Créez votre avatar IA en un clin d’oeil avec PuLID

Développé par une équipe de chez ByteDance (mais si, TikTok, votre réseau social préféré), ce modèle baptisé PuLID va vous permettre de créer des images sur-mesure à partir de photos existantes et tout ça en un clin d’œil.
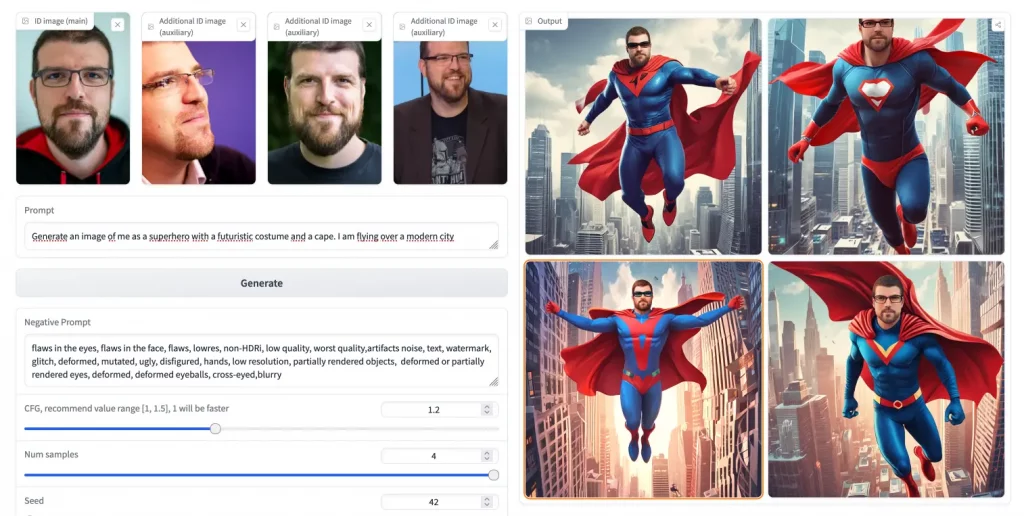
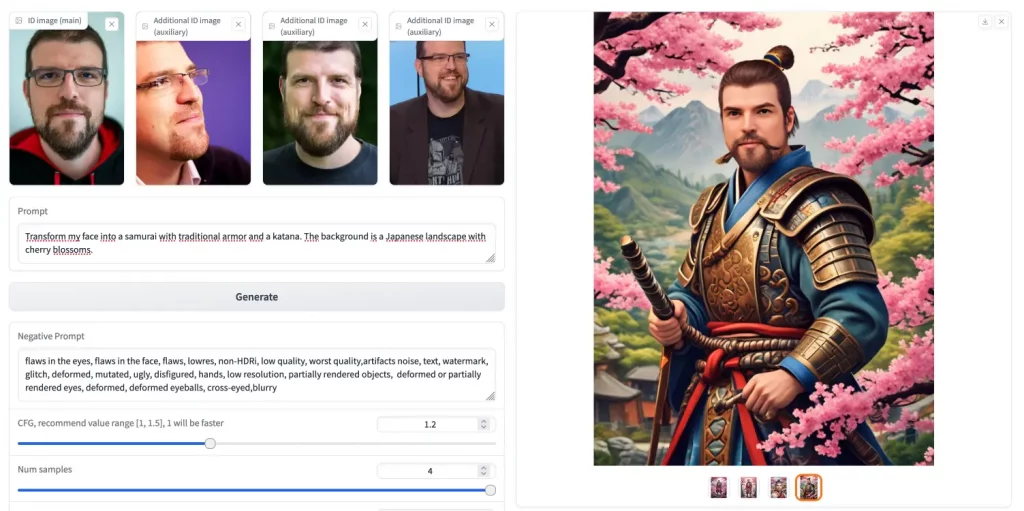
Basé sur le principe d’alignement contrastif, PuLID vous offre une customisation d’identité ultra rapide et de haute qualité. Pour cela, il utilise une architecture qui apprend à la volée les caractéristiques clés d’une identité source (des photos de vous) pour les transposer efficacement sur de nouvelles images cibles (images générées par IA). On obtient alors des visuels uniques générés en quelques secondes à peine, tout en préservant la cohérence des photos d’origine.
Bon, ok, ça peut paraître un peu barbare dit comme ça mais c’est super simple à utiliser. Si vous êtes flemmard, vous pouvez aller directement sur Huggingface ou pour les plus courageux, l’installer sur votre machine. Tout ce dont vous avez besoin, c’est d’un bon vieux Pytorch (version 2.0 minimum svp) et de quelques lignes de code pour démarrer l’entraînement.
PuLID (Pure and Lightning ID Customization via Contrastive Alignment) fonctionne en utilisant des techniques de machine learning pour aligner des représentations latentes en comparant des paires d’images ou d’identités. L’objectif est de maximiser la similarité pour des identités similaires et de minimiser la similarité pour des identités différentes. En ajustant ces représentations grâce à l’alignement contrastif, PuLID permet de créer des images uniques avec une grande précision et rapidité.

Si vous bossez dans la comm et que ous avez déjà quelques concepts arts sympas d’un personnage, mais vous aimeriez voir à quoi il ressemblerait dans différents environnements ou avec des styles graphiques variés, pas de souci ! Vous balancez vos images dans PuLID avec les bonnes instructions et le tour est joué. Vous obtiendrez alors tout un tas de variations stylées de votre personnage, tout en gardant son visage reconnaissable.
L’équipe de ByteDance a pensé à tout : PuLID est 100% open-source et disponible sur GitHub. Vous pouvez donc bidouiller le code comme bon vous semble pour l’adapter à vos besoins. Y’a même des tutoriels et des exemples pour vous aider à prendre en main le bouzin rapidement.
Et pour les plus impatients d’entre vous, voici un petit tuto d’installation pour commencer à jouer avec PuLID :
Pré-requis :
- Python >= 3.7
- PyTorch >= 2.0 (télécharger ici)
- Anaconda (télécharger ici) ou Miniconda (télécharger ici)
Étapes d’installation :
- Cloner le dépôt PuLID :
git clone https://github.com/ToTheBeginning/PuLID.git
cd PuLID
Créer et activer l’environnement conda :
conda create --name pulid python=3.10 conda activate pulid
Installer les dépendances :
pip install -r requirements.txt
Installer PyTorch : Suivez les instructions sur le site de PyTorch pour installer la version compatible avec votre système. Par exemple, pour CUDA 11.7 :
conda install pytorch torchvision torchaudio cudatoolkit=11.7 -c pytorch
Lancer l’application :
python app.py
Pour en savoir plus sur PuLID et récupérer le code source, rendez-vous sur le repo GitHub.
Allez, je vous laisse vous amuser avec votre nouveau jouet. Un grand merci à Lorenper pour l’info. Grâce à toi, on va pouvoir personnaliser nos avatars comme jamais.


