En classe, les élèves utilisent de plus en plus l’IA générative, mais ont souvent tendance à faire confiance trop rapidement à ses réponses, sans toujours les questionner ni les évaluer de manière critique.
Dans cette vidéo, des chercheurs du laboratoire Inria Flowers AI & CogSci présentent une étude menée en classe montrant qu’un atelier pédagogique de 2 heures sur l’IA générative peut améliorer la façon dont les collégiens l’utilisent.
Menée auprès de 116 élèves, l’étude montre qu’une formation courte, ciblée et facilement déployable en classe aide les élèves à mieux questionner les réponses de l’IA, à poser des questions de suivi plus pertinentes et à produire des réponses de meilleure qualité.
In classrooms, students increasingly rely on GenAI, but often trust its answers too quickly and struggle to evaluate or question them.
In this video, researchers from the Inria Flowers AI & CogSci Lab share a classroom study showing that a 2-hour AI literacy workshop can improve how middle-school students use generative AI.
With 116 students, our results show that short, targeted, and scalable instruction helps students question AI outputs, ask better follow-up questions, and produce higher-quality answers.
Matthieu Cord is a Professor at Sorbonne University, Head of the MLIA team at the ISIR laboratory, and Scientific Director at Valeo.ai.
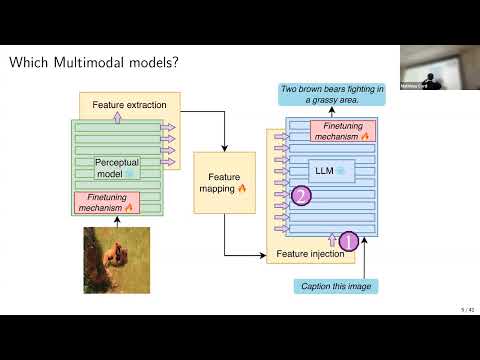
Title: Analyzing Internal Representations of Multimodal LLMs
Abstract: Multimodal LLMs combine unimodal encoders with large language models yet their internal representations remain largely unexplored. We introduce a dictionary-learning framework that extracts semantically grounded multimodal concepts from token representations enabling interpretable analysis across both vision and language. We further propose mechanisms to steer model behavior. Together these approaches improve the interpretability of multimodal LLMs reduce hallucinations and provide fine-grained control over their outputs.
Jury:
- Dr. Ellie PAVLICK - Associate Professor - Brown University / Google DeepMind - Reviewer
- Dr. Prithviraj AMMANABROLU - Assistant Professor - Univ. of California San Diego / Nvidia - Reviewer
- Pr. Hugo LAROCHELLE - Professor - University of Montréal / MILA - Examiner
- Dr. Timothy LILLICRAP - Research Scientist - University College of London / Google DeepMind - Invited
- Pr. Matthieu CORD - Professor - Sorbonne University / Valeo - President
- Dr. Pierre-Yves OUDEYER - Research Director - INRIA - Co-advisor
- Dr. Thomas WOLF - Chief Science Officer - Hugging Face - Co-advisor
PhD defense of Grgur Kovač. Defended on Nov 5th 2025.
Title: Building, evaluating and understanding socio-cultural AI: leveraging
concepts and methods from human sciences
Supervision: Pierre-Yves Oudeyer
Co-supervision: Peter Ford Dominey
Jury:
- M. Jan SNAJDER Full professor University of Zagreb (CROATIE)
- M. Maarten SAP Assistant professor Carnegie Mellon University (Pittsburgh, ETATS-UNIS)
- Mme Clémentine FOURRIER Ingénieure de recherche Hugging Face, Inc. (New York City, ETATS-UNIS)
- M. Mehdi KHAMASSI Directeur de recherche CNRS, University of Sorbonne (Paris)
- Mme Vered SHWARTZ Assistant professor University of British Columbia (Vancouver, CANADA)
Related Workshop: https://youtube.com/playlist?list=PL9T8000j7sJCjamaNWif8ivtflsfx2df2&si=RYuoGoePwGl0n2UZ
Mehdi Khamassi is a research director employed by the Centre National de la Recherche Scientifique (CNRS), and working at the Institute of Intelligent Systems and Robotics (ISIR), on the campus of Sorbonne Université, Paris, France.
Title: Language as a cognitive tool for open-ended agents
Abstract:
Despite progress, current AI systems succeed only in human-defined domains, where problems and strategies are pre-specified. The long-term ambition is toward agents that act effectively even without predefined goals. Achieving this requires open-ended agents: systems that autonomously explore, learn, and repurpose knowledge across their lifetimes. Humans exemplify this process, guided by curiosity, intrinsic motivation, and self-generated goals. Language plays a central role. It enables abstraction, reasoning, and planning, making it a powerful medium for open-ended discovery in artificial agents. To function, an open-ended agent must: (1) explore environments autonomously, (2) adapt to evolving rules, and (3) learn new skills efficiently as complexity grows. This thesis leverages language to advance open-ended agents across three dimensions: environment modelling, goal exploration, and efficient learning. First, LLMs are used both as embodied reinforcement learning agents and as hypothesis generators to improve world models. Second, language is employed to evaluate, generalize, and generate goals, supporting scalable curriculum learning. Third, novel methods use language for reward shaping and hierarchical control, enabling efficient policy learning and skill reuse. Overall, the thesis argues that language is not only a communication tool but a cognitive engine. By embedding LLMs into agent architectures, we move closer to autonomous systems capable of continuous learning, self-directed exploration, and adaptive lifelong discovery.
Date: 13/10/2025
Members of the jury:
Dr. Georg MARTIUS, Professor, Université de Tübingen, Reviewer
Dr. Pierre-Luc BACON, Associate Professor, Université de Montreal DIRO, Reviewer
Dr. Edward HUGHES, Researcher and Associate Professor, Deepmind et The London School of economics, Examinator
Dr. Martha WHITE, Associate Professor, Université d’Alberta, Examinator
Pr Jean PONCE, Professor,Ecole normale supérieure-PSL, Examinator
Dr. Pierre-Yves OUDEYER, Director de Recherche, INRIA, Director
Pr. Olivier SIGAUD, Professor, Université de la Sorbonne, Director
Pr. Sylvain Lamprier, Professor, Université d’Anger, Invited
======= Français =======
Titre: Le langage comme outil cognitif pour les agents ouverts
Résumé: Malgré les progrès réalisés, les systèmes d’IA actuels ne fonctionnent que dans des domaines définis par l’homme, où les problèmes et les stratégies sont prédéfinis. L’ambition à long terme est d’obtenir des agents agissant efficacement même sans objectifs prédéfinis. Pour y parvenir, il faut des agents ouverts : des systèmes qui explorent, apprennent et réutilisent de manière autonome les connaissances tout au long de leur vie. Les êtres humains illustrent ce processus, guidés par la curiosité, la motivation intrinsèque et des objectifs qu’ils se fixent eux-mêmes. Le langage joue un rôle central. Il permet l’abstraction, le raisonnement et la planification, ce qui en fait un moyen puissant pour la découverte ouverte chez les agents artificiels. Pour fonctionner, un agent ouvert doit : (1) explorer des environnements de manière autonome, (2) s’adapter à des règles en évolution et (3) acquérir efficacement de nouvelles compétences à mesure que la complexité augmente. Cette thèse exploite le langage pour faire progresser les agents ouverts dans trois dimensions : la modélisation de l’environnement, l’exploration des objectifs et l’apprentissage efficace. Premièrement, les LLMs sont utilisés à la fois comme agents d’apprentissage par renforcement incarnés et comme générateurs d’hypothèses pour améliorer les modèles du monde. Deuxièmement, le langage est utilisé pour évaluer, généraliser et générer des objectifs, ce qui favorise un apprentissage évolutif. Troisièmement, de nouvelles méthodes utilisent le langage pour la mise en forme des récompenses et le contrôle hiérarchique, ce qui permet un apprentissage efficace des politiques et la réutilisation des compétences. Dans l’ensemble, cette thèse soutient que le langage n’est pas seulement un outil de communication, mais aussi un moteur cognitif. En intégrant les LLMs dans les architectures des agents, nous nous rapprochons de systèmes autonomes capables d’apprendre en continu, d’explorer de manière autonome et de faire des découvertes adaptatives tout au long de leur vie.
Title: Curious and therefore not overloaded: Towards an integrated understanding of curiosity and cognitive load in XR learning environments
Abstract: This PhD investigates the pedagogical potential of Extended Reality (XR) in education, focusing on how Virtual Reality (VR) and Augmented Reality (AR) influence cognitive load, motivation, and learning. By integrating Cognitive Load Theory with the Learning Progress Hypothesis, the research examines how curiosity-driven engagement interacts with cognitive demands in immersive learning. Grounded in a systematic review and empirical studies with medical students, the findings show that VR and AR can reduce extraneous cognitive load and foster curiosity to enhance anatomy learning. Novel behavioral indicators of curiosity, such as movement patterns in VR, further enrich our understanding of immersive learning processes. The thesis also suggests a conceptual framework that unifies motivation and cognitive efficiency, offering both theoretical contributions and practical guidelines for educators and designers seeking to optimize XR-based learning.
Jury Members
- Pr. Fred PAAS – Erasmus University Rotterdam (Reviewer)
- Pr. Éric JAMET – Université Rennes 2 (Reviewer)
- Pr. Julie LEMARIÉ – Université de Toulouse (Examiner)
- Pr. Stéphanie FLECK – Université de Lorraine (Examiner)
- Dr. Julia CHATAIN – Singapore-ETH Centre (Examiner)
- Dr. Pierre-Yves OUDEYER – INRIA (Examiner)
- Pr. Hélène SAUZÉON – Université de Bordeaux (Supervisor)
- Pr. André TRICOT – Université Paul Valéry (Supervisor)
- Dr. Florian LARRUE – CATIE (Supervisor)
- Pr. Martin BERTAND – Hôpital Universitaire Nîmes (Invited Participant)
- Pr. Dominique LIGUORO – Hôpital Universitaire Bordeaux (Invited Participant)
By Matisse Poupard @matissepoupard7456
Publications and Manuscript: https://www.matissepoupard.com
MAGELLAN: Metacognitive predictions of learning progress guide autotelic LLM agents in large goal spaces
MAGELLAN addresses a key challenge in building open-ended, curiosity-driven LLM agents: when facing an infinite number of possible new skills or problems to learn, how should they decide what to practice? How can curriculum learning be automated to maximize learning efficiency with limited time and energy?
To solve this challenge, MAGELLAN augments LLM agents with a metacognition mechanism: the awareness of their own competence and learning progress. Just as humans reflect on what they know and what they should learn next, MAGELLAN enables LLM agents to monitor their own progress and make choices about which goals to pursue. This creates curious LLM agents that can explore and grow on their own, continuously expanding and self-improving their capabilities by understanding which goals will teach them the most at any given moment
Abstract : Computational approaches in social and human sciences (SHS) are reshaping how we model and evaluate complex phenomena such as learning and teaching processes. The multilevel and longitudinal nature of these processes necessitates a meticulous design of (behavioural) learning analytics, leveraging key indicators to enhance our understanding of human learning and teaching activities. In this presentation, I will discuss some of the challenges and opportunities in advancing computational learning sciences, drawing on a decade of research within the #CreaCube task and methodological framework for the study of Creative Problem Solving (CPS) in educational robotics.
Abstract : The internet has made information available at our fingertips at all times: Search engines, accessed via our computers, tablets, or smart phones, allow us to look up things whenever and wherever we want—an enhanced encyclopedia of factual knowledge. This pseudo-infinite space of immediately available knowledge has drastically reduced our need to learn and memorize facts. However, it has increased the urgency to know how to navigate this space effectively. This revolution, triggered by the era of globalization and digitalization, calls for a new science of learning, one that is more focused on how and what to learn—how to effectively ask questions and explore, which sources of information to trust and rely on, how to adapt one’s learning strategies to dynamic and multimodal learning environments, how to interpret the information collected, integrating them in one's existing body of knowledge—rather than on standard learning contents. This talk presents the results of recent studies investigating theoretically and empirically the emergence of these abilities, their developmental trajectory across childhood and the factors impacting their success.
Abstract : Recommender systems are key to present goods or educational resources in a personalized way. We will present some techniques we have developed to tweak the reward function of those systems in order to encourage diversity or optimize learning gains.
Abstract: Research on the development of curiosity has flourished in the past 15 years. For the most part that work either treats curiosity as a trait, or as a situational response occurring in a short period of time (an experimental session or two). However, at a surprisingly early age, children begin to pursue specific lines of inquiry over extended periods of time. During the same phase of development, children begin deliberately inventing solutions to problems that interest them. I will present recent data showing how children pursue ideas through inquiry and invention. I will also identify some methodological challenges of this kind of research and outline some possible solutions.
Title: Development and evaluation of AI-based personalization
algorithms for attention training
Abstract: Intelligent Tutoring Systems offer innovative educational solutions by providing
personalized learning experiences that adapt to individual variability. This adaptability is crucial
for tailoring curricula to maximize student engagement and learning outcomes. The Flowers team
(INRIA Bordeaux) has developed an ITS based on the Learning Progress Hypothesis (LP-H).
The LP-H suggests that individuals are intrinsically motivated to engage in learning activities
when they perceive their own progress. This perception of progress acts as an internal motivator,
encouraging them to pursue more activities where they can continue to make significant progress.
The system, named Zone of Proximal Development and Empirical Success (ZPDES), uses a
machine learning algorithm to customize learning trajectories by dynamically identifying and
exploiting activities that yield maximal learning progress, thereby enhancing student motivation.
The study of cognitive Training (CT), which involves structured tasks designed to improve
specific cognitive functions such as memory, attention, and problem-solving, reveals that the
benefits of CT are highly sensitive to inter-individual differences, highlighting the need for CT
personalization. In this context, our research explores the potential of applying the ZPDES
framework to CT to improve cognitive performance, engagement, and motivation.
Jury members:
Dr. Julien DIARD - Université Grenoble Alpes (Reviewer)
Dr. Walter R. BOOT - Weill Cornell Medicine (Reviewer)
Dr. Vanda LUENGO - Sorbonne Université (Examiner)
Dr. Claudia VON BASTIAN - University of Sheffield (Examiner)
Dr. Hélène SAUZEON - Université de Bordeaux (Supervisor)
Dr. Pierre-Yves OUDEYER - INRIA (Supervisor)
Dr. Alexandra DELMAS - Onepoint (Invited Participant)
Dr. Denis MAUREL - Onepoint (Invited Participant)
Title: Guiding the minds of tomorrow : conversational agents
to train curiosity and metacognition in young learners
Abstract: Curiosity is the drive to explore and learn for sheer joy. It plays a vital role in fostering autonomous and personalized lifelong learning. Yet, its implementation and promotion in today’s classrooms are still widely missing. In this context, this thesis aims to leverage new technologies and theories of curiosity-driven learning in cognitive sciences to design and implement educational tools that foster curiosity-driven learning in children. In particular, the thesis proposes online environments featuring interactions with conversational agents to train curiosity-related skills.
The trainings targeted three specific dimensions: I) improving children’s linguistic question-asking skills, II) teaching them to evaluate and monitor their own knowledge effectively (i.e., metacognitive strategies for learning), and II) eshaping the negative views they may have on curiosity.
Tested with more than 150 French school-students aged between 9 and 11, the interventions combined were successful in boosting students' metacognitive sensitivity and perception of curiosity. Together with the curiosity trait, these factors facilitated the divergent QA behaviors. The positive results motivate further research to build individualized interventions and to explore their long-term impact on curiosity, especially in the age of generative artificial intelligence.
Link to manuscript: https://theses.hal.science/tel-04697786/document
Link to associated publications: https://scholar.google.com/citations?user=L5WCl5MAAAAJ&hl=fr
Jury members:
Mrs. ROMERO, Margarida Pr.University of Côte d’Azur, Reviewer
Mrs. RUGGERI, Azzurra Pr.MPI Berlin, TU Munich & CEU Vienna, Reviewer
Mrs. JIROUT, Jamie PA University of Virginia, Examiner
Mrs. ENGEL, Susan Pr.Williams College, Examiner
Mr. VIE, Jill-Jênn CR Inria Saclay & École Polytechnique, Examiner
Mme SAUZÉON, Hélène PR Inria & University of Bordeaux, Supervisor
M. OUDEYER, Pierre-Yves DR Inria Bordeaux, Supervisor
La plupart des utilisations des modèles de langage aujourd’hui se font au travers d’une conversation avec l’utilisateur. Cette vidéo s’intéresse à la possibilité d’employer ces modèles en tant qu’agent autonome capables de résoudre une tâche donnée.
On étudie plus particulièrement le problème de l’ancrage, qui se résume à adapter les connaissances théoriques et livresques d’un modèle de langage au monde réel, afin qu’il puisse s’en servir en pratique.
Chapitres:
0:00 : Introduction
1:03 : Exemple
1:46 : Problème de l’ancrage
4:38 : GLAM = ancrage
10:11 : Les agents
11:35 : Conclusion
**** Série "ChatGPT en 5 minutes ****
Cette vidéo fait partie d'une mini-série présentant les modèles de langage (https://developmentalsystems.org/chatgpt_5_minutes/). Elle s'adresse à un public large, par exemple élèves et enseignants de collèges et lycées, et plus généralement aux non spécialistes de l'informatique ou de l'IA.
Autres épisodes:
- Comment fonctionne ChatGPT? Un tour d’horizon en moins de 5mn: https://www.youtube.com/watch?v=K8gOvC8gvB4
- Le prompting, ou l’art de se faire comprendre par ChatGPT: Explication en 5mn : https://www.youtube.com/watch?v=8IQ9i_QoA3A
- Quelles sont les limites de ChatGPT ? Explications en 5mn (stéréotypes, erreurs factuelles, ...): https://www.youtube.com/watch?v=xXHWTC4mJBM
- Les forces des modèles de langage: https://www.youtube.com/watch?v=5HVR3cVFot4
- Raisonnements avancés : https://www.youtube.com/watch?v=uLMqTPmvqPw
- Applications des modèles de langage : https://www.youtube.com/watch?v=E2hPk3adUlI
- Utilisation autonome d’outils : Faire manipuler des outils à ChatGPT : https://www.youtube.com/watch?v=gUn79szTWw0
**** Réalisation ****
Vidéo réalisée par l’équipe Flowers du centre Inria de l'Université de Bordeaux (https://flowers.inria.fr/ ), travaillant dans le domaine de l'IA développementale.
Les modèles de langage comme ChatGPT ou Gemini sont capables de réaliser une grande diversité de tâches pour répondre aux besoins de leur utilisateur. Afin de tirer une meilleure partie de leurs compétences, on peut leur faire manipuler des outils lors de la rédaction de leur réponse.
Dans cette vidéo, nous vous proposons de voir comment cette manipulation d’outils est possible et quelles utilisations celle-ci peut apporter à l’utilisation : recherche internet, exécution de code, etc.
**** Série "ChatGPT en 5 minutes ****
Cette vidéo fait partie d'une mini-série présentant les modèles de langage (https://developmentalsystems.org/chatgpt_5_minutes/fr/ ). Elle s'adresse à un public large, par exemple élèves et enseignants de collèges et lycées, et plus généralement aux non spécialistes de l'informatique ou de l'IA.
Autres épisodes:
- Comment fonctionne ChatGPT? Un tour d’horizon en moins de 5mn: • Comment fonctionne ChatGPT? Un tour d...
- Le prompting, ou l’art de se faire comprendre par ChatGPT: Explication en 5mn : • Le prompting, ou l’art de se faire co...
- Quelles sont les limites de ChatGPT ? Explications en 5mn (stéréotypes, erreurs factuelles, ...): • Quelles sont les limites de ChatGPT ?...
- Les forces des modèles de langage: • Les forces des modèles de langage
- Raisonnements avancés : https://www.youtube.com/watch?v=uLMqTPmvqPw
- Applications des modèles de langage : https://www.youtube.com/watch?v=E2hPk3adUlI
**** Réalisation ****
Vidéo réalisée par l’équipe Flowers du centre Inria de l'Université de Bordeaux (https://flowers.inria.fr/ ), travaillant dans le domaine de l'IA développementale.
This video introduces the notion of prompting, which allows to make a language model (for example #ChatGPT) performs a certain task, by explaining it through natural language. We see, through examples, two methods of prompting (explaining the task in natural language, and giving examples of how the task is accomplished).
We showcase a few example “prompts” corresponding to diverse usages, like generating questions to help students review or anticipate questions on a subject, or aiding in writing from notes.
Chapters:
0:00 : Introduction
0:18 : Prompting
1:17 : First method
1:36 : Second method
2:18 : Limits of prompting
3:37 : Conclusion
**** “ChatGPT explained in 5 minutes” series ****
This video is the second episode of a video series (http://developmentalsystems.org/chatgpt_5_minutes/en/) that presents language models. It is aimed at a large public, students and professors in middle and high school, and more generally anyone not accustomed to computer science or AI.
The other videos of the series :
- How does ChatGPT work? A 5-minute overview : https://youtu.be/YXT6mFjInaU
- What are the limitations of ChatGPT ? A 7-minute explanation (stereotypes, factual errors, etc.) : https://youtu.be/7FB1OWPCeyM
- Strengths of language models : COMING SOON
- Advanced prompting, chain of thought reasoning and their limits : COMING SOON
**** Production ****
This video was made by the Inria Flowers team, working in the domain of developmental AI : https://flowers.inria.fr/
The voice was synthesized using ElevenLabs (elevenlabs.io).
This video showcases the major limitations and weaknesses of language models.
Language models, like #ChatGPT or #Bard, have shown significant capacities for diverse tasks (see the first video of the series). However, they do have many limitations and weaknesses ! In this video, we focus on the main ones :
- these models are trained with data whose quality and origin can be variable. The choice of this data is often not very monitored.
- this data, and thus language models, can express “bias”, which is an automatic way of thinking, which does not rely on any reasoning nor any facts. These biases are unjust and can reinforce stereotypes. If they are not controlled, they will be present in the productions and usages that these language models take part in.
- difficulty to trace back the source of information : a specific piece of knowledge expressed by a model cannot be traced back to the corresponding training data.
- the training of these giant models requires vast amounts of data and compute
- their productions can contain factual errors, or even made up facts (we talk about “hallucinations”).
- especially, these models haven’t learned through physical interaction as human do, they can thus make elementary errors about the understanding of the physical world, or more generally common sense (we talk about the “grounding problem”)
- the answers of these language models often have a ton resembling one of an expert, absolutely certain of its knowledge. Their responses are often so credible that it is easy to believe that these models have an intention, and that they took into account the human they are speaking with to create their answer, which is not the case.
- models like ChatGPT or Bard are owned and controlled by private actors : not much information about how they work is available, as for example the way the training data was selected.
Chapters:
0:00 : Introduction
0:41 : Bias and alignment
2:10 : Frozen knowledge
2:34 : Inability to provide sources
3:05 : Data quantity
4:17 : Hallucinations
4:56 : Lack of practical understanding
5:56 : Interpretation we make of it
6:25 : Conclusion
**** “ChatGPT explained in 5 minutes” series ****
This video is the third episode of a video series (http://developmentalsystems.org/chatgpt_5_minutes/en/) that presents language models. It is aimed at a large public, students and professors in middle and high school, and more generally anyone not accustomed to computer science or AI.
The other videos of the series :
- How does ChatGPT work? A 5-minute overview : https://www.youtube.com/watch?v=YXT6mFjInaU
- Prompting, or the art of making yourself understood by ChatGPT : https://youtu.be/AscZJQBot2I
- Strengths of language models : COMING SOON
- Advanced prompting, chain of thought reasoning and their limits : COMING SOON
**** Production ****
This video was made by the Inria Flowers team, working in the domain of developmental AI : https://flowers.inria.fr/
The voice was synthesized using ElevenLabs (elevenlabs.io).
Dans cette vidéo, nous vous proposons d’étudier les applications possibles de ces outils dans des domaines comme le travail, la santé, l’éducation ou encore la préservation de langues.
**** Série "ChatGPT en 5 minutes ****
Cette vidéo fait partie d'une mini-série présentant les modèles de langage (https://developmentalsystems.org/chatgpt_5_minutes/fr/ ). Elle s'adresse à un public large, par exemple élèves et enseignants de collèges et lycées, et plus généralement aux non spécialistes de l'informatique ou de l'IA.
Autres épisodes:
- Comment fonctionne ChatGPT? Un tour d’horizon en moins de 5mn: https://www.youtube.com/watch?v=K8gOvC8gvB4
- Le prompting, ou l’art de se faire comprendre par ChatGPT: Explication en 5mn: https://www.youtube.com/watch?v=8IQ9i_QoA3A
- Quelles sont les limites de ChatGPT ? Explications en 5mn (stéréotypes, erreurs factuelles, ...): https://www.youtube.com/watch?v=xXHWTC4mJBM
- Les forces des modèles de langage: https://www.youtube.com/watch?v=5HVR3cVFot4
- Raisonnements avancés : https://www.youtube.com/watch?v=uLMqTPmvqPw
- Faire manipuler des outils à ChatGPT : https://www.youtube.com/watch?v=gUn79szTWw0
**** Réalisation ****
Vidéo réalisée par l’équipe Flowers du centre Inria de l'Université de Bordeaux (https://flowers.inria.fr/ ), travaillant dans le domaine de l'IA développementale.
This video is an introduction to large language models which are the basis for tools like ChatGPT or Bard. It gives a 5-minute overview answering these questions:
- How are these models “trained”?
- On which type and amount of data are they trained, and what is the impact of the size of the training corpus?
- Which types of tasks are they capable of doing, and how can we ask them to perform those tasks?
- What are their main usages in society?
- What are their limitations and biases? What social issues?
- Which organizations develop these models? Are there “open-sourced” ones?
Chapters:
0:00 : Introduction
0:20 : Language model
1:15 : Training
2:44 : A personality ?
3:43 : Limits of their knowledge
4:06 : Hallucinations
4:23 : Limits
4:42 : Applications
5:01 : Private actors
**** “ChatGPT explained in 5 minutes” series ****
This video is the first episode of a video series (http://developmentalsystems.org/chatgpt_en_5_minutes/) that presents language models. It is aimed at a large public, students and professors in middle and high school, and more generally anyone not accustomed to computer science or AI.
The other videos of the series :
- What are the limitations of ChatGPT ? : COMING SOON
- Prompting, or the art of making yourself understood by ChatGPT : COMING SOON
- Strengths of language models : COMING SOON
- Advanced prompting, chain of thought reasoning and their limits : COMING SOON
**** Production ****
This video was made by the Inria Flowers team, working in the domain of developmental AI : https://flowers.inria.fr/
Les modèles de langage comme ChatGPT ou Bard sont capables de tenir des raisonnements simples pour résoudre un problème donné. Cependant, il est parfois nécessaire d'avoir recours à différentes techniques de prompting avancé pour les aider à organiser de tels raisonnements.
Dans cette vidéo, nous verrons quelques unes de ces techniques (par exemple les chaînes de pensées) et discuterons de l'origine et des limites de ces capacités à raisonner.
Chapitres:
0:00 : Introduction
0:23 : Des raisonnements ?
1:03 : Chaîne de pensée
5:18 : Provenance des capacités
6:57 : Limites : planification
8:45 : Limites des chaînes de pensée
9:52 : Conclusion
***** Série "ChatGPT en 5 minutes *****
Cette vidéo fait partie d'une mini-série présentant les modèles de langage (http://developmentalsystems.org/chatgpt_en_5_minutes/ ). Elle s'adresse à un public large, par exemple élèves et enseignants de collèges et lycées, et plus généralement aux non spécialistes de l'informatique ou de l'IA.
Autres épisodes:
- Comment fonctionne ChatGPT? Un tour d’horizon en moins de 5mn: https://www.youtube.com/watch?v=K8gOvC8gvB4
- Le prompting, ou l’art de se faire comprendre par ChatGPT: Explication en 5mn : https://www.youtube.com/watch?v=8IQ9i_QoA3A
- Quelles sont les limites de ChatGPT ? Explications en 5mn (stéréotypes, erreurs factuelles, ...): https://www.youtube.com/watch?v=xXHWTC4mJBM
- Les forces des modèles de langage: https://www.youtube.com/watch?v=5HVR3cVFot4
***** Réalisation *****
Vidéo réalisée par l’équipe Flowers du centre Inria de l'Université de Bordeaux (https://flowers.inria.fr/ ), travaillant dans le domaine de l'IA développementale.
Capturing Intelligence at the Level of Thought
James L. McClelland, Stanford University and Google DeepMind
Today’s neural networks tantalize us with their apparent creativity and insight, yet we may also feel that they aren’t really thoughtful cognizing minds like those of ourselves and our peers. What’s the difference? I have come to feel that it may be useful to think that these systems don’t really have thoughts in the same sense that we do. Thus, I have set out on a quest to think about how we might better build model systems that can capture intelligence at the level of thought. In this talk I’ll describe what I mean by a thought, how it is that I see these systems as failing to operate at the level of thought, and some steps I and others are taking that I see as working toward the goal of understanding how to solve this interesting and challenging problem at the intersection of the sciences of mind, brain, and computation
00:00 Introduction by Pierre-Yves Oudeyer
06:24 Talk by James McClelland
01:07:15 Questions
Cette vidéo présente les principales forces des modèles de langage tels que ChatGPT ou Bard. En dépit de certaines faiblesses (abordées dans la vidéo https://www.youtube.com/watch?v=xXHWTC4mJBM), ils possèdent également un grand nombre de forces telles que:
- leur capacité à analyser un contexte donné pour fournir une réponse adaptée à une tâche
- leur utilisation d'outils externes (par exemple Wikipedia)
- la grande diversité des données sur lesquelles ils ont été entraîné
- leur capacité à produire des raisonnements basiques
- leur "sens commun" dans certains contextes
- leur capacité à nous aider à trouver des idées créatives
Chapitres:
0:00 : Introduction
0:25 : Très bonne analyse du contexte
1:58 : Utilisation d'outils
3:07 : Capacité de généralisation
4:18 : Données riches et diverses
5:03 : Raisonnements basiques
6:03 : Sens commun
6:54 : Hallucinations = créativité
7:10 : Conclusion
***** Série "ChatGPT en 5 minutes *****
Cette vidéo fait partie d'une mini-série présentant les modèles de langage (http://developmentalsystems.org/chatgpt_en_5_minutes/). Elle s'adresse à un public large, par exemple élèves et enseignants de collèges et lycées, et plus généralement aux non spécialistes de l'informatique ou de l'IA.
Autres épisodes:
- Comment fonctionne ChatGPT? Un tour d’horizon en moins de 5mn: https://www.youtube.com/watch?v=K8gOvC8gvB4
- Le prompting, ou l’art de se faire comprendre par ChatGPT: Explication en 5mn : https://www.youtube.com/watch?v=8IQ9i_QoA3A
- Quelles sont les limites de ChatGPT ? Explications en 5mn (stéréotypes, erreurs factuelles, ...): https://www.youtube.com/watch?v=xXHWTC4mJBM
- Prompting avancé et raisonnements: https://www.youtube.com/watch?v=uLMqTPmvqPw
***** Réalisation *****
Vidéo réalisée par l’équipe Flowers du centre Inria de l'Université de Bordeaux (https://flowers.inria.fr/ ), travaillant dans le domaine de l'IA développementale.
Presentation at the Collas 2023 conference of the paper "Autotelic reinforcement learning in multi-agent environments"
by Eleni Nisioti*, Elias Masquil* (presenter), Gautier Hamon* and Clément Moulin-Frier.
(*) Co-first authors
- Paper: https://arxiv.org/abs/2211.06082
Abstract:
In the intrinsically motivated skills acquisition problem, the agent is set in an environment without any pre-defined goals and needs to acquire an open-ended repertoire of skills. To do so the agent needs to be autotelic (deriving from the Greek auto (self) and telos (end goal)): it needs to generate goals and learn to achieve them following its own intrinsic motivation rather than external supervision. Autotelic agents have so far been considered in isolation. But many applications of open-ended learning entail groups of agents. Multi-agent environments pose an additional challenge for autotelic agents: to discover and master goals that require cooperation agents must pursue them simultaneously, but they have low chances of doing so if they sample them independently. In this work, we propose a new learning paradigm for modeling such settings, the Decentralized Intrinsically Motivated Skills Acquisition Problem (Dec-IMSAP), and employ it to solve cooperative navigation tasks. First, we show that agents setting their goals independently fail to master the full diversity of goals. Then, we show that a sufficient condition for achieving this is to ensure that a group aligns its goals, i.e., the agents pursue the same cooperative goal. Our empirical analysis shows that alignment enables specialization, an efficient strategy for cooperation. Finally, we introduce the Goal-coordination game, a fully-decentralized emergent communication algorithm, where goal alignment emerges from the maximization of individual rewards in multi-goal cooperative environments and show that it is able to reach equal performance to a centralized training baseline that guarantees aligned goals. To our knowledge, this is the first contribution addressing the problem of intrinsically motivated multi-agent goal exploration in a decentralized training paradigm.
Recent works successfully leveraged Large Language Models' (LLM) abilities to capture abstract knowledge about world's physics to solve decision-making problems. Yet, the alignment between LLMs' knowledge and the environment can be wrong and limit functional competence due to lack of grounding.
In this paper, we study an approach (named GLAM) to achieve this alignment through functional grounding: we consider an agent using an LLM as a policy that is progressively updated as the agent interacts with the environment, leveraging online Reinforcement Learning to improve its performance to solve goals.
Using an interactive textual environment designed to study higher-level forms of functional grounding, and a set of spatial and navigation tasks, we study several scientific questions:
1) Can LLMs boost sample efficiency for online learning of various RL tasks? 2) How can it boost different forms of generalization?
3) What is the impact of online learning? We study these questions by functionally grounding several variants (size, architecture) of FLAN-T5.
Les modèles de langage, comme ChatGPT ou Bard, on montré des capacités impressionnantes pour des tâches très variées (voir vidéo 1 de la mini-série). Cependant, ils ont aussi de nombreuses limites et faiblesses ! Dans cette vidéo, nous expliquons les principales:
- les modèles de langage sont entraînés à partir de données dont la qualité et l'origine peut être très variable. Le choix de ces données n'est souvent pas précisément contrôlé.
- ces données, et donc les modèles de langage, peuvent contenir "biais", c’est-à-dire une manière de penser automatique, qui ne repose pas sur un raisonnement ou sur des faits. Ces biais peuvent être injustes et renforcer des stéréotypes. Ces biais, s’ils ne sont pas contrôlés, seront alors répercutés dans les productions et les usages que l’on fait de ces modèles.
- difficultés pour tracer les sources d'information: les connaissances exprimées par un modèle de langage ne peuvent être tracées, remontées à sa source de données correspondante dans le corpus d’entraînement du modèle.
- l'entrainement de ces modèles nécessite de quantités gigantesque de données et de calcul
- leurs productions peuvent contenir des erreurs factuelles, et parfois même "inventer" complètement des faits ou des raisonnements (on parle d'"hallucinations").
- en particulier, ces modèles n'ont pas appris en étant connectés au monde physique et peuvent faire des erreurs élémentaires de compréhension du monde physique, ou plus généralement de sens commun (en anglais, on parle de "grounding problem")
- les productions des modèles de langage ont souvent un ton qui ressemble à celui d'un expert sûr de ses connaissances: leurs réponses sont en apparence parfois si crédibles et développées qu’il est facile pour un humain d’associer au modèle une intention, et de penser que le modèle a construit sa réponse dans un processus prenant en compte l’humain à qui il parle, ce qui n’est pas le cas.
- Les modèles comme ChatGPT ou Bard sont contrôlés par des acteur privés, et peu d'informations concernant leur fonctionnement, par exemple la manière dont ils traitent quelles données, ne sont pas disponibles.
Cette vidéo présente les limites et faiblesses majeures des modèles de langage tels que ChatGPT ou Bard.
Chapitres:
0:00 : Introduction
0:34 : Biais et alignement
1:56 : Connaissances statiques
2:24 : Impossible de donner les sources
2:55 : Quantité de données
4:02 : Hallucinations
4:36 : Absence de compréhension pratique
5:33 : Interprétation
5:56 : Conclusion
***** Série "ChatGPT en 5 minutes *****
Cette vidéo fait partie d'une mini-série présentant les modèles de langage (http://developmentalsystems.org/chatgpt_en_5_minutes/ ). Elle s'adresse à un public large, par exemple élèves et enseignants de collèges et lycées, et plus généralement aux non spécialistes de l'informatique ou de l'IA.
Autres épisodes:
- Comment fonctionne ChatGPT? Un tour d’horizon en moins de 5mn: https://www.youtube.com/watch?v=K8gOvC8gvB4
- Le prompting, ou l’art de se faire comprendre par ChatGPT: Explication en 5mn : https://www.youtube.com/watch?v=8IQ9i_QoA3A
- Les forces des modèles de langage: https://www.youtube.com/watch?v=5HVR3cVFot4
- Prompting avancé et raisonnements: https://www.youtube.com/watch?v=uLMqTPmvqPw
***** Réalisation *****
Vidéo réalisée par l’équipe Flowers du centre Inria de l'Université de Bordeaux (https://flowers.inria.fr/ ), travaillant dans le domaine de l'IA développementale.
Présentation des activités de recherche de l'équipe Flowers par Hélène Sauzéon et Clément Moulin-Frier
Résumé :
Les algorithmes de curiosité artificielle permettent aux machines (ordinateurs, robots) d'explorer efficacement des environnements inconnus afin d'apprendre, de façon autonome, un ensemble de compétences les plus diverses possible. Mais à quoi cela peut-il bien servir concrètement ? Pour répondre à cette question, des contributions récentes de l'équipe Flowers seront présentées en intelligence et vie artificielle, ainsi que dans les technologies pour l'éducation.
Cette vidéo introduit la notion de prompting, qui permet de faire réaliser une certaine tâche à un modèle de langage (par exemple #ChatGPT) en lui expliquant cette tâche au moyen de phrases en langage naturel. On y voit, au travers d’exemples, deux méthodes de prompting (expliquer la tâche en langage naturel, et donner des exemples de réalisation de la tâche).
Quelques exemples de "prompts" correspondant à des usages divers sont présentés, comme la génération de questions pour aider des élèves à réviser ou à anticiper des questions sur un sujet, ou l'aide à la rédaction à partir de notes.
Chapitres:
0:00 : Introduction
0:18 : Le principe du prompting
1:10 : Première méthode
1:28 : Seconde méthode
2:07 : Limites du prompting
3:00 : Conclusion
***** Série "ChatGPT en 5 minutes *****
Cette vidéo fait partie d'une mini-série présentant les modèles de langage (http://developmentalsystems.org/chatgpt_en_5_minutes/ ). Elle s'adresse à un public large, par exemple élèves et enseignants de collèges et lycées, et plus généralement aux non spécialistes de l'informatique ou de l'IA.
Autres épisodes:
- Comment fonctionne ChatGPT? Un tour d’horizon en moins de 5mn: https://www.youtube.com/watch?v=K8gOvC8gvB4
- Quelles sont les limites de ChatGPT ? Explications en 5mn (stéréotypes, erreurs factuelles, ...): https://www.youtube.com/watch?v=xXHWTC4mJBM
- Les forces des modèles de langage: https://www.youtube.com/watch?v=5HVR3cVFot4
- Prompting avancé et raisonnements: https://www.youtube.com/watch?v=uLMqTPmvqPw
***** Réalisation *****
Vidéo réalisée par l’équipe Flowers du centre Inria de l'Université de Bordeaux (https://flowers.inria.fr/ ), travaillant dans le domaine de l'IA développementale.
Cette vidéo est une introduction aux modèles de langage, qui sont à la base d’outils comme #chatgpt ou Bard. Elle s'adresse à un public large (par exemple élèves et enseignants de collèges et lycées, et plus généralement aux non spécialistes de l'informatique ou de l'IA).
En 5mn, elle fait un tour d'horizon des questions suivantes:
- Comment ces modèles sont-ils "entraînés" ?
- Sur quelle type et quelle quantité de textes sont-ils entraînés, et quel est l'impact de la taille de ces corpus d'entraînement ?
- Quelles types de tâches sont-ils capables de réaliser, et comment peut on leur demander de réaliser ces tâches ?
- Quelles sont leurs applications ?
- Quelles sont leurs limites et leurs biais ? Quels enjeux sociétaux ?
- Quelles organisations développent ces modèles ? Certains sont ils "open-source" ?
Chapitres:
0:00 : Introduction
0:23 : Modèle de langage
1:08 : L'entraînement
2:45 : Une personnalité ?
3:27 : Limites sur les connaissances
3:47 : Hallucinations
3:55 : Limites
4:15 : Applications
4:35 : Acteurs privés
***** Série "ChatGPT en 5 minutes *****
Cette vidéo fait partie d'une mini-série présentant les modèles de langage (http://developmentalsystems.org/chatgpt_en_5_minutes/ ). Elle s'adresse à un public large, par exemple élèves et enseignants de collèges et lycées, et plus généralement aux non spécialistes de l'informatique ou de l'IA.
Autres épisodes:
- Le prompting, ou l’art de se faire comprendre par ChatGPT: Explication en 5mn : https://www.youtube.com/watch?v=8IQ9i_QoA3A
- Quelles sont les limites de ChatGPT ? Explications en 5mn (stéréotypes, erreurs factuelles, ...): https://www.youtube.com/watch?v=xXHWTC4mJBM
- Les forces des modèles de langage: https://www.youtube.com/watch?v=5HVR3cVFot4
- Prompting avancé et raisonnements: https://www.youtube.com/watch?v=uLMqTPmvqPw
***** Réalisation *****
Vidéo réalisée par l’équipe Flowers du centre Inria de l'Université de Bordeaux (https://flowers.inria.fr/ ), travaillant dans le domaine de l'IA développementale.
This PhD thesis was defended at Inria/University of Bordeaux in 2022.
The Role of Progress-Based Intrinsic Motivation in Learning : Evidence from Human Behavior and Future Directions, by Alexandr Ten
Pdf of manuscript: https://www.theses.fr/2022BORD0152
=== Related papers:
Ten, A., Kaushik, P., Oudeyer, P. Y., & Gottlieb, J. (2021). Humans monitor learning progress in curiosity-driven exploration. Nature communications, 12(1), 1-10. https://www.nature.com/articles/s41467-021-26196-w
Ten, A., Gottlieb, J., & Oudeyer, P. Y. (2021). Intrinsic rewards in human curiosity-driven exploration: An empirical study. In Proceedings of the Annual Meeting of the Cognitive Science Society (Vol. 43, No. 43). https://escholarship.org/uc/item/13b6p5ms
Ten, A., Oudeyer, P. Y., & Moulin-Frier, C. (2022). Curiosity-Driven Exploration: : Diversity of mechanisms and functions? The Drive for Knowledge: The Science of Human Information Seeking, 53.
https://hal.inria.fr/hal-03447896/file/Ten2022Curiosity-driven.pdf
=== Abstract of manuscript
Intrinsic motivation – the desire to do things for their inherent joy and pleasure – has received its first share of scientific attention over 70years ago, ever since we saw monkeys solving puzzles for free. Since then, research on intrinsic motivation has been steadily gaining momentum. We have come to understand, in the context of learning and discovery, that intrinsic motivation (namely, intrinsically motivated information-seeking) is foundational for the biological and technological success of our species. But where does intrinsic motivation to learn and seek information come from? Today, with the thriving synergy between perpetually advancing fields of psychology, neuroscience, and computer science, we are well positioned to investigate this question.
The Learning Progress Hypothesis (LPH) proposes that humans are motivated by feelings of and/or beliefs about progress in knowledge (including progress in competence). In artificial learners, progressbased intrinsic motivation enables autonomous exploration of the environment (including the agent’s own body), resulting in better performance, more efficient learning, and richer skill sets. Due to similar computational challenges facing artificial and biological learners, researchers have proposed that progress-based intrinsic motivation might have evolved in humans to help us transition from babies with few skills and little knowledge to knowledgeable grownups capable of performing many sophisticated tasks. The Learning Progress Hypothesis (LPH) is attractive, not only because it is consistent with several studies of human curiosity, but also because it resonates with existing theories on metacognitive self-regulation in learning. However, the LPH has not been extensively studied using behavioral experimentation.
This thesis provides an empirical examination of the LPH. We introduce a novel experimental paradigm where participants explore multiple learning activities, some easy, others difficult. The activities involve guessing the binary category of randomly presented stimuli. To let their intrinsic motivation shine, we did not provide any material incentives encouraging specific behaviors or strategies – we simply observed which activities people engaged in and how their knowledge about these activities unfolded over time. We present statistical analyses and a computational model that support the LPH.
This thesis also suggests ideas for future investigations into progressbased motivation. These ideas are inspired by a pilot study in which we asked participants to practice a naturalistic sensorimotor skill (a video game) over the course of 3 sessions spanning 5 days. At the end of each session, participants reported their subjective judgments of past and future progress, as well as their evolving beliefs about their perceived competence, self-efficacy beliefs, and intrinsic motivation. In support of the LPH, participants’ subjective judgments correlated with the objective improvement. However, contrary to the LPH’s prediction, objective and subjective progress measures did not show reliable rela- tionships with verbal and behavioral measures of intrinsic motivation. Instead, progress measures were in strong relationships with beliefs about task learnability, which in turn predicted intrinsic motivation. Based on these findings, we suggest a novel mechanism in which learning progress interacts with intrinsic motivation via subjective beliefs.
We conclude the thesis with an extended discussion of our findings, where we examine some limitations of our experiments and propose promising future steps. In summary, we believe the behavioral paradigms introduced in this thesis should be reused to not only replicate our results, but also to advance the scientific research of intrinsically motivated information-seeking.
Mini-workshop between the PACEA laboratory (University of Bordeaux) and the Flowers team at Inria.
The aim of the workshop is to discuss potential convergence of ideas between two scientific fields that rarely interact together: Artificial Intelligence (represented by the Flowers team) and Archeology (represented by the PACEA lab).
We believe that these two fields can mutually benefit from such an interdisciplinary interaction. In particular, they share some hypotheses on e.g. the role of environmental variability in the evolution of generalist behavior [1] ; as well as on the role of cultural knowledge in open-ended skill acquisition [2].
00:00 Pierre-Yves Oudeyer (Flowers) -- Introduction on the Flowers team
25:10 Francesco d'Errico (PACEA) -- What we know and don't know about human cultural evolution over the last 300.000 years
1:15:55 Clément Moulin-Frier (Flowers) -- Introduction on the ORIGINS project (Inria Exploratory Action): Grounding AI in the origins of human behavior
1:59:40 Luc Doyon (PACEA) -- Pleistocene osseous technologies: Can AI help Archaeology in resolving key issues on cultural evolution dynamics in our lineage?
2:36:51 Daniel Pereira (PACEA) -- Contact networks 10,000 years ago in the western Mediterranean
3:16:40 Eleni Nisioti (Flowers) -- Computational experiments on the role of environmental and social dynamics in adaptability and cultural innovation
3:54:55 Tristan Karch (Flowers) -- Language as a cognitive tool to imagine goals in curiosity-driven exploration
Kids Ask" is a project that aims to design innovative educational technologies that can stimulate and support the epistemic curiosity of young learners and that leverage the social benefits of using artificial conversational agents.
Link for the IJHCS paper : https://www.sciencedirect.com/science/article/pii/S1071581922001112
Team meeting presentation in the Inria Flowers team by Masataka Sawayama on 14th April 2022. He introduced his research to be presented at ICLR 2022, entitled "Language-biased image classification: evaluation based on semantic representations."
The paper information is as follows:
Paper: https://arxiv.org/abs/2201.11014
OpenReview: https://openreview.net/forum?id=xNO7OEIcJc6
Code: https://github.com/flowersteam/picture-word-interference
Lemesle*, Y., Sawayama*, M., Valle-Perez, G., Adolphe, M., Sauzéon, H., & Oudeyer, P. Y. (2022). Language-biased image classification: evaluation based on semantic representations. In International Conference on Learning Representations (ICLR 2022). *equal contribution
[Abstract]
Humans show language-biased image recognition for a word-embedded image, known as picture-word interference. Such interference depends on hierarchical semantic categories and reflects that human language processing highly interacts with visual processing. Similar to humans, recent artificial models jointly trained on texts and images, e.g., OpenAI CLIP, show language-biased image classification. Exploring whether the bias leads to interference similar to those observed in humans can contribute to understanding how much the model acquires hierarchical semantic representations from joint learning of language and vision. The present study introduces methodological tools from the cognitive science literature to assess the biases of artificial models. Specifically, we introduce a benchmark task to test whether words superimposed on images can distort the image classification across different category levels and, if it can, whether the perturbation is due to the shared semantic representation between language and vision. Our dataset is a set of word-embedded images and consists of a mixture of natural image datasets and hierarchical word labels with superordinate/basic category levels. Using this benchmark test, we evaluate the CLIP model. We show that presenting words distorts the image classification by the model across different category levels, but the effect does not depend on the semantic relationship between images and embedded words. This suggests that the semantic word representation in the CLIP visual processing is not shared with the image representation, although the word representation strongly dominates for word-embedded images.