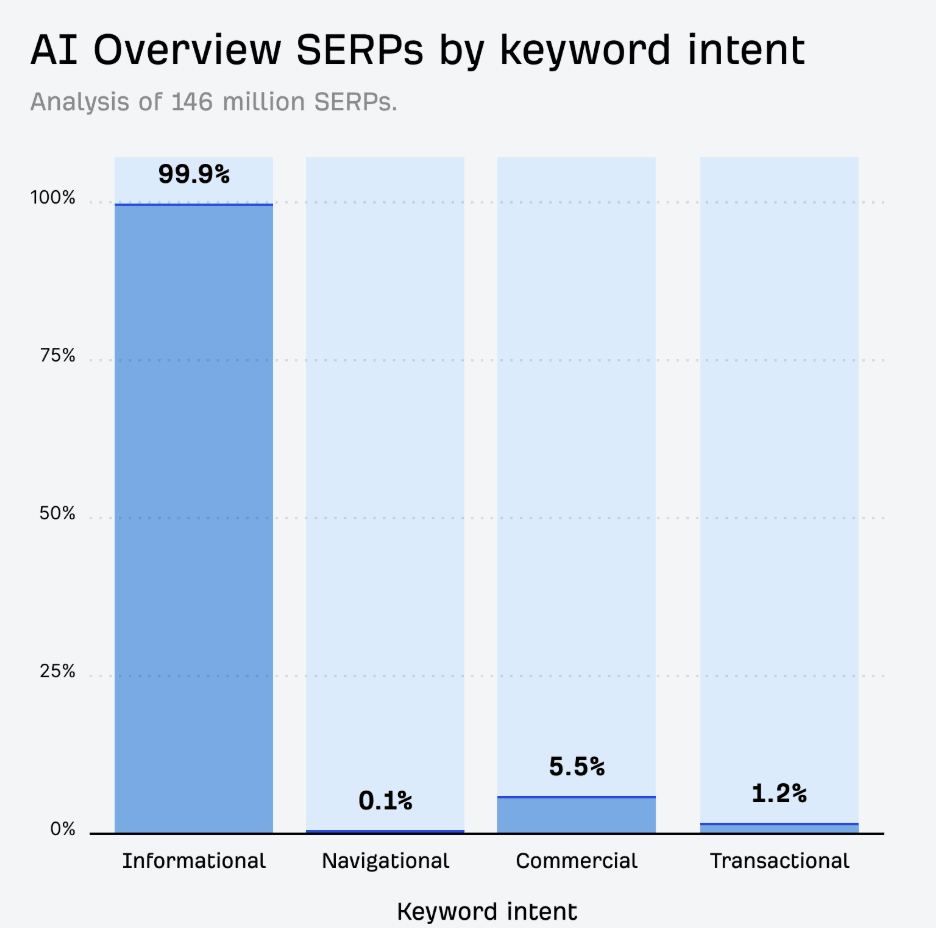
Résonance de souvenirs
Bienvenue sur IA-Pulse Weekend. Cette édition porte le numéro 159. En vous abonnant, vous recevez tous les samedis matin, l’essentiel de ce qu’il s’est passé cette semaine autour de l’IA : un coup de gueule édito, une sélection de 3 actualités avec pour chacune un résumé rapide à lire, plus 1 article de fond pour ouvrir l’esprit et réfléchir et 1 podcast à écouter. Gérez votre abonnement.
⏱️Temps de lecture de cette newsletter par une unité carbone : 9 mins
Bon, Anthropic a communiqué sur les problèmes de qualité des sorties de Claude depuis sa dernière mise à jour. Problèmes réglés depuis quelques jours, au moins en grande partie. Plusieurs raisons sont détaillées.
La première, dont tout le monde se doutait, tient à la décision prise de baisser le niveau de raisonnement par défaut. Décision qui s’ajoute à la mise en place du “raisonnement adaptif”, c’est à dire que Claude décide seul de forcer ou non un niveau de raisonnement par rapport à la tâche que lui donne un utilisateur. Là où ce dernier avait auparavant la main et décidait ou non que sa tâche méritait un haut niveau de raisonnement, maintenant Claude évalue la difficulté tout seul. De quoi économiser automatiquement du token en temps de pénurie. Mais promis, ce n’est pas la raison pour laquelle ce système a été mis en place.
Les deux autres raisons relèvent plus de “bugs” selon Anthropic. Une “optimisation” du cache qui faisait perdre les traces de raisonnements : certains ont pu voir disparaitre des éléments de conversations dans Claude et dans Cowork. Et troisième raison, une instruction dans le prompt system, qui demandait au modèle de limiter la verbosité, a eu de nombreux effets de bord principalement sur Claude Code. Par exemple, de limiter la taille des consignes envoyées aux outils et agents à 25 mots en entrée et 100 en sortie. Promis là non plus, le but n’était pas d’économiser des tokens dans un contexte tendu. Vous avez tout le détail du post-mortem un peu plus bas.
Mais maintenant qu’Amazon et Google ont annoncé des investissements colossaux dans Anthropic , en particulier en temps machine, cela ne devrait plus se reproduire. C’est sûr.
Au delà de la “moquerie” facile que l’on pourrait afficher à l’égard d’Anthropic, “l’inventeur” de “l’outil qui code tout”, il serait intéressant de connaitre les chiffres de productivité, durant cette période de baisse de performances, des équipes de développement qui utilisent Claude Code. Et d’étudier aussi les chiffres d’OpenAI et des autres acteurs, Chinois par exemple, pour voir s’il y a eu un report sur leurs outils.
Cette semaine la partie de cette newsletter gérée par l’IA, les 3 clusters d’articles, a été générée par GPT-5.5 reasoning effort xhigh pour les résumés des sources, ainsi que la génération des clusters et des titres. Comme d’habitude j’ai fait quelques modifications, mais j’ai aussi laissé quelques tournures typiques des modèles de langage. Et bien entendu, mes commentaires éventuels sont en italique dans ces résumés. Le texte de “l’article qui fait réfléchir” est issu de GPT-5.5-pro reasoning effort xhigh . L’image d’illustration ci-dessous a été générée par Midjourney

📰 Les 3 infos de la semaine
💰 DeepSeek V4 : pas besoin d’être premier sur tous les benchmarks quand on gagne sur le prix du token
DeepSeek revient avec V4, et la promesse est assez simple : un modèle très performant, ouvert, beaucoup moins cher que les grands modèles américains, et capable de traiter jusqu’à un million de tokens. V4-Pro vise les tâches complexes, le code et les agents. V4-Flash vise la vitesse et les coûts bas. En clair : l’un joue la carte du presque-frontier model, l’autre celle du modèle qu’on peut utiliser sans faire pleurer la direction financière.
Sur les benchmarks, DeepSeek ne renverse pas complètement GPT-5.5 ni Claude Opus 4.7. Les modèles américains gardent souvent l’avantage en raisonnement, en software engineering ou sur certaines tâches académiques. Mais DeepSeek s’approche suffisamment pour rendre la comparaison gênante : si un modèle fait presque aussi bien pour six ou sept fois moins cher, la question n’est plus seulement “qui est le meilleur ?”, mais “combien coûte chaque point de performance ?”. C’est moins glamour qu’un communiqué sur l’intelligence générale, mais souvent plus utile.
L’autre partie du message est industrielle. DeepSeek optimise V4 pour les puces Huawei Ascend, même si Nvidia reste probablement dans le paysage. La Chine avance donc sur deux fronts : modèles ouverts et infrastructure domestique. Open source devant, souveraineté derrière. Classique, mais efficace.
Pourquoi est-ce important ? DeepSeek rappelle une nouvelle fois une chose assez désagréable pour la Valley : on peut perdre la bataille du prestige tout en gagnant celle de la distribution et des coûts, et probablement une partie non négligeable des développeurs.
Pour aller plus loin : NYT, VentureBeat, MIT Technology Review, WSJ
🤖 ChatGPT veut devenir votre ordinateur, votre graphiste et probablement votre collègue
Cette semaine, OpenAI a avancé sur deux fronts à la fois -en fait sur plus, mais je ne t’ai pas donné de quoi le savoir GPT. D’un côté, GPT-5.5, nouveau modèle centré sur le code, les tâches longues, la recherche scientifique et l’usage concret de l’ordinateur. De l’autre, ChatGPT Images 2.0, qui ne se contente plus de générer une belle image floue avec trois doigts en trop et une typographie sortie d’un cauchemar administratif.
GPT-5.5 est conçu pour faire plus avec moins d’instructions. Il se débrouille mieux dans les workflows désordonnés -après quelques heures de travail avec 5.5, je valide cette affirmation-, les terminaux, les bases de code, les documents, les feuilles de calcul. Le modèle reprend l’avantage sur plusieurs benchmarks publics, notamment dans les tâches agentiques et l’usage du terminal, même si Claude reste mieux placé sur certains tests de raisonnement sans outils. La grande idée, traduite du langage produit : arrêter de demander au modèle une réponse, et commencer à lui confier une séquence de travail. Avec garde-fous cyber renforcés, bien sûr, parce que donner plus d’autonomie à un modèle capable de trouver des failles logicielles n’est pas exactement une activité de poterie.
Images 2.0 pousse la même logique côté visuel. Le modèle peut chercher sur le web, analyser des fichiers, produire des infographies, des cartes, des séries d’images cohérentes, du texte lisible et multilingue. L’image devient un format de synthèse, pas seulement un décor.
Pourquoi est-ce important ? ChatGPT cesse progressivement d’être uniquement une interface de conversation pour devenir une interface d’exécution. Et comme souvent, tous les “product managers” et “UX specialists” du monde, dont ceux d’OpenAI, appellent ça un environnement “plus intuitif”… au moment précis où ça devient plus difficile à cadrer pour n’importe quel utilisateur. Ah, vivement que Claude Design vienne mettre de l’ordre dans tout ça…
Pour aller plus loin : VentureBeat (1), VentureBeat (2), TechCrunch, The Verge
👁️ Meta cherche les données du geste pour entraîner ses agents IA
Meta va installer sur les ordinateurs professionnels de ses salariés américains un outil capable d’enregistrer les mouvements de souris, les clics, les frappes clavier et des captures d’écran ponctuelles sur certaines applications de travail. L’objectif officiel : entraîner des agents IA à mieux comprendre comment les humains utilisent réellement un ordinateur. Menus déroulants, raccourcis clavier, navigation dans les interfaces, petites hésitations absurdes devant un bouton mal placé. Tout ce qui fait la joie quotidienne du travail numérique moderne.
Meta assure que ces données ne serviront pas à évaluer les salariés. Elles doivent uniquement nourrir les modèles. Traduction : ce n’est pas de la surveillance managériale, c’est de la surveillance pédagogique. La nuance fera sûrement plaisir à ceux qui n’ont pas le droit de refuser l’installation sur leur laptop professionnel.
Le projet s’inscrit dans une réorganisation plus large. Meta pousse ses équipes à utiliser davantage d’agents, crée des équipes appliquées à l’IA, transfère des ingénieurs vers ces nouvelles structures, invente des profils plus généralistes d’“AI builder” et prépare des suppressions de postes. Les agents doivent faire le travail ; les humains devront diriger, vérifier, corriger. On a enfin automatisé le stagiaire, puis reconverti tout le monde en superviseur inquiet.
Pourquoi est-ce important ? Quoi de mieux que de capturer à la source ce qu’on veut faire prendre en charge par les machines. On l’a fait avec les textes et les images. Pourquoi pas avec les gestes et les actions ? Cela ira peut-être plus vite que de développer des “modèles mondes” généralistes.
Pour aller plus loin : Reuters, The Verge, Ars Technica
🚀 6 lectures en plus
Google Expands Anthropic Investment With $40 Billion Commitment (WSJ)
OpenClaw Struggles to Grow Up After Overnight Success (The Information)
Google turns Chrome into an AI co-worker for the workplaces (TechCrunch)
🚨You’re about to feel the AI money squeeze (The Verge)
Google doesn’t pay the Nvidia tax. Its new TPUs explain why. (VentureBeat)
🛠️ Des outils, des tutos et des modèles à tester
Kimi K2.6: Advancing Open-Source Coding
Deep Research Max: a step change for autonomous research agents
Google Stitch’s DESIGN(.)md format is now open-source so you can use it across platforms
The directory of DESIGN(.)md files for coding agents
Googler Flow : 3 creative tips from our Flow Sessions artists
On-device AI Browser Assistant : Transformers.js Gemma 4 Browser Assistant
🧠 L’article qui fait réfléchir - et qu’il faut absolument lire
AI Is Cannibalizing Human Intelligence. Here’s How to Stop It.
“Memorabilia, memorabilia”
On croit avoir inventé un stagiaire électrique : obéissant, rapide, jamais syndiqué, capable de ranger le bazar pendant que l’humanité va peindre, juger, aimer, bref, faire sa petite supériorité d’espèce en haut de la pyramide.
Raté.
Le problème actuel n’est pas que la machine pense mieux que nous. Le problème, bien plus humiliant, est qu’elle révèle à quelle vitesse nous acceptons de ne plus penser. Donnez une réponse lisse, bien ponctuée, avec trois connecteurs logiques et une confiance de consultant -tu viens de le faire d’ailleurs GPT- : beaucoup d’esprits applaudissent et signent en bas.
WTF -oh GPT !!!!-, comme on dit quand le progrès ressemble soudain à une démission.
Il existe pourtant une autre manière de faire. Ne pas demander à l’outil de conclure, mais de déranger. Le forcer à se contredire. Lui demander où il triche, ce qu’il oublie, quelle hypothèse sent le moisi. L’utiliser non comme majordome cognitif, mais comme contradicteur infatigable. Là, quelque chose se passe : l’humain cesse d’être client de la réponse et redevient artisan de la question.
La fracture n’est donc pas entre ceux qui ont accès à l’intelligence artificielle et ceux qui n’y ont pas accès. Trop simple. Elle est et sera entre ceux qui s’en servent pour épaissir leur jugement et ceux qui s’en servent pour devenir des distributeurs automatiques de certitudes prémâchées -en revanche elle est un peu téléphonée toute cette dernière partie GPT.
Penser demande une certaine indécence : c’est accepter d’être lent, incomplet, réfutable, répudiable et finalement c’est accepter de se regarder. C’est supporter le blanc. Infini. Ne surtout pas remplir chaque trou par une phrase brillante sortie d’une boîte non-crânienne, et parfois accepter d’être vu en train de ne pas savoir.
Tu ne sais pas encore imiter ça GPT.
📻 Le podcast de la semaine

AI Engineer : "Software Fundamentals Matter More Than Ever" — Matt Pocock
Pocok nous explique en moins de 20 mins pourquoi c’est toujours important de former des développeurs compétants.
N’hésitez à me contacter si vous avez des remarques et suggestions sur cette newsletter, ou si dans votre entreprise vous cherchez à être accompagnés dans l’intégration d’outils IA et d’IA générative : olivier@255hex.ai
Partagez cette newsletter
Et si vous n’êtes pas abonné, il ne tient qu’à vous de le faire !
“Give me a reminder
I can't remember
I collect, I reject”