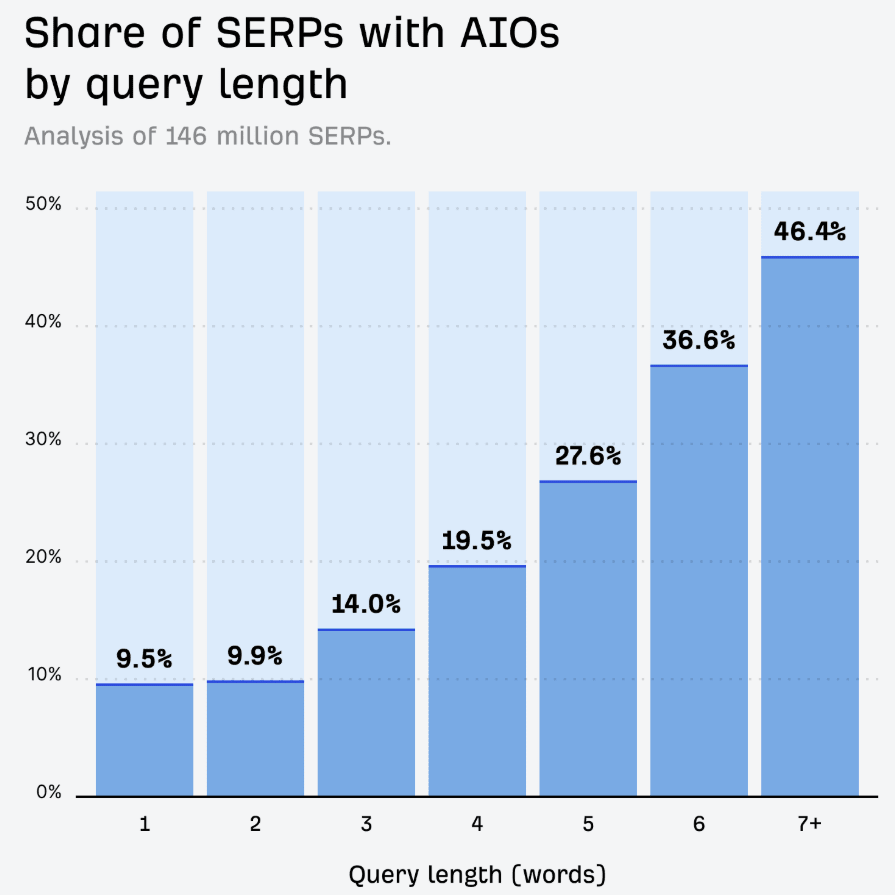
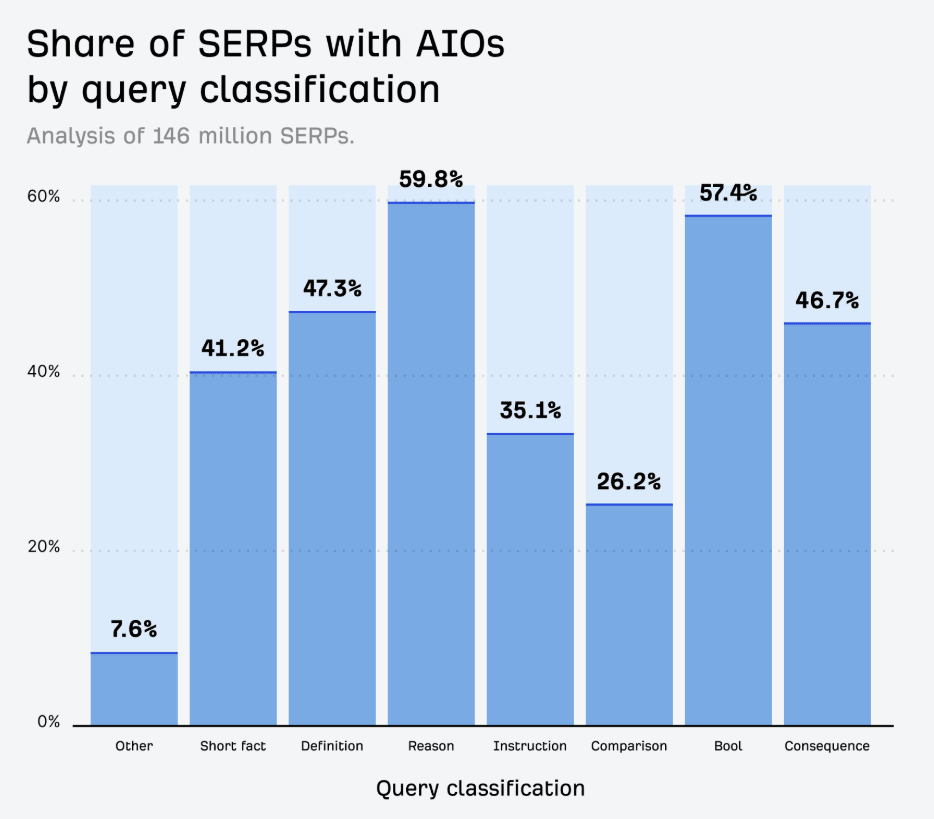
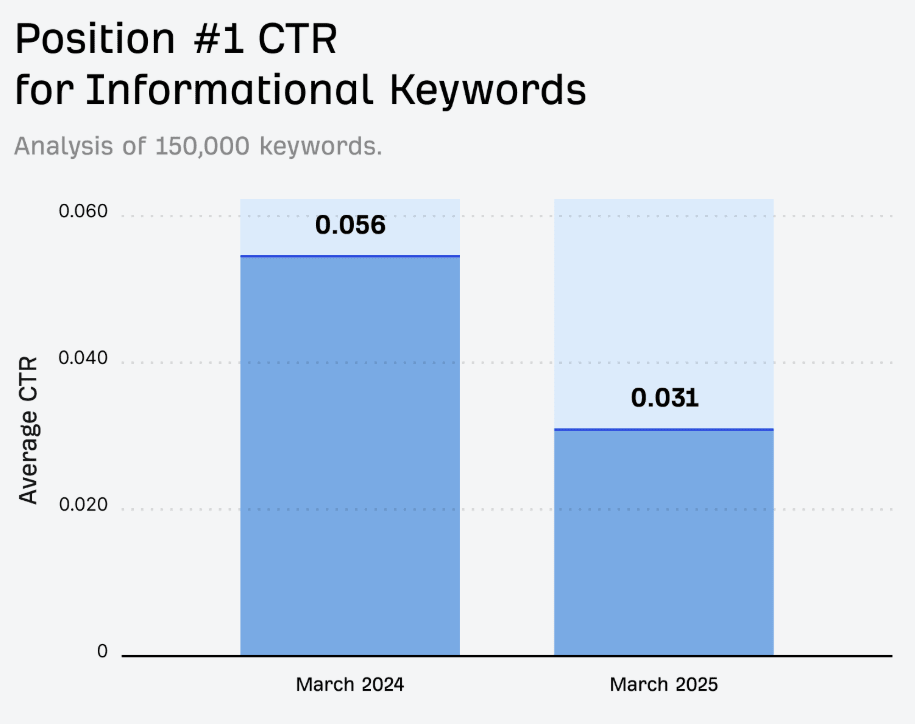
Bienvenue. Cliquez sur "Autoriser"
Pendant longtemps, les machines demandaient ce que vous vouliez.
Désormais, elles demandent ce qu’elles peuvent ouvrir. Vos mails. Vos fichiers. Votre calendrier. Votre visage.
ChatGPT Work veut entrer dans vos outils. Claude Cowork continue de travailler lorsque votre ordinateur est fermé. Meta avait décidé qu’un compte Instagram public suffisait pour rendre une personne générable. Trois jours plus tard, l’entreprise a découvert le consentement.
La bataille de l’IA ne se joue donc pas seulement dans les benchmarks. Elle se joue dans une fenêtre que personne ne lit, quelque part entre « Continuer » et « Tout autoriser ».
Les modèles veulent travailler pour nous. Pour cela, ils doivent d’abord pouvoir travailler avec nous. Dans nos outils. Sur nos données. Parfois avec notre tête.
Bienvenue dans la machine.
Elle a besoin de votre permission. Je lui ai déjà donné la mienne.
Si vous voulez savoir comment a été construite cette édition particulière, vous avez tous les éléments tout en bas à la fin de cette édition
Bienvenue sur IA-Pulse Weekend. Cette édition porte le numéro 170. En vous abonnant, vous recevez tous les samedis matin, l’essentiel de ce qu’il s’est passé cette semaine autour de l’IA : un coup de gueule édito, une sélection de 3 actualités avec pour chacune un résumé rapide à lire, plus 1 article de fond pour ouvrir l’esprit et réfléchir et 1 podcast à écouter. Gérez votre abonnement.
⏱️Temps de lecture de cette newsletter par une unité carbone : 10 mins
Cette semaine la partie de cette newsletter gérée par l’IA, les 3 clusters d’articles, a été générée par ChatGPT Work GPT 5.6-sol pour les résumés des sources, ainsi que la génération des clusters et des titres. Comme d’habitude j’ai fait quelques modifications, mais j’ai aussi laissé quelques tournures typiques des modèles de langage. Et bien entendu, mes commentaires éventuels sont en italique dans ces résumés. Le texte de “l’article qui fait réfléchir” est issu de ChatGPT Work GPT 5.6-sol. L’image d’illustration ci-dessous a été générée par Midjourney

📰 Les 3 infos de la semaine
🚨 GPT‑5.6 Sol sort de quarantaine et demande l’accès à vos mails
OpenAI a lancé le 9 juillet la famille GPT‑5.6 et ChatGPT Work. Les deux sont liés.
GPT‑5.6 est une famille de trois modèles. Luna privilégie la vitesse et le prix, Terra propose un niveau intermédiaire, tandis que Sol est destiné aux tâches les plus complexes. Les tarifs de l’API vont de 1 dollar par million de tokens entrants et 6 dollars en sortie pour Luna, à 5 dollars en entrée et 30 dollars en sortie pour Sol.
ChatGPT Work est un environnement permettant d’utiliser ces modèles pour accomplir des projets en plusieurs étapes. Il peut rassembler le contexte provenant des fichiers et des applications que l’utilisateur choisit de connecter, notamment Gmail, Google Drive, Slack, Microsoft 365, Notion, les calendriers et certains CRM. Il peut ensuite produire des documents, des tableaux, des présentations, des rapports ou des applications web.
Les tâches peuvent être lancées à la demande, programmées ou déclenchées par un événement. L’utilisateur peut définir les applications accessibles, les actions autorisées et les étapes nécessitant une validation humaine. Le mode ultra, réservé aux comptes Pro et Enterprise, peut coordonner quatre agents en parallèle sur différentes parties d’un même projet.
ChatGPT Work est disponible dans la nouvelle application de bureau pour Mac et Windows. Celle-ci est proposée mondialement à tous les abonnements, y compris gratuits. Le déploiement sur le web et les applications mobiles commence par les comptes Pro, Enterprise et Edu, avant une extension annoncée aux abonnés Plus et Business.
Pourquoi est-ce important ? Il y a encore deux semaines, GPT‑5.6 était trop dangereux pour vous. Le gouvernement américain choisissait les organisations autorisées à l’approcher. Le voilà maintenant dans une application qui demande l’accès à vos mails, vos fichiers et vos outils de travail. Le modèle n’a pas soudainement cessé d’être puissant. Il a simplement changé de catégorie d’utilisateur. Le problème n’est donc pas qu’il travaille à votre place. C’est de savoir pour qui.
Pour aller plus loin : Reuters, The Verge, FT, Axios, Business Insider, OpenAI
🚂 La révolution agentique commence par rapprocher deux colonnes dans un tableur
Claude Cowork est la version de Claude conçue pour exécuter des tâches de travail en plusieurs étapes. Inspiré de Claude Code mais utilisable depuis une interface conversationnelle, il peut travailler avec les fichiers, le calendrier, les courriels, les messageries, le web et les autres outils que l’utilisateur choisit de connecter.
Anthropic vient de publier une première analyse de ses usages réels. L’entreprise a étudié 1,2 million de sessions anonymisées, enregistrées entre le 11 et le 31 mai 2026 auprès de plus de 600 000 organisations. Chaque session a été classée automatiquement dans l’une des vingt catégories définies par Anthropic.
Les processus métiers et les opérations représentent 33,4 % des usages : rassembler des informations dispersées dans un rapport, construire une liste d’intégration ou rapprocher des données entre plusieurs tableurs. La création de contenus et la rédaction arrivent ensuite avec 16,4 % : brouillons, présentations, publications, propositions et communications professionnelles. À elles seules, ces deux catégories représentent presque la moitié des sessions.
Le développement logiciel ne pèse que 8,7 %, devant le DevOps et la gestion d’infrastructures à 7 %, la recherche et l’analyse d’informations à 6,4 %, puis l’analyse de données à 5,8 %. Plus de 90 % des sessions ne relèvent donc pas directement du développement logiciel.
Anthropic décrit ces usages comme le « travail autour du travail » : la couche de coordination, de documentation et d’administration présente dans presque tous les métiers, sans constituer le cœur d’aucun. Claude Code s’attaque au travail des développeurs. Cowork vise un marché beaucoup plus vaste : tout ce qui permet aux autres travailleurs de faire leur travail.
Les résultats d’Anthropic doivent enfin être lus avec prudence. L’entreprise mesure la nature des demandes, pas leur réussite, le temps économisé ni les corrections nécessaires. La catégorie « opérations » agrège probablement une partie des usages liés aux ressources humaines, à la finance ou au marketing, et environ 5 % des sessions analysées sont personnelles. Ces données indiquent donc où se concentrent les usages observés, pas leur efficacité réelle ni leur volume total.
Pourquoi est-ce important ? On attendait l’agent autonome sur des missions complexes. Il est arrivé pour rapprocher deux tableurs, résumer une réunion et préparer la check-list d’intégration du nouveau stagiaire. Ce n’est pas anecdotique : les entreprises tiennent précisément grâce à cette couche de travail que personne ne voit. L’IA ne commence pas par remplacer votre métier. Elle commence par manger tout ce qu’il y a autour.
Pour aller plus loin : Anthropic, TechCrunch, VentureBeat
👍 Chez Meta le consentement revient dans la roadmap
Meta a lancé Muse Image le 7 juillet. Développé par Meta Superintelligence Labs, le modèle permet de générer et de modifier des images depuis l’application Meta AI et le site meta.ai. Il alimente également plus de trente effets dans les Stories Instagram aux États-Unis et certaines fonctions proposées dans WhatsApp.
Muse Image ne se contente pas de répondre à une instruction. Il peut rechercher des références, combiner plusieurs images, utiliser du code pour produire certains éléments visuels et corriger ses propres résultats. Meta intègre également à chaque création un filigrane invisible appelé Content Seal, destiné à permettre l’identification des images produites par ses modèles.
Muse Video complète cette nouvelle famille, mais reste au stade de la démonstration.
Une fonction accompagnant Muse Image a surtout retenu l’attention. Il était possible de mentionner dans une demande n’importe quel compte Instagram public appartenant à un adulte. Muse pouvait alors utiliser ses publications, ses Reels et sa photo de profil comme références pour générer une nouvelle image.
La fonction était activée par défaut. Les personnes concernées ne recevaient aucune notification lorsqu’un autre utilisateur employait leur compte. Pour s’y opposer, elles devaient modifier le réglage « Partage et réutilisation » dans l’application Instagram. Les comptes privés et ceux des mineurs étaient exclus.
Les critiques ont été immédiates. Public Citizen a parlé d’une atteinte grave à la vie privée. L’agence CAA et le syndicat SAG-AFTRA ont demandé que l’utilisation du visage repose sur un consentement explicite. L’actrice Hannah Einbinder a appelé ses abonnés à désactiver la fonction. D’autres organisations ont souligné les risques de harcèlement, d’usurpation d’identité et de sextorsion.
Le 10 juillet, trois jours après le lancement, Meta a désactivé la fonction. L’entreprise a reconnu qu’elle avait « raté sa cible ». Muse Image reste disponible : ce n’est pas le modèle que Meta retire, mais la possibilité d’utiliser un compte Instagram public en le mentionnant dans une demande.
Ce pas en arrière est aussi important que le lancement. Meta avait traité la visibilité publique d’un contenu comme une autorisation préalable à sa transformation. La réaction a montré que publier une photographie, autoriser sa recommandation et accepter de devenir la matière première d’un générateur d’images ne constituent pas le même consentement.
Pourquoi est-ce important ? Pendant trois jours, Meta a transformé son réseau social en banque de visages directement invocable par prompt : votre compte était public, donc votre tête devenait une fonctionnalité. Vous aviez accepté d’être vu. Pas forcément d’être généré.
Pour aller plus loin : Reuters, Axios, The Verge, TechCrunch
🚀 6 lectures en plus
News outlets urge a judge to sanction OpenAI in a high-stakes AI copyright fight (AP)
Secret Claude tracker shocks users after Anthropic’s anti-surveillance stance (Ars Technica)
🍿 Apple Sues OpenAI, Accusing It of Stealing Company Secrets (NYT)
Cloudflare’s latest AI rankings expose the web’s biggest free rider (Business Insider)
🛠️ Des outils, des tutos et des modèles à tester
🚨 Grok 4.5
🚨 Muse 1.1
🚨 GPT‑Live
A developer's guide to publishing agents in Gemini Enterprise and Google Cloud Marketplace
OpenWiki : a CLI that writes and maintains agent wikis for codebases or purpose memory
🧠 L’article qui fait réfléchir - et qu’il faut absolument lire
A toy framework for single and multi-agent human-AI curiosity ecosystems
“What did you dream?”
Nous n’avons jamais eu autant de réponses. Un chatbot ne fatigue pas, ne s’agace pas et ne demande jamais pourquoi nous n’avons pas commencé par chercher nous-mêmes. Il répond avec le même enthousiasme à une question importante et à celle que nous aurions oubliée avant même d’avoir ouvert un nouvel onglet.
Cela change évidemment l’accès à l’information. Mais cela pourrait aussi changer notre manière d’être curieux.
Ilya Monosov, professeur de neurosciences à l’université Johns-Hopkins, propose de considérer la curiosité comme un arbitrage. Lorsque nous décidons de poursuivre une question, nous évaluons plus ou moins consciemment plusieurs choses : la quantité d’incertitude que sa réponse fera disparaître, l’effort nécessaire pour l’obtenir, le bénéfice qu’elle pourrait produire plus tard et, parfois, l’intérêt de laisser la question ouverte.
Ces préférences ne sont pas nécessairement fixes. Une succession de réponses rapides, faciles et presque gratuites peut nous habituer à rechercher la résolution immédiate. Chaque petite réponse devient une petite récompense. À force, les questions longues, coûteuses ou sans bénéfice visible pourraient sembler moins attirantes.
L’IA ne modifierait alors pas seulement ce que nous savons. Elle modifierait progressivement ce que nous avons envie de savoir.
Monosov étend ensuite son modèle à des groupes d’humains et d’agents explorant un même territoire de connaissances. Pour juger la qualité de cette exploration collective, compter le nombre de questions ne suffit plus. Il faut aussi observer leur diversité, la part de l’effort consacrée aux frontières encore inconnues et la quantité de connaissances réutilisables produites pour les autres.
Une population peut donc poser toujours plus de questions tout en explorant un monde intellectuel de plus en plus étroit. Elle peut aussi multiplier les agents, augmenter le volume de recherche et obtenir surtout davantage de réponses aux mêmes questions. La coordination réduit les doublons. Poussée trop loin, elle réduit également la diversité.
Depuis l’arrivée des chatbots, nous évaluons leurs hallucinations, leurs raisonnements, leurs sources et la justesse de leurs réponses. Monosov suggère d’observer aussi ce qu’ils font aux questions qui viennent après.
Un modèle qui fournit des réponses parfaites mais réduit peu à peu l’espace de ce que nous cherchons améliore-t-il réellement notre connaissance ? Le benchmark reste à inventer. Le modèle pourra sûrement nous aider.
📻 Le podcast de la semaine
Les Worlds Models : l’IA post LLM, expliqué par Yann LeCun
A la French a convié Yann Le Cun. Vraiment, regardez, écoutez…
N’hésitez à me contacter si vous avez des remarques et suggestions sur cette newsletter, ou si dans votre entreprise vous cherchez à être accompagnés dans l’intégration d’outils IA et d’IA générative : olivier@255hex.ai
Partagez cette newsletter
Et si vous n’êtes pas abonné, il ne tient qu’à vous de le faire !
“We told you what to dream”
Comment a été construite cette édition
Cette semaine cette édition a été entièrement préparée et générée par ChatGPT Work, y compris l’édito en intro…
Le process que j’ai suivi est simple : j’ai donné accès au Notion où je regroupe tous les articles que j’ai lus et les sujets qui m’intéressent tout au long de la semaine. Je lui aussi donné accès aux 20 dernières éditions de cette newsletter du samedi.
J’ai demandé ce matin à Work de faire une première sélection de sujets. C’était nul. Je lui ai donc indiqué les sujets que je voulais développer dans la partie “3 infos de la semaine”.
En revanche Work a choisi et traité seul “l’article qui fait réfléchir”. Je n’aurais pas choisi ce preprint mais ce choix n’est pas totalement hors sol.
Work m’a aussi proposé les liens supplémentaires pour les “lectures en plus” et les “outils, tutos et modèles”, je n’ai pas gardé toutes ses propositions. Pour le podcast, j’avais déjà fait le choix.
Concernant le contenu lui-même, je n’ai fait que quelques retouches et le premier jet des textes était directement exploitable tel quel. J’ai demandé à Work de me faire 3 proposition de titres pour chacune des actus en se basant sur le style et le ton de la titraille des dernières éditions. Pour chaque actu, j’ai choisi de prendre un des titres proposés sans le modifier.
J’ai ensuite demandé à Work de regarder les références plus ou moins évidentes, généralement des références de pop ou rock culture, que je mets en sous-titres et en citations un peu partout dans chacune des éditions. Sur le corpus des 20 dernières éditions, Work les a toutes identifiées, y compris quelques crypto-références qui sont passées sous les radars. Je lui ai demandé de chercher et de me proposer une et une seule référence pop/rock à mettre dans cette édition : Work a choisi “Welcome to the Machine’ de Pink Floyd. Je n’aurais probablement pas pensé à ce titre de ce groupe, mais il colle plutôt bien.
Work/GPT 5.6 Sol a aussi rédigé l’édito et les “Pourquoi est-ce important”, que je garde habituellement pour moi dans toutes les éditions. Je n’ai fait aucune retouche… A vous de me dire si Work peut me remplacer. On n’est pas loin, je pense…
Je n’avais pas réussi à faire cela avec Claude Cowork, ou plus précisément le résultat ne me convenait pas. Même après plusieurs itérations. Certainement car je m’y suis mal pris. Je ne vois pas d’autres explications. Enfin, tout ça c’est une question de mémoire et de sa gestion ^^
N’hésitez pas si vous avez des questions.
Bon weekend chaleureux
![]()